第一步:配置Hadoop环境变量
首先需要Hadoop的环境变量
输入命令:vim /etc/profile并按回车进入配置文件,如下图所示,添加的内容是下面红色圈住的内容。
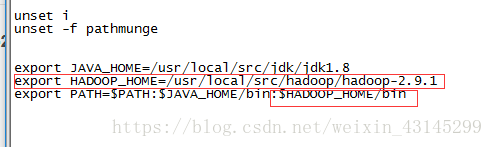
然后输入命令source /etc/profile来使配置起作用。
第二步:初始化
接下来开始初始化HDFS(格式化文件系统),格式化之前hadoop2.9.1目录是没有tmp这个目录的。
输入命令hdfs namenode -format 来格式化,格式化完之后如果从信息中看到如下红色圈住的内容说明格式化成功了!
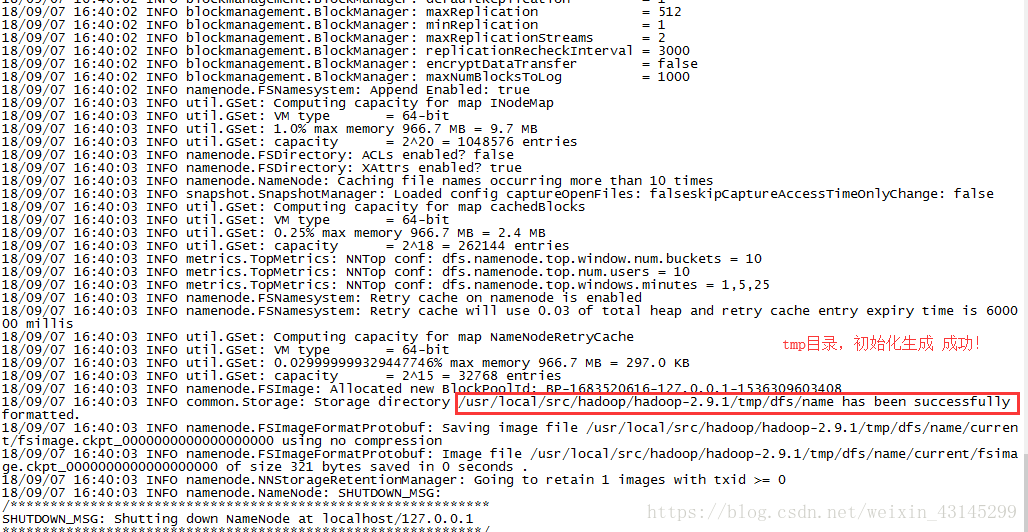
格式化之后hadoop2.9.1目录也就有了tmp这个目录了。
第三步:启动Hadoop
在hadoop安装目录的sbin目录下执行格式化命令!
cd /usr/local/src/hadoop/hadoop-2.9.1/sbin
start-dfs.sh
start-yarn.sh

启动hadoop
第四步:查看进程
启动完两个脚本之后,来看一下java process snapshot(jps),发现有6个进程,其中NameNode是HDFS的老大,DataNode是HDFS的小弟,ResourceManager是YARN的老大,NodeManager是YARN的小弟,另外SecondaryNameNode是HDFS的NameNode的助理帮助NameNode完成一些数据的同步,主要用来合并fsimage和edits文件等。这说明前一节配置的完全正确,一次性启动成功!
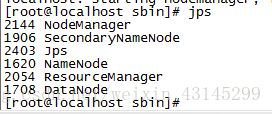
第五步:浏览器验证
浏览器访问:
192.168.93.128:50070
192.168.93.128:8088
在windows系统中绑定Linux主机名和之后
修改C:\Windows\System32\drivers\etc下的host文件
访问形式:
mrzhang:50070
mrzhang:8088端口
第六步:测试HDFS
1.上传文件到HDFS
hadoop fs -put /root/jdk-7u60-linux-x64.tar hdfs://mrzhang:9090/jdk
2.从HDFS下载文件到根目录home下的jdk1.7
hadoop fs -get hdfs://mrzhang:9090/jdk /home/jdk1.7
3.查看上传到hdfs的文件,最后的/不能省了。。。。
hadoop fs -ls hdfs://mrzhang:9090/
第七步:测试MR和YARN
1.首先linux本身提供一个命令wc,用来统计出现的单词,举例如下
words.txt文件内容如下
hello tom
hello jerry
hello kitty
hello world
hello tom
命令行输入wc words.txt出现如下结果
5 10 57 words.txt
意思分别是5行,10个单词,57个字母
2.下面是利用hadoop的MR自带的wordcount计算
在/hadoop/hadoop-2.9.1/share/hadoop/mapreduce这个目录下输入命令
hadoop jar hadoop-mapreduce-examples-2.9.1.jar wordcount hdfs://mrzhang:9090/words.txt hdfs://mrzhang:9090/wcout
hadoop jar hadoop-mapreduce-examples-2.9.1.jar wordcount –>这个是调用hadoop下的jar包命令
然后要跟一个输入in和一个输出out
输入in放的就是要计算的那个文件
输出out到wcout文件,然后运行即可