机器学习项目流程:
数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已
问题建模——获取数据——特征工程——模型训练——模型调优——线上运行
或者分为三大块:数据准备与预处理;模型选择与训练;模型验证与参数调优。
特征工程
特征如何处理:清洗、标准化、特征选择、特征扩展、更新特征等。
数据清洗:1.比如说一些年龄特征是空值或者负数或者大于200岁等;2.某些页面的播放量大于曝光量,这些就是数据的不合理。
特征的类型包括:
基本特征:空间(种类、数量、金额、大小、重量、长度等等);时间(时长、次数、频率、周期)
统计特征:比例、比值、最大、最小、平均值、中位数、分位点、异常值等
复杂特征:时间和空间(比如近两个月的购物次数);空间和空间(比如超过500元的订单数);时间和空间和统计(最早的两个月购物次数占总购物次数的比重)
自然特征:图像、语音、文本、网络等(如自拍照是否微笑)
数据预处理:
数据预处理的思考流程如下:
(1)读入样本,观察原始数据:
样本类别的取值集合与分布;按照不同的特征类型区分;理解属性字段名,了解对应语义
(2)观察各个特征的分布情况,同时可以进行离群点检测:
对于数值变量:理解连续变量的中心趋势,还有变量的离散程度;
对于类型变量:在每个维度上的分布情况,可以通过条形图展示。
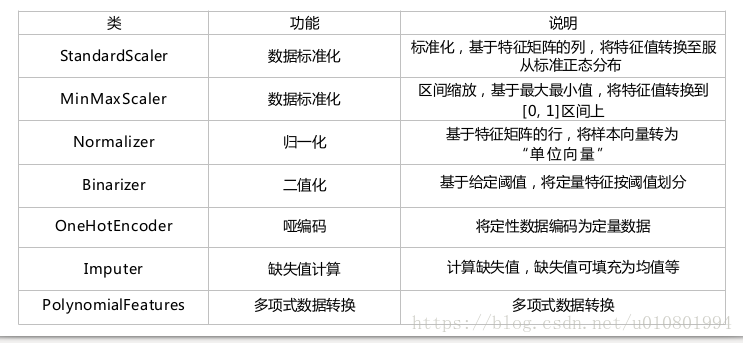
(3)无量纲化
标准化:符合正态分布的可以进行标准化
归一化:非正太分布的建议采用归一化,也叫区间缩放
(4)数值特征离散化:
分段处理(最简单的可以采用二值化)
(5)特征哑编码(Dummy Coding):
最常用的是Onehot编码,采用虚拟变量(也叫哑变量和离散特征编码,可用来表示分类变量、非数据因素可能产生的影响),虚拟变量的两种数据类型:离散特征的取值之间有大小的意义,如尺寸(L,XL,XXL);离散特征的取值之间没有大小的意义,如颜色(red、blue、green)
(6)缺失值填充
缺失值产生的原因:有些信息暂时无法获取;有些信息被遗漏或者错误的处理了。
缺失值处理方法:数据补齐;删除缺失行;不处理。
有几种常见的处理方式:
如果缺值的样本占总数比例极高,我们可能就直接舍弃了,作为特征加入的话,可能反倒带入noise,影响最后的结果了
如果缺值的样本适中,而该属性非连续值特征属性(比如说类目属性),那就把NaN作为一个新类别,加到类别特征中
如果缺值的样本适中,而该属性为连续值特征属性,有时候我们会考虑给定一个step(比如这里的age,我们可以考虑每隔2/3岁为一个步长),然后把它离散化,之后把NaN作为一个type加到属性类目中。
有些情况下,缺失的值个数并不是特别多,那我们也可以试着根据已有的值,拟合一下数据,补充上。
(7)数据变换:
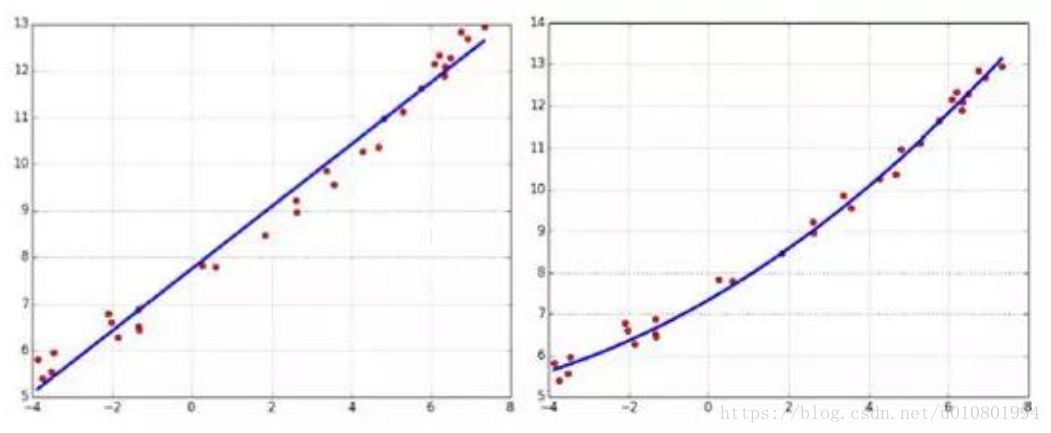
常见的数据变换有基于多项式的、基于指数函数的、基于对数函数的。如4个特征,度为2的多项式转换公式如下:(x1, x2, x3, x4)转换为15项。
转换为:(1, x1, x2, x3, x4, x1x1, x1x2, x1x3, x1x4, x2x2, x2x3, x2x4, x3x3, x3x4, x4x4)
用法: 常用于线性模型中达到非线性的效果。如下图示例,在拟合中加入非线性项的拟合效果更好,但要注意多项式的阶数,以防出现过拟合,类别加了权重,对模型的结果造成了影响。
总结:
当数据预处理完成后,我们需要选择有意义的特征输入机器学习的算法和模型进行训练,通常选择特征从两个方面来考虑:
(1)特征是否发散:如果一个特征不发散,例如方差接近于0,也就是说样本在这个特征上基本上没有差异,这个特征对于样本的区分并没有什么用。
(2)特征与目标的相关性:这点比较显见,与目标相关性高的特征,应当优先选择,比如皮尔逊系数、卡方检验、互信息等。
特征选择:
(1)过滤法filter:对各个特征按照发散性或相关性进行评分,通过设置阈值或者待选择阈值的个数,进行特征的选择;(如卡方检验)
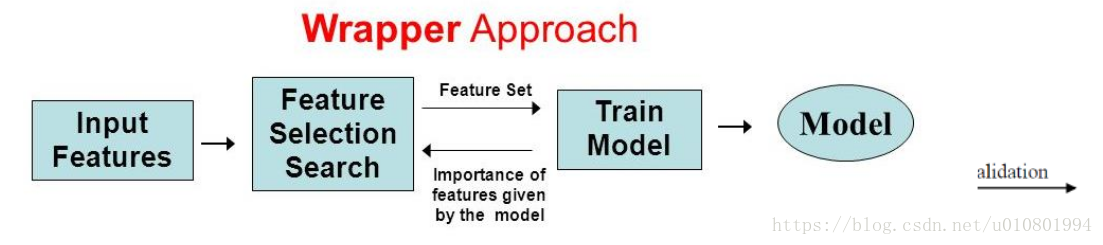
(2)包装法wrapper:根据目标函数(通常是预测效果的评分),每次选择若干特征或排除若干特征;即,将变量一个一个引入,每引入一个变量时,要对已选入的变量进行逐个检验。(RFE递归特征消除法)
缺点:当数据特征维度很大时,评估一遍会花费大量的时间。(每一次挑选都要进行训练)
(3)嵌入法embedded:先使用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据系数从大到小选择特征。类似于过滤法,不同的是该方法是通过训练来确定特征的优劣。
正则项特征选择:L1正则方法具有稀疏解的特性,因此天然具备特征选择的特性,但是要注意,L1没有选到的特征不代表不重要,原因是两个具有高相关性的特征可能只保留了一个,如果要确定哪个特征重要应再通过L2正则方法交叉检验。(神经网络加一个正则项效果会很好)
树模型特征选择:树模型的学习算法采用启发式方法,以信息增益/信息增益比/基尼指数等指标作为选择特征的准则,递归地选择最优特征。
特征提取/构造是在当前基本的特征上获得更多的特征,包括:数据变换(Log,指数,Box-Cox,二值化等);维度变换(PCA,Embedding,聚类等);特征组合
特征工程是将原始数据,通过业务逻辑理解、数据变换、特征交叉与组合等方式,量化成模型训练和预测可直接使用的特征的过程。其中主要包括了数据认知,数据清洗(对数据进行规整,移除重复变量、处理缺失、异常数据等),特征提取,特征选择四个部分。
A) 数据认知:基于实际业务场景理解数据内容,发现数据与研究问题的关系。
B) 数据清洗:对数据进行规整,移除重复变量、处理缺失、异常数据等。
C) 特征提取:通过业务理解和技术实施,构造出描述研究问题的特征。
D)特征选择:在构造的特征中筛选出最能刻画研究问题的特征。
模型诊断和调优
可以根据学习曲线来看,通常最简单的就看两步:
(1)训练集上的AUC是否大于75%=>欠拟合
解决方案: 获取更多数据、增加特征量、用更加复杂的特征和模型
(2)验证集上的AUC和训练集上的AUC是否差距10%=>过拟合
解决方案: 增加样本、特征降维、采用更简单的模型