因为想用Kaldi去实现一个GMM-UBM的说话人识别和loglike打分,所以想把Kaldi计算的统计量对一对,
看能不能把二进制文件里的数值单独拿出来,自己写个代码做结合Kaldi中的MAP做统计量计算,然后再放回去。
但是当把训练好的UBM打开看看,发现他的矩阵不是人们常说的
MFCC生成的特征向量是39维而是60维,所以特意返回去再把MFCC和信号处理给梳理一遍。
并且把kaldi跟特征有关的,维度有关都调查了一遍。
当用下面的命令打开 训练好的UBM后,把它存在final_dubm.txt中
gmm-global-copy --binary=false final.dubm final_dubm.txt
顺路说说,为什么用diag的ubm而不是full的ubm是因为一下这个paper说
1。因为高维FUll相当于更高维度的DIAG协方差矩阵
2。DIAG协方差矩阵计算速度更快,因为假设特征之间没有相关性,相互独立
3。DIAG协方差的效果好过FULL
回正题,打开之后就看Mean_InVar那一个矩阵,会发现每一个高斯分量,他都有60维, 如图所示。

这个常识中的我的理解D=39维有点出入,这是为什么呢?因为我跑的demo主动设置了MFCC的配置。
然后打开 v1/conf/mfcc.conf 会发现:(以前没有特别想法去看CONF,发现这些个配置文件都还蛮重要的)
--sample-frequency=16000 --num-mel-bins=40 #higher than the default which is 23 --num-ceps=20 # higher than the default which is 12.
这里配置设置了有40个MEL三角形滤波器,有20个梅尔系数,delta3次后得到20*3=60
啥是delta?
标准的倒谱参数MFCC只反映了语音参数的静态特性,语音的动态特性可以用这些静态特征的差分谱即delta来描述。实验证明:把动、静态特征结合起来才能有效提高系统的识别性能。一般会有2个delta,加上原来的就是20*3
因为做MFCC时一般会取40个滤波器使原始声音变成梅尔刻度(听觉音高单位),梅尔刻度是一种基于人耳对等距的音高变化的感官判断而定的非线性m刻度。
然后因为MFCC 最后一步式DCT,所以DCT的结果也是40个点;实际中,一般仅保留前13~20个,这就进一步压缩了数据。得到梅尔倒谱。
为了进一步验证呢,我们用原数据MFCC,并把MFCC的管道ark结果打开看看维度!
steps/make_mfcc.sh --cmd "$train_cmd" --nj 10 data/train exp/make_mfcc/train $mfccdir
copy-feats ark:raw_mfcc_train.7.ark ark,t:- | less
打开得到该图,行是一条语音有多少帧的帧数,每行有20列

MFCC特征提取的步骤:
1.预加重:
语音信号,因为声门气流波的影响,每倍频衰减12dB,唇腔辐射使每倍频增加6dB,抵消后总的每倍频衰减6dB,将语音信号通过高通滤波器,提升高频部分使高频和低频相等,来消除发声过程中声带和嘴唇的影响,补偿语音信号收到发音系统所抑制的高频部分,突出了高频的共振峰。 Y[n]=s[n]-0.95*s[n-1].
2.分帧:
因为语音信号是快速变化的,而 fourier tansform 适用于分析平稳的信号,利用语音的短时平稳性(在每一时刻所有阶差分都是一样的),在语音识别中一般去帧长为20ms~50ms(一般取25ms),这样一帧内既有足够多的周期,又不会变化很剧烈, 一般帧移取10ms, 也就是说帧与帧之间有15ms是重复的,(s - 15)/ 10 = 帧数, 其中 s 为一段语音的毫秒数.
先将N个采样点集合成一个观测单位,称为帧。通常情况下N的值为256或512,涵盖的时间约为20~30ms左右。为了避免相邻两帧的变化过大,因此会让两相邻帧之间有一段重叠区域,此重叠区域包含了M个取样点,通常M的值约为N的1/2或1/3。通常语音识别所采用语音信号的采样频率为8KHz或16KHz,以8KHz来说,若帧长度为256个采样点,则对应的时间长度是256/8000 1000=32ms。
3.加窗:
因为之后要做FFT,而一个信号的FFT与 这个信号的周期信号的FFT相同,所以如果这个信号边缘不平话,那么这个信号的周期信号在显示中式很少遇到的,就没有意义了,所以每frame的信号有余一个平滑的窗函数相乘,让frame两端平滑的衰减到零,取得更高质量的频谱,常选用的窗函数: Hamming window,Hanning window。好的窗函数也能减弱频谱泄漏:
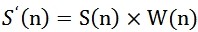
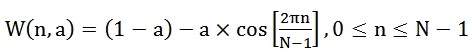
4.补零:
因为做FFT(快速傅里叶变化)要求信号长度为2^n,所以如果采样率为16000Hz,16000*0.025=400,要补0使长度为512。
5.快速傅里叶变换:
将时域谱转化为频率谱,纵坐标变为能量。fourier transform逐帧进行的,为的是取得每一帧的频谱。一般只保留幅度谱,丢弃相位谱。
由于信号在时域上的变换通常很难看出信号的特性,所以通常将它转换为频域上的能量分布来观察,不同的能量分布,就能代表不同语音的特性。所以在乘上汉明窗后,每帧还必须再经过快速傅里叶变换以得到在频谱上的能量分布。对分帧加窗后的各帧信号进行快速傅里叶变换得到各帧的频谱。并对语音信号的频谱取模平方得到语音信号的功率谱。设语音信号的DFT为:
6.梅尔转换:
然后要转化到梅尔刻度(听觉音高单位),梅尔刻度是一种基于人耳对等距的音高变化的感官判断而定的非线性m刻度。人耳对低频声音的变化比高频的变化更敏感,所以要做一个转化, 具体做法为让原始信号通过一系列滤波器,实验中取40个,这40个滤波器的横轴在单位为梅尔时是均匀的。
三角带通滤波器有两个主要目的:对频谱进行平滑化,并消除谐波的作用,突显原先语音的共振峰。(因此一段语音的音调或音高,是不会呈现在MFCC 参数内,换句话说,以MFCC 为特征的语音辨识系统,并不会受到输入语音的音调不同而有所影响)此外,还可以降低运算量。
这一步有如下几个效果:
1) 傅里叶变换得到的序列很长(一般为几百到几千个点),把它变换成每个三角形下的能量,可以减少数据量(一般取40个三角形);
2) 频谱有包络和精细结构,分别对应音色与音高。对于语音识别来讲,音色是主要的有用信息,音高一般没有用。在每个三角形内积分,就可以消除精细结构,只保留音色的信息。当然,对于有声调的语言来说,音高也是有用的,所以在MFCC特征之外,还会使用其它特征刻画音高。
3) 三角形是低频密、高频疏的,这可以模仿人耳在低频处分辨率高的特性。
7.log能量
此外,一帧的音量(即能量),也是语音的重要特征,而且非常容易计算。因此,通常再加上一帧的对数能量(定义:一帧内信号的平方和,再取以10为底的对数值,再乘以10)使得每一帧基本的语音特征就多了一维,包括一个对数能量和剩下的倒频谱参数。这一步就是取上一步结果的对数。由于高频部分的能量比较低,低频部分的能量比较高,可以放大低能量处的能量差异;更深层次地,这是在模仿倒谱(cepstrum)的计算步骤。
注:若要加入其它语音特征以测试识别率,也可以在此阶段加入,这些常用的其它语音特征包含音高、过零率以及共振峰等。
8.动态查分参数的提取(包括一阶差分和二阶差分)
标准的倒谱参数MFCC只反映了语音参数的静态特性,语音的动态特性可以用这些静态特征的差分谱来描述。实验证明:把动、静态特征结合起来才能有效提高系统的识别性能。差分参数的计算可以采用下面的公式:
9.DCT
求倒谱时这一步仍然用的是傅里叶变换。计算MFCC时使用的离散余弦变换(discrete cosine transform,DCT)是傅里叶变换的一个变种,好处是结果是实数,没有虚部。DCT还有一个特点是,对于一般的语音信号,这一步的结果的前几个系数特别大,后面的系数比较小,可以忽略。上面说了一般取40个三角形,所以DCT的结果也是40个点;实际中,一般仅保留前13~20个,这就进一步压缩了数据。得到梅尔倒谱。
因此,MFCC的全部组成其实是由:
N维MFCC参数(N/3MFCC系数+ N/3一阶差分参数+ N/3二阶差分参数)+帧能量(此项可根据需求替换)
Ref:
1. http://lufo.me/2015/06/ASR1/
2.https://blog.csdn.net/jojozhangju/article/details/18678861
3.https://blog.csdn.net/zjm750617105/article/details/51690364