这是我学习hands on ml with sklearn and tf 这本书做的笔记,这是第二章
该笔记是‘一个完整的机器学习项目’,具体的是预测房价的中位数,包括:获取数据、发现并可视化数据,发现规律、为机器学习算法准备数据、选择模型,进行训练、微调模型、给出解决方案和部署、监控、维护系统。接下来是具体的代码。
1、下载数据
#俗话说,巧妇难为无米之炊,机器学习就是从大量数据中学习规律,所以项目第一步是下载数据,以下是具体代码
import os
import tarfile
from six.moves import urllib
import pandas as pd
DOWNLOAD_ROOT = "https://raw.githubusercontent.com/ageron/handson-ml/master/"
HOUSING_PATH = "datasets/housing"
HOUSING_URL = DOWNLOAD_ROOT + HOUSING_PATH + "/housing.tgz"
def fetch_housing_data(housing_url=HOUSING_URL, housing_path=HOUSING_PATH):
if not os.path.isdir(housing_path):
os.makedirs(housing_path)
tgz_path = os.path.join(housing_path, "housing.tgz")
urllib.request.urlretrieve(housing_url, tgz_path)
housing_tgz = tarfile.open(tgz_path)
housing_tgz.extractall(path=housing_path)
housing_tgz.close()
fetch_housing_data() # 下载数据现在,运行完上述代码 ,就会在工作空间创建一个 datasets/housing 目录,下载 housing.tgz 文件,解压出 housing.csv 。
2、查看数据信息
下载到本地的数据还不能直接用需要使用Pandas加载数据。这里还是用一个小函数来加载数据:
import pandas as pd
def load_housing_data(housing_path=HOUSING_PATH):
csv_path = os.path.join(housing_path, "housing.csv")
return pd.read_csv(csv_path)上述函数会返回一个包含所有数据的 Pandas DataFrame 对象。
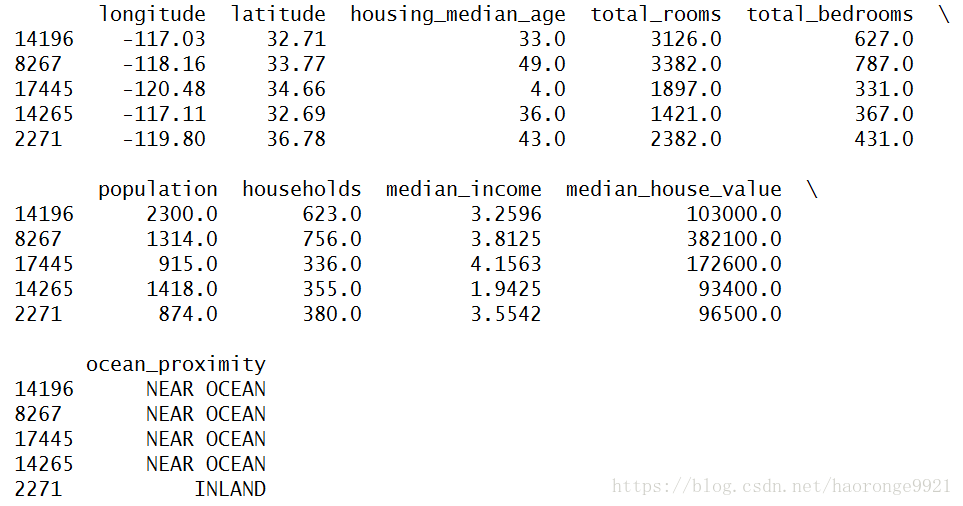
快速查看数据结构,使用 DataFrame 的 head() 方法查看该数据集的前5行:
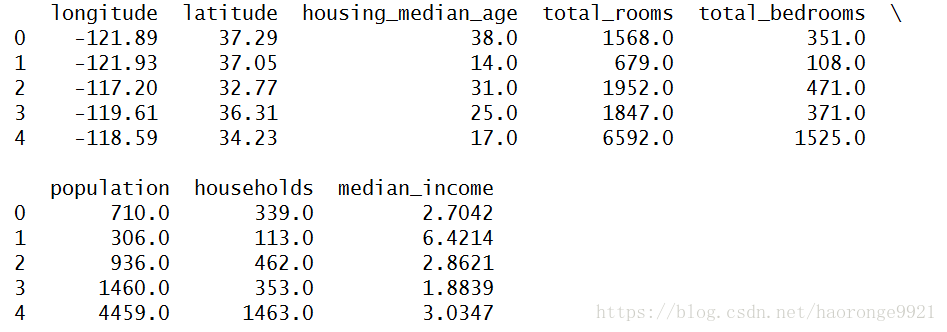
housing = load_housing_data()
print(housing.head())运行上述代码,得到如下结果:
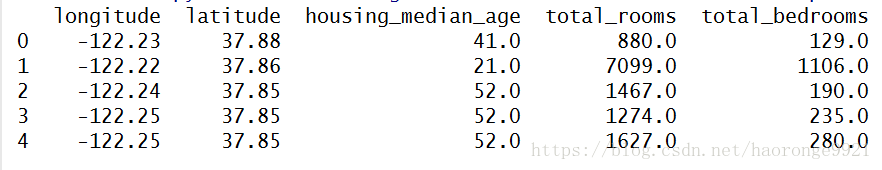
每一行都表示一个街区。共有 10 个属性(截图中可以看到 5 个):经度、维度、房屋年龄中位数、总房间数、总卧室数、人口数、家庭数、收入中位数、房屋价值中位数、离大海距离。
此外,还可以使用info() 方法快速查看数据的描述,特别是总行数、每个属性的类型和非空值的数量。
print(housing.info())输出结果如下:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 20640 entries, 0 to 20639
Data columns (total 10 columns):
longitude 20640 non-null float64
latitude 20640 non-null float64
housing_median_age 20640 non-null float64
total_rooms 20640 non-null float64
total_bedrooms 20433 non-null float64
population 20640 non-null float64
households 20640 non-null float64
median_income 20640 non-null float64
median_house_value 20640 non-null float64
ocean_proximity 20640 non-null object
dtypes: float64(9), object(1)
memory usage: 1.6+ MB
None数据集中共有 20640 个实例。我们注意到总房间数只有 20433 个非空值,这意味着有 207 个街区缺少这个值。后面将对它进行处理。
容易发现,所有的属性都是数值的,除了离大海距离这项。它的类型是对象,因此可以包含任意 Python对象,但是因为该项是从 CSV 文件加载的,所以必然是文本类型。在刚才查看数据前五项时,你可能注意到那一列的值是重复的,意味着它可能是一项表示类别的属性。可以使用 value_counts() 方法查看该项中都有哪些类别,每个类别中都包含有多少个街区:
print(housing['ocean_proximity'].value_counts())得到如下结果;

<1H OCEAN 9136
INLAND 6551
NEAR OCEAN 2658
NEAR BAY 2290
ISLAND 5
Name: ocean_proximity, dtype: int64此外,再来看其它字段。 describe() 方法展示了数值属性的概括。
print(housing.describe())得到如下结果:
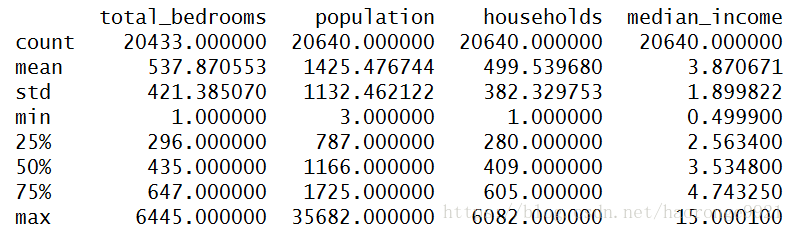
截图中显示四个特征的信息,count 、 mean 、 min 和 max 几行的意思很明显了。注意,空值被忽略了(所以,卧室总数是 20433 而不是 20640)。 std 是标准差(揭示数值的分散度)。25%、50%、75% 展示了对应的分位数:每个分位数指明小于这个值,且指定分组的百分比。例如,25% 的街区的房屋年龄中位数小于 18,而 50% 的小于 29,75% 的小于 37。这些值通常称为第 25 个百分位数(或第一个四分位数),中位数,第 75 个百分位数(第三个四分位数)。
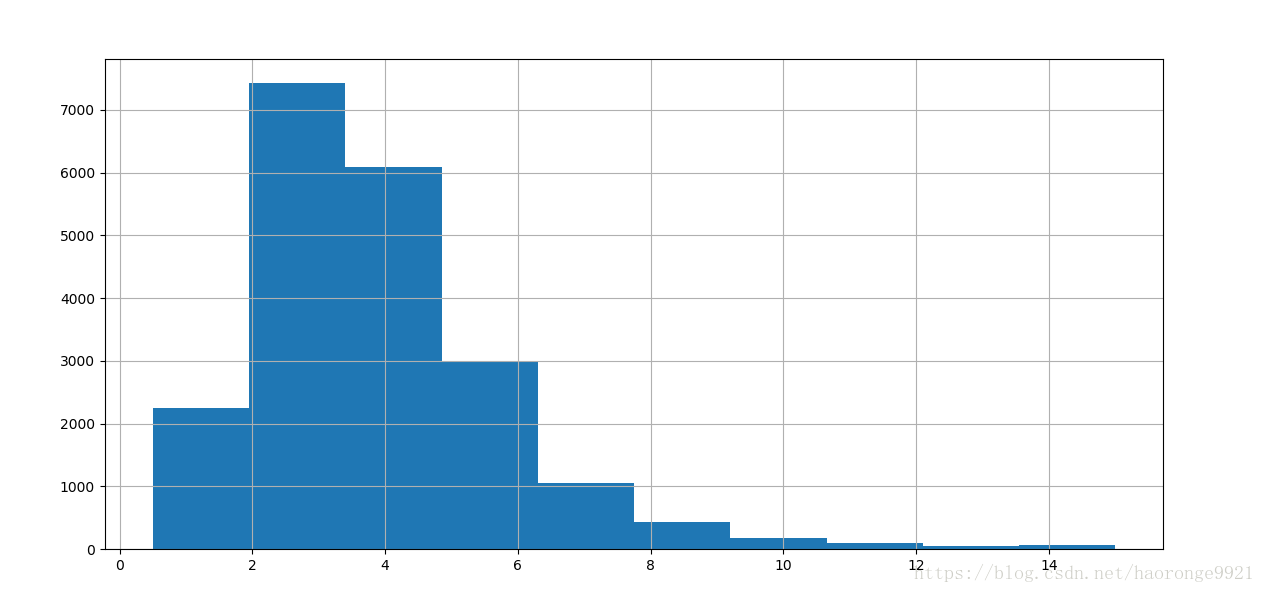
另一种快速了解数据类型的方法是画出每个数值属性的柱状图。柱状图(的纵轴)展示了特定范围的实例的个数。还可以一次给一个属性画图,或对完整数据集调用 hist() 方法,后者会画出每个数值属性的柱状图。例如,你可以看到略微超过 800 个街区的 median_house_value 值差不多等于 500000 美元。
import matplotlib.pyplot as plt
housing.hist(bins=50, figsize=(20,15))
plt.show()得到如下结果;
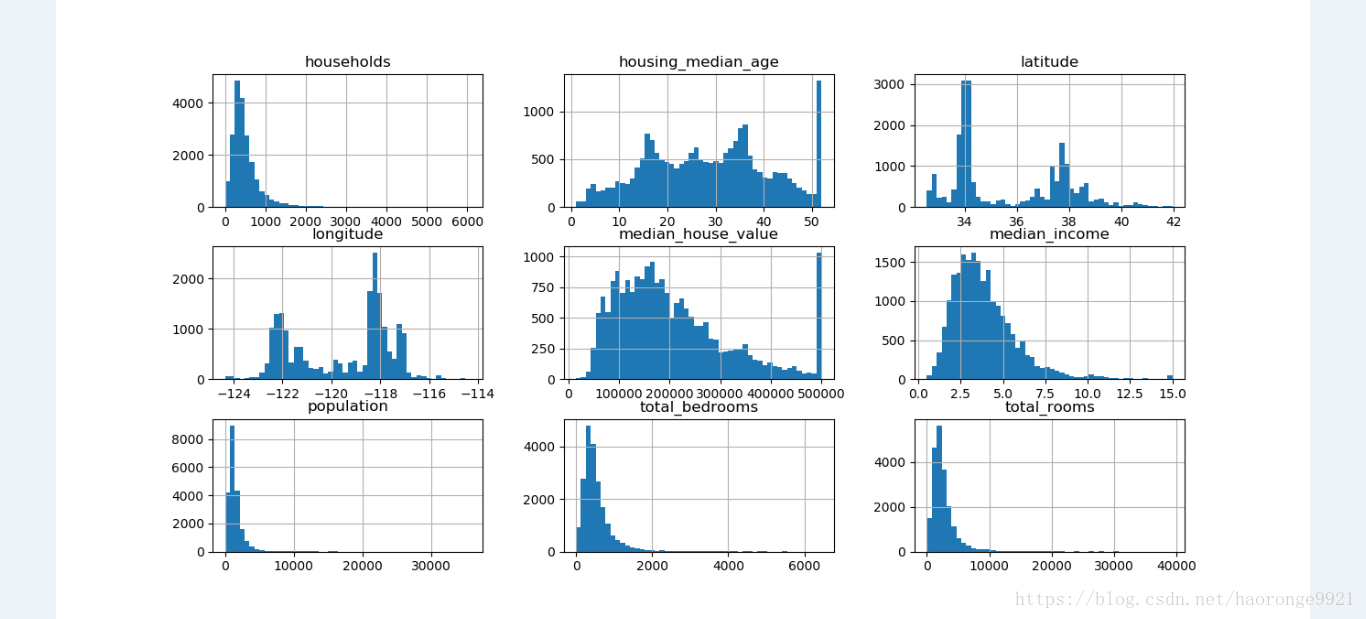
注意柱状图中的一些点:
- 首先,收入中位数貌似不是美元(USD)。与数据采集团队交流之后,你被告知数据是
经过缩放调整的,过高收入中位数的会变为 15(实际为 15.0001),过低的会变为
5(实际为 0.4999)。在机器学习中对数据进行预处理很正常,这不一定是个问题,但你
要明白数据是如何计算出来的。 - 房屋年龄中位数和房屋价值中位数也被设了上限。后者可能是个严重的问题,因为它是
你的目标属性(你的标签)。你的机器学习算法可能学习到价格不会超出这个界限。你
需要与下游团队核实,这是否会成为问题。如果他们告诉你他们需要明确的预测值,即
使超过 500000 美元,你则有两个选项:
i. 对于设了上限的标签,重新收集合适的标签;
ii. 将这些街区从训练集移除(也从测试集移除,因为若房价超出 500000 美元,你的系
统就会被差评)。 - 这些属性值有不同的量度。我们会在本章后面讨论特征缩放。
- 最后,许多柱状图的尾巴很长:相较于左边,它们在中位数的右边延伸过远。对于某些
机器学习算法,这会使检测规律变得更难些。我们会在后面尝试变换处理这些属性,使
其变为正态分布。
3、创建测试集
理论上,创建测试集很简单:只要随机挑选一些实例,一般是数据集的 20%,代码如下:
import numpy as np
def split_train_test(data, test_ratio):
shuffled_indices = np.random.permutation(len(data))
test_set_size = int(len(data) * test_ratio)
test_indices = shuffled_indices[:test_set_size]
train_indices = shuffled_indices[test_set_size:]
return data.iloc[train_indices], data.iloc[test_indices]
train_set, test_set = split_train_test(housing, 0.2)
print(len(train_set), "train +", len(test_set), "test")得到如下结果:
16512 train + 4128 test
这个方法可行,但是并不完美:如果再次运行程序,就会产生一个不同的测试集!多次运行之后,你(或你的机器学习算法)就会得到整个数据集,这是需要避免的。
解决的办法之一是保存第一次运行得到的测试集,并在随后的过程加载。另一种方法是在调用 np.random.permutation() 之前,设置随机数生成器的种子(比如 np.random.seed(42) ),以产生总是相同的洗牌指数(shuffled indices)。
但是如果数据集更新,这两个方法都会失效。一个通常的解决办法是使用每个实例的ID来判定这个实例是否应该放入测试集(假设每个实例都有唯一并且不变的ID)。例如,你可以计算出每个实例ID的哈希值,只保留其最后一个字节,如果该值小于等于 51(约为 256 的20%),就将其放入测试集。这样可以保证在多次运行中,测试集保持不变,即使更新了数据集。新的测试集会包含新实例中的 20%,但不会有之前位于训练集的实例。下面是一种可用的方法:
import hashlib
def test_set_check(identifier, test_ratio, hash):
return hash(np.int64(identifier)).digest()[-1] < 256 * test_ratio
def split_train_test_by_id(data, test_ratio, id_column, hash=hashlib.md5):
ids = data[id_column]
in_test_set = ids.apply(lambda id_: test_set_check(id_, test_ratio, hash))
return data.loc[~in_test_set], data.loc[in_test_set]不过,房产数据集没有ID这一列。最简单的方法是使用行索引作为 ID:
housing_with_id = housing.reset_index() # 加上行索引
train_set, test_set = split_train_test_by_id(housing_with_id, 0.2, "index")
print(train_set.head())运行上述代码,得到如下结果:

可以发现,数据中多出了一个‘index’列。
不过,如果使用行索引作为唯一识别码,你需要保证新数据都放到现有数据的尾部,且没有行被删除。如果做不到,则可以用最稳定的特征来创建唯一识别码。例如,一个区的维度和经度在几百万年之内是不变的,所以可以将两者结合成一个 ID:
housing_with_id["id"] = housing["longitude"] * 1000 + housing["latitude"]
train_set, test_set = split_train_test_by_id(housing_with_id, 0.2, "id")
print(train_set.head())运行上述代码,得到如下结果:
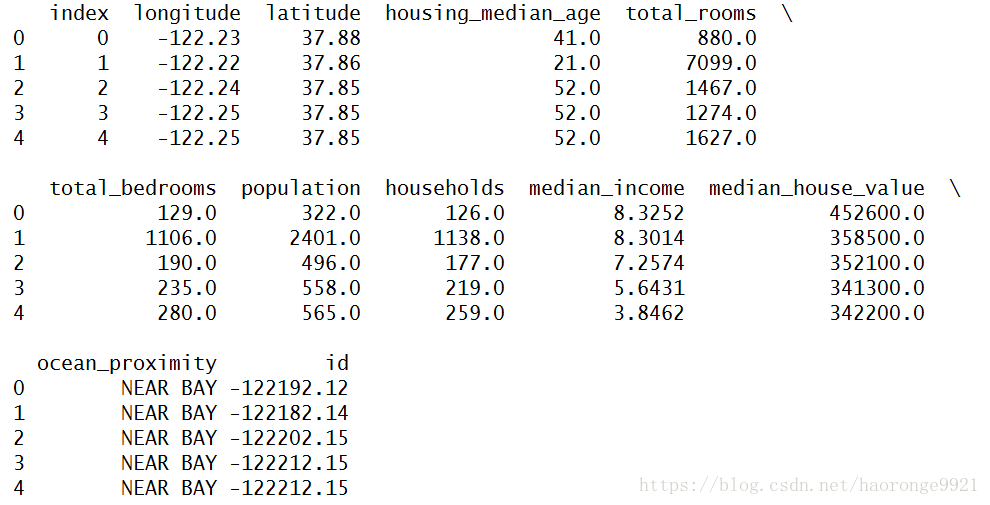
可以发现,不仅多了‘index’列,而且多了‘id’列。
除了上面两个分离测试集的函数外,Scikit-Learn 提供了一些函数,可以用多种方式将数据集分割成多个子集。最简单的函数是 train_test_split ,它的作用和之前的函数 split_train_test 很像,并带有其它一些功能。首先,它有一个 random_state 参数,可以设定前面讲过的随机生成器种子;第二,你可以将种子传递给多个行数相同的数据集,可以在相同的索引上分割数据集(这个功能非常有用,比如你的标签值是放在另一个 DataFrame 里的):
from sklearn.model_selection import train_test_split
train_set, test_set = train_test_split(housing, test_size=0.2, random_state=42)
print(train_set.head())得到的结果如下:
可以发现,skikit-learn包中train_test_split函数处理的是原始数据,并没有对数据增加索引,使用的是行索引。
目前为止,我们采用的都是纯随机的取样方法。假设专家告诉你,收入中位数是预测房价中位数非常重要的属性。你可能想要保证测试集可以代表整体数据集中的多种收入分类。因为收入中位数是一个连续的数值属性,你首先需要创建一个收入类别属性。再仔细地看一下收入中位数的柱状图
大多数的收入中位数的值聚集在 2-5(万美元),但是一些收入中位数会超过 6。数据集中的每个分层都要有足够的实例位于你的数据中,这点很重要。否则,对分层重要性的评估就会有偏差。这意味着,你不能有过多的分层,且每个分层都要足够大。后面的代码通过将收入中位数除以 1.5(以限制收入分类的数量),创建了一个收入类别属性,用 ceil 对值舍入(以产生离散的分类),然后将所有大于 5的分类归入到分类 5:
housing["income_cat"] = np.ceil(housing["median_income"] / 1.5)
housing["income_cat"].where(housing["income_cat"] < 5, 5.0, inplace=True)现在,就可以根据收入分类,进行分层采样。你可以使用 Scikit-Learn的 StratifiedShuffleSplit 类:
from sklearn.model_selection import StratifiedShuffleSplit
split = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=42)
for train_index, test_index in split.split(housing, housing["income_cat"]):
strat_train_set = housing.loc[train_index]
strat_test_set = housing.loc[test_index]
print(housing["income_cat"].value_counts() / len(housing))检查下结果是否符合预期。你可以在完整的房产数据集中查看收入分类比例:

现在,你需要删除 income_cat 属性,使数据回到初始状态:
for set in (strat_train_set, strat_test_set):
set.drop(["income_cat"], axis=1, inplace=True)我们用了大量时间来生成测试集的原因是:测试集通常被忽略,但实际是机器学习非常重要的一部分。还有,生成测试集过程中的许多思路对于后面的交叉验证讨论是非常有帮助的。接下来进入下一阶段:数据探索。
4、数据探索和可视化、发现规律
再继续探索数据之前,先创建一个副本,以免损伤训练集:
housing = strat_train_set.copy()4.1、地理数据可视化
因为存在地理信息(纬度和经度),创建一个所有街区的散点图来数据可视化是一个不错的主意
housing.plot(kind="scatter", x="longitude", y="latitude")
plt.show()运行结果如下:
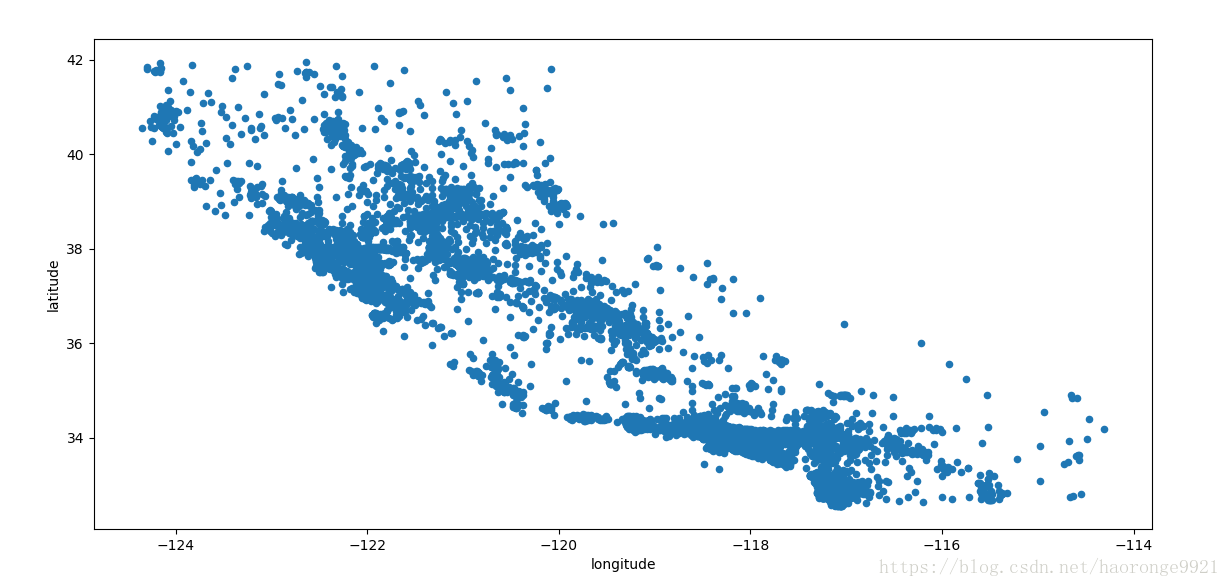
这张图看起来很像加州,但是看不出什么特别的规律。将 alpha 设为 0.1,可以更容易看出数据点的密度
housing.plot(kind="scatter", x="longitude", y="latitude", alpha=0.1)
plt.show()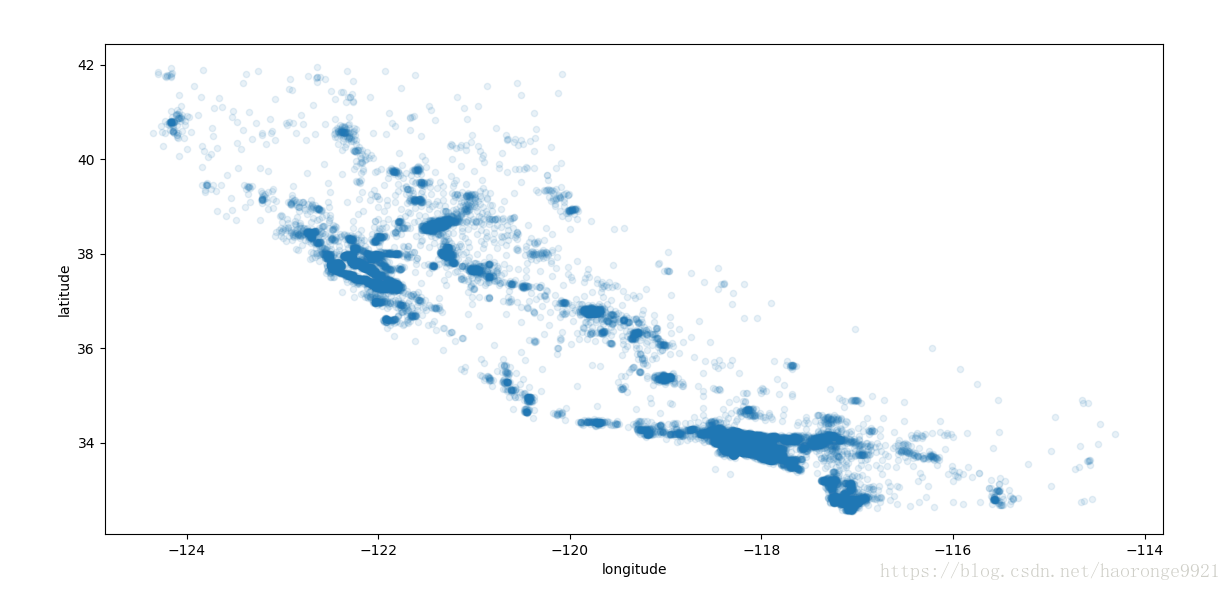
现在看起来好多了:可以非常清楚地看到高密度区域,通常来讲,人类的大脑非常善于发现图片中的规律,但是需要调整可视化参数使规律显现出来。
现在来看房价。每个圈的半径表示街区的人口(选项 s ),颜色代表价格(选项 c )。我们用预先定义的名为 jet 的颜色图(选项 cmap ),它的范围是从蓝色(低价)到红色(高价):
housing.plot(kind="scatter", x="longitude", y="latitude", alpha=0.4,
s=housing["population"]/100, label="population",
c="median_house_value", cmap=plt.get_cmap("jet"), colorbar=True,)
plt.legend()
plt.show()运行结果如下:
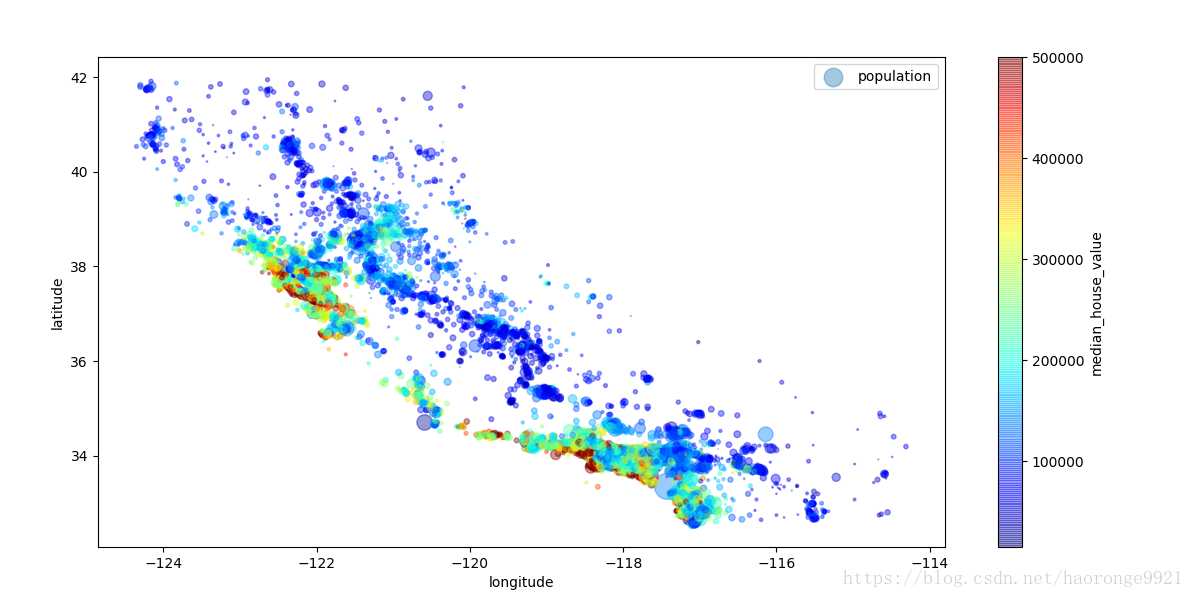
这张图说明房价和位置(比如,靠海)和人口密度联系密切,这点你可能早就知道。可以使用聚类算法来检测主要的聚集,用一个新的特征值测量聚集中心的距离。尽管北加州海岸区域的房价不是非常高,但离大海距离属性也可能很有用,所以这不是用一个简单的规则就可以定义的问题。
4.2、查找关联
因为数据集并不是非常大,你可以很容易地使用 corr() 方法计算出每对属性间的标准相关系数(standard correlation coefficient,也称作皮尔逊相关系数):
corr_matrix = housing.corr()
print(corr_matrix["median_house_value"].sort_values(ascending=False))运行结果如下:

相关系数的范围是 -1 到 1。当接近 1 时,意味强正相关;例如,当收入中位数增加时,房价中位数也会增加。当相关系数接近 -1 时,意味强负相关;你可以看到,纬度和房价中位数有轻微的负相关性(即,越往北,房价越可能降低)。最后,相关系数接近 0,意味没有线性相关性。展示了相关系数在横轴和纵轴之间的不同图形。
另一种检测属性间相关系数的方法是使用 Pandas 的 scatter_matrix 函数,它能画出每个数值属性对每个其它数值属性的图。因为现在共有 11 个数值属性,你可以得到 11 ** 2 = 121 张图,在一页上画不下,所以只关注几个和房价中位数最有可能相关的属性:
from pandas.plotting import scatter_matrix
attributes = ["median_house_value", "median_income", "total_rooms",
"housing_median_age"]
scatter_matrix(housing[attributes], figsize=(12, 8))
plt.show()运行结果如下;
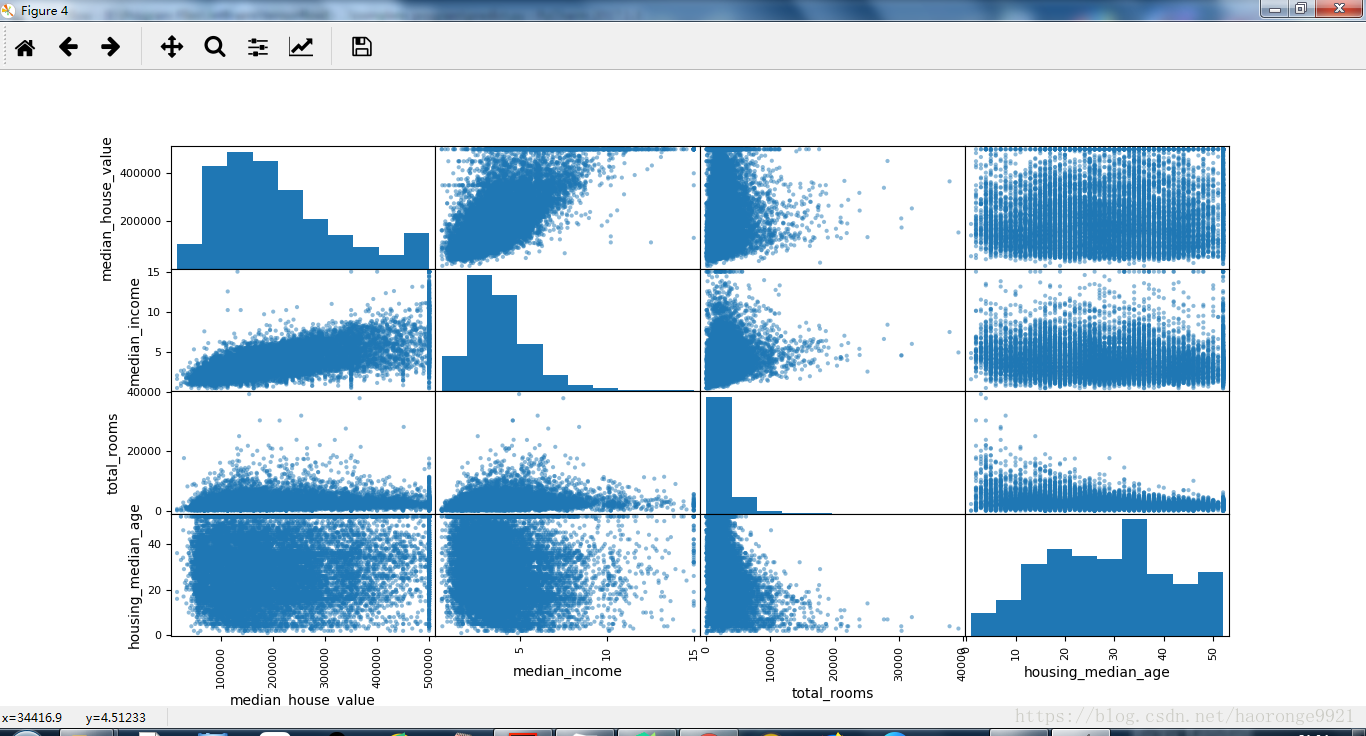
如果 pandas 将每个变量对自己作图,主对角线(左上到右下)都会是直线图。所以 Pandas展示的是每个属性的柱状图(也可以是其它的,请参考 Pandas 文档)。
最有希望用来预测房价中位数的属性是收入中位数,因此将这张图放大
housing.plot(kind="scatter", x="median_income",y="median_house_value", alpha=0.1)
plt.show()运行结果如下:
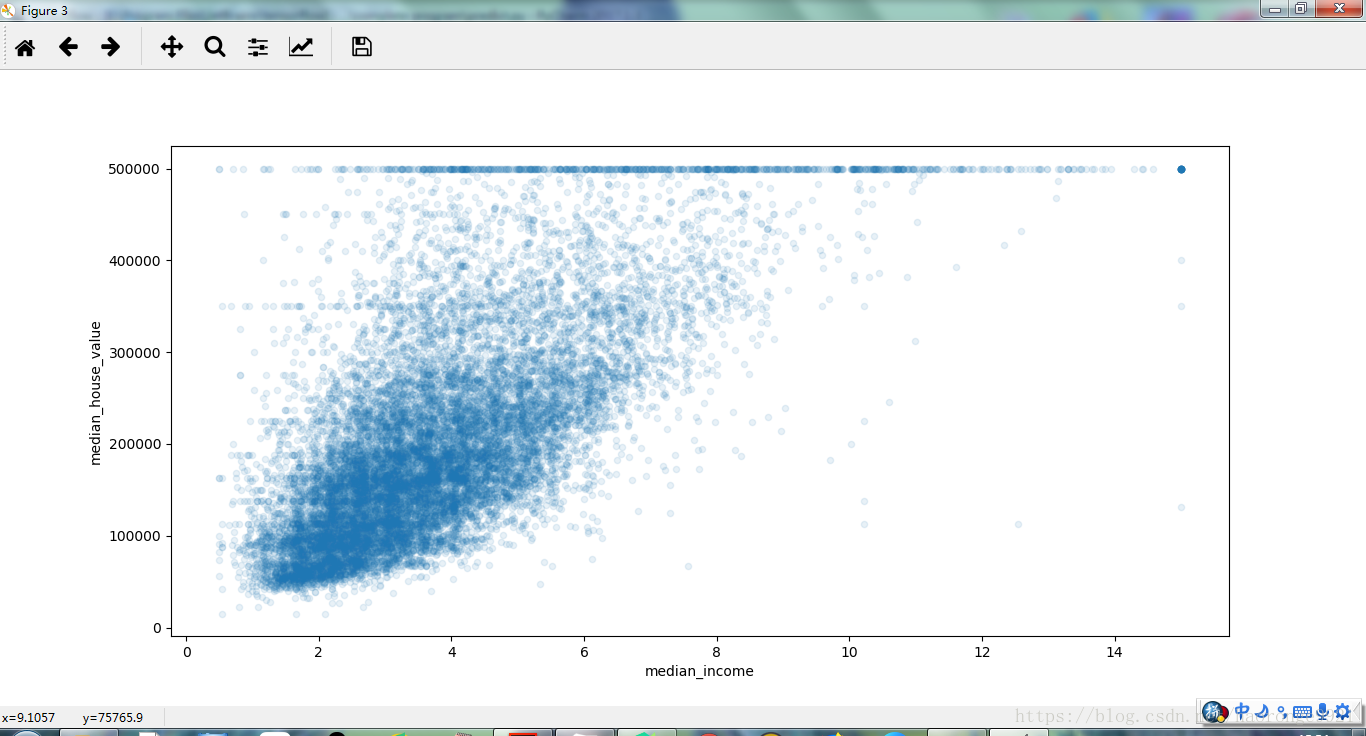
这张图说明了几点。首先,相关性非常高;可以清晰地看到向上的趋势,并且数据点不是非常分散。第二,我们之前看到的最高价,清晰地呈现为一条位于 500000 美元的水平线。这张图也呈现了一些不是那么明显的直线:一条位于 450000 美元的直线,一条位于 350000 美元的直线,一条在 280000 美元的线,和一些更靠下的线。你可能希望去除对应的街区,以防止算法重复这些巧合。
4.3、属性组合试验
给算法准备数据之前,你需要做的最后一件事是尝试多种属性组合。例如,如果你不知道某个街区有多少户,该街区的总房间数就没什么用。你真正需要的是每户有几个房间。相似的,总卧室数也不重要:你可能需要将其与房间数进行比较。每户的人口数也是一个有趣的属性组合。让我们来创建这些新的属性:
housing["rooms_per_household"] = housing["total_rooms"]/housing["households"]
housing["bedrooms_per_room"] = housing["total_bedrooms"]/housing["total_rooms"]
housing["population_per_household"]=housing["population"]/housing["households"]现在再通过相关系数看看各属性之间关系:
corr_matrix = housing.corr()
print(corr_matrix["median_house_value"].sort_values(ascending=False))运行结果如下:
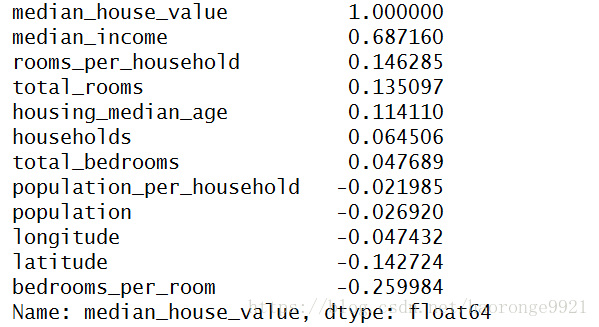
容易发现,与总房间数或卧室数相比,新的 bedrooms_per_room 属性与房价中位数的关联更强。显然,卧室数/总房间数的比例越低,房价就越高。每户的房间数也比街区的总房间数的更有信息,很明显,房屋越大,房价就越高。
4.4、为机器学习算法准备数据
但是,还是先回到干净的训练集(通过再次复制 strat_train_set ),将预测量和标签分开,因为我们不想对预测量和目标值应用相同的转换(注意 drop() 创建了一份数据的备份,而不影响 strat_train_set ):
housing = strat_train_set.drop("median_house_value", axis=1)
housing_labels = strat_train_set["median_house_value"].copy()5、数据清洗
还记得total_bedrooms 有一些缺失值吗?大多机器学习算法不能处理缺失的特征,因此先创建一些函数来处理特征缺失的问题。所以,首先要解决这个问题,有如下三个方法:
(1)去掉对应的街区;
(2)去掉整个属性;
(3)进行赋值(0、平均值、中位数等等)。
用 DataFrame 的 dropna() , drop() ,和 fillna() 方法,可以依次实现上面三种方法:
housing.dropna(subset=["total_bedrooms"]) # 选项1
housing.drop("total_bedrooms", axis=1) # 选项2
median = housing["total_bedrooms"].median()
housing["total_bedrooms"].fillna(median) # 选项3如果选择选项 3,你需要计算训练集的中位数,用中位数填充训练集的缺失值,不要忘记保存该中位数。后面用测试集评估系统时,需要替换测试集中的缺失值,也可以用来实时替换新数据中的缺失值。
除了 上面介绍的三种方法处理缺失值外,Scikit-Learn 提供了一个方便的类来处理缺失值: Imputer 。下面是其使用方法:首先,需要创建一个 Imputer 实例,指定用某属性的中位数来替换该属性所有的缺失值:
from sklearn.preprocessing import Imputer
imputer = Imputer(strategy="median")因为只有数值属性才能算出中位数,我们需要创建一份不包括文本属性 ocean_proximity 的数据副本:
housing_num = housing.drop("ocean_proximity", axis=1)现在,就可以用 fit() 方法将 imputer 实例拟合到训练数据:
imputer.fit(housing_num)imputer 计算出了每个属性的中位数,并将结果保存在了实例变量 statistics_ 中。虽然此时只有属性total_bedrooms 存在缺失值,但我们不能确定在以后的新的数据中会不会有其他属性也存在缺失值,所以安全的做法是将 imputer 应用到每个数值:
print(imputer.statistics_)得到如下结果:
[-118.51 34.26 29. 2119.5 433. 1164. 408. 3.5409]
现在,可以使用这个“训练过的” imputer 来对训练集进行转换,将缺失值替换为中位数:
X = imputer.transform(housing_num)结果是一个包含转换后特征的普通的 Numpy 数组。如果你想将其放回到Pandas DataFrame 中,也很简单:
housing_tr = pd.DataFrame(X, columns=housing_num.columns)
print(housing_tr.head())运行结果:
6、处理文本和类别属性
之前,我们丢弃了类别属性 ocean_proximity ,因为它是一个文本属性,不能计算出中位数。大多数机器学习算法跟喜欢和数字打交道,所以让我们把这些文本标签转换为数字。Scikit-Learn 为这个任务提供了一个转换器 LabelEncoder:
from sklearn.preprocessing import LabelEncoder
encoder = LabelEncoder()
housing_cat = housing["ocean_proximity"]
housing_cat_encoded = encoder.fit_transform(housing_cat)
print(housing_cat_encoded)运行结果如下:
[0 0 4 … 1 0 3]
7、自定义转换器
尽管 Scikit-Learn 提供了许多有用的转换器,你还是需要自己动手写转换器执行任务,比如自定义的清理操作,或属性组合。你需要让自制的转换器与 Scikit-Learn 组件(比如流水线)无缝衔接工作,因为 Scikit-Learn 是依赖鸭子类型的(而不是继承),你所需要做的是创建一个类并执行三个方法: fit() (返回 self ), transform() ,和 fit_transform() 。通过添加 TransformerMixin 作为基类,可以很容易地得到最后一个。另外,如果你添加 BaseEstimator 作为基类(且构造器中避免使用 *args 和 **kargs ),你就能得到两个额外的方法( get_params() 和 set_params() ),二者可以方便地进行超参数自动微调。例如,一个小转换器类添加了上面讨论的属性:
from sklearn.base import BaseEstimator, TransformerMixin
rooms_ix, bedrooms_ix, population_ix, household_ix = 3, 4, 5, 6
class CombinedAttributesAdder(BaseEstimator, TransformerMixin):
def __init__(self, add_bedrooms_per_room=True): # no *args or **kargs
self.add_bedrooms_per_room = add_bedrooms_per_room
def fit(self, X, y=None):
return self # nothing else to do
def transform(self, X, y=None):
rooms_per_household = X[:, rooms_ix] / X[:, household_ix]
population_per_household = X[:, population_ix] / X[:, household_ix]
if self.add_bedrooms_per_room:
bedrooms_per_room = X[:, bedrooms_ix] / X[:, rooms_ix]
return np.c_[X, rooms_per_household, population_per_household,
bedrooms_per_room]
else:
return np.c_[X, rooms_per_household, population_per_household]
attr_adder = CombinedAttributesAdder(add_bedrooms_per_room=False)
housing_extra_attribs = attr_adder.transform(housing.values)在这个例子中,转换器有一个超参数 add_bedrooms_per_room ,默认设为 True (提供一个合理的默认值很有帮助)。这个超参数可以让你方便地发现添加了这个属性是否对机器学习算法有帮助。更一般地,你可以为每个不能完全确保的数据准备步骤添加一个超参数。数据准备步骤越自动化,可以自动化的操作组合就越多,越容易发现更好用的组合(并能节省大量时间)。
8、特征缩放
数据要做的最重要的转换之一是特征缩放。除了个别情况,当输入的数值属性量度不同时,机器学习算法的性能都不会好。这个规律也适用于房产数据:总房间数分布范围是 6 到39320,而收入中位数只分布在 0 到 15。注意通常情况下我们不需要对目标值进行缩放。
有两种常见的方法可以让所有的属性有相同的量度:线性函数归一化(Min-Max scaling)和标准化(standardization)。
线性函数归一化(许多人称其为归一化(normalization))很简单:值被转变、重新缩放,直到范围变成 0 到 1。我们通过减去最小值,然后再除以最大值与最小值的差值,来进行归一化。Scikit-Learn 提供了一个转换器 MinMaxScaler 来实现这个功能。它有一个超参数 feature_range ,可以让你改变范围,如果不希望范围是 0 到 1。
标准化就很不同:首先减去平均值(所以标准化值的平均值总是 0),然后除以方差,使得到的分布具有单位方差。与归一化不同,标准化不会限定值到某个特定的范围,这对某些算法可能构成问题(比如,神经网络常需要输入值得范围是 0 到 1)。但是,标准化受到异常值的影响很小。例如,假设一个街区的收入中位数由于某种错误变成了100,归一化会将其它范围是 0 到 15 的值变为 0-0.15,但是标准化不会受什么影响。Scikit-Learn 提供了一个转换器 StandardScaler 来进行标准化。
9、转换流水线
到目前为止,存在许多数据转换步骤,需要按一定的顺序执行。幸运的是,Scikit-Learn 提供了类 Pipeline ,来进行这一系列的转换。下面是一个数值属性的小流水线:
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
num_pipeline = Pipeline([
('imputer', Imputer(strategy="median")),
('attribs_adder', CombinedAttributesAdder()),
('std_scaler', StandardScaler()),
])
housing_num_tr = num_pipeline.fit_transform(housing_num)Pipeline 构造器需要一个定义步骤顺序的名字/估计器对的列表。除了最后一个估计器,其余都要是转换器(即,它们都要有 fit_transform() 方法)。名字可以随意起。
当你调用流水线的 fit() 方法,就会对所有转换器顺序调用 fit_transform() 方法,将每次调用的输出作为参数传递给下一个调用,一直到最后一个估计器,它只执行 fit() 方法。
流水线暴露相同的方法作为最终的估计器。在这个例子中,最后的估计器是一个 StandardScaler ,它是一个转换器,因此这个流水线有一个 transform() 方法,可以顺序对数据做所有转换(它还有一个 fit_transform 方法可以使用,就不必先调用 fit() 再进行 transform() )。
你现在就有了一个对数值的流水线,你还需要对分类值应用 LabelBinarizer :如何将这些转换写成一个流水线呢?Scikit-Learn 提供了一个类 FeatureUnion 实现这个功能。你给它一列转换器(可以是所有的转换器),当调用它的 transform() 方法,每个转换器的 transform() 会被并行执行,等待输出,然后将输出合并起来,并返回结果(当然,调用它的 fit() 方法就会调用每个转换器的 fit() )。一个完整的处理数值和类别属性的流水线如下所示:
from sklearn.pipeline import FeatureUnion
num_attribs = list(housing_num)
cat_attribs = ["ocean_proximity"]
num_pipeline = Pipeline([
('selector', DataFrameSelector(num_attribs)),
('imputer', Imputer(strategy="median")),
('attribs_adder', CombinedAttributesAdder()),
('std_scaler', StandardScaler()),
])
cat_pipeline = Pipeline([
('selector', DataFrameSelector(cat_attribs)),
('label_binarizer', CategoricalEncoder()),
])
full_pipeline = FeatureUnion(transformer_list=[
("num_pipeline", num_pipeline),
("cat_pipeline", cat_pipeline),
])10、选择并训练模型
可到这一步了!你在前面限定了问题、获得了数据、探索了数据、采样了一个测试集、写了自动化的转换流水线来清理和为算法准备数据。现在,你已经准备好选择并训练一个机器学习模型了。
10.1、在训练集上训练和评估
好消息是基于前面的工作,接下来要做的比你想的要简单许多。像前一章那样,我们先来训练一个线性回归模型:
from sklearn.linear_model import LinearRegression
lin_reg = LinearRegression()
lin_reg.fit(housing_prepared, housing_labels)
完毕!你现在就有了一个可用的线性回归模型。用一些训练集中的实例做下验证:
some_data = housing.iloc[:5]
some_labels = housing_labels.iloc[:5]
some_data_prepared = full_pipeline.transform(some_data)
print("预测值是:", lin_reg.predict(some_data_prepared))
print("实际值是:", list(some_labels))运行结果:
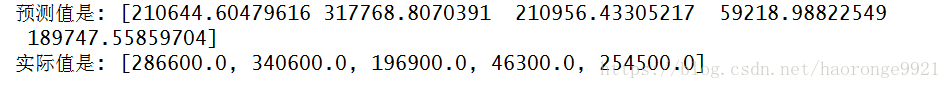
行的通,尽管预测并不怎么准确。让我们使用 Scikit-Learn 的 mean_squared_error 函数,用全部训练集来计算下这个回归模型的 RMSE:
from sklearn.metrics import mean_squared_error
housing_predictions = lin_reg.predict(housing_prepared)
lin_mse = mean_squared_error(housing_labels, housing_predictions)
lin_rmse = np.sqrt(lin_mse)
print(lin_rmse)运行结果:
68628.19819848923显然结果并不好:大多数街区的 median_housing_values 位于 120000到 265000 美元之间,因此预测误差 68628 美元不能让人满意。这是一个模型欠拟合训练数据的例子。当这种情况发生时,意味着特征没有提供足够多的信息来做出一个好的预测,或者模型并不强大。就像前一章看到的,修复欠拟合的主要方法是选择一个更强大的模型,给训练算法提供更好的特征,或去掉模型上的限制。这个模型还没有正则化,所以排除了最后
一个选项。你可以尝试添加更多特征(比如,人口的对数值),但是首先让我们尝试一个更
为复杂的模型,看看效果。
来训练一个 DecisionTreeRegressor 。这是一个强大的模型,可以发现数据中复杂的非线性关系。代码看起来很熟悉:
““
from sklearn.tree import DecisionTreeRegressor
tree_reg = DecisionTreeRegressor()
tree_reg.fit(housing_prepared, housing_labels)
housing_predictions = tree_reg.predict(housing_prepared)
tree_mse = mean_squared_error(housing_labels, housing_predictions)
tree_rmse = np.sqrt(tree_mse)
print(tree_rmse)
““
运行结果:
0.0发生了什么?没有误差?这个模型可能是绝对完美的吗?当然,更大可能性是这个模型严重过拟合数据。如何确定呢?如前所述,直到你准备运行一个具备足够信心的模型,都不要碰测试集,因此你需要使用训练集的部分数据来做训练,用一部分来做模型验证。
10.2、使用交叉验证做更佳的评估
评估决策树模型的一种方法是用函数 train_test_split 来分割训练集,得到一个更小的训练集和一个验证集,然后用更小的训练集来训练模型,用验证集来评估。这需要一定工作量,并不难而且也可行。
另一种更好的方法是使用 Scikit-Learn 的交叉验证功能。下面的代码采用了 K 折交叉验证(K-fold cross-validation):它随机地将训练集分成十个不同的子集,成为“折”,然后训练评估决策树模型 10 次,每次选一个不用的折来做评估,用其它 9 个来做训练。结果是一个包含10 个评分的数组:
from sklearn.model_selection import cross_val_score
scores = cross_val_score(tree_reg, housing_prepared, housing_labels,
scoring="neg_mean_squared_error", cv=10)
rmse_scores = np.sqrt(-scores)
print(rmse_scores)这里有一个问题:Scikit-Learn 交叉验证功能期望的是效用函数(越大越好)而不是损失函数(越低越好),因此得分函数实际上与 MSE 相反(即负值),这就是为什么前面的代码在计算平方根之前先计算 -scores 。
运行结果如下:
[68315.83133545 68051.68547903 71912.48620198 69903.10927312 71195.0121666 75228.80218493 70181.59676127 71261.66487814 75954.88755487 68284.58357588]这一章先写到这,其它的有时间补上。