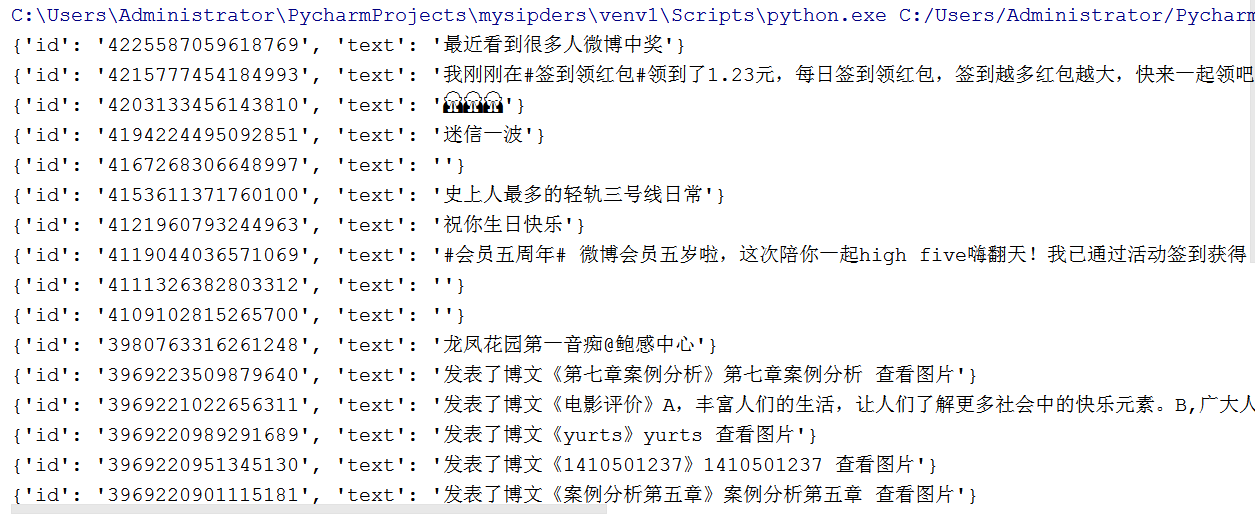
爬取通过异步加载的微博主页内容: [https://m.weibo.cn/u/5610887288](https://m.weibo.cn/u/5610887288)
分析网页的内容,可以发现微博主页的加载后续是通过Ajax完成的,于是打开开发者工具(F12) -> network -> xhr 分析发现:
'https://m.weibo.cn/api/container/getIndex?type=uid&value=5610887288&containerid=1076035610887288&page=1'
'https://m.weibo.cn/api/container/getIndex?type=uid&value=5610887288&containerid=1076035610887288&page=2'
'https://m.weibo.cn/api/container/getIndex?type=uid&value=5610887288&containerid=1076035610887288&page=3'
接口url里的page参数每次都改变了一个数值,那么获取API接口的内容,则只需改变page参数即可。
具体代码如下:
import requests
import re
from pyquery import PyQuery
from urllib.parse import urlencode
def get_one_page(url):
# 模仿浏览器登陆防止被ban
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.5408.400 QQBrowser/10.1.1430.400'
}
response = requests.get(url, headers=headers)
html = response.json()
return html
# 解析通过API接口传输过来的json数据
def parse_json(html):
if html:
# 分析接口数据 拿到data里的cards
items = html.get('data').get('cards')
for item in items:
weibo = {}
item = item.get('mblog')
weibo['id'] = item.get('id')
# 方法1 通过PyQuery拿到text里的文本数据(去掉标签)
weibo['text'] = PyQuery(item.get('text')).text()
# 方法2 通过re.sub替换所有标签
# mystr = item.get('text')
# dr = re.compile(r'<[^>]+>', re.S)
# dd = dr.sub('', mystr)
# weibo['text'] = dd
# 返回生成器
yield weibo
def main():
# 通过分析API接口 https://m.weibo.cn/api/container/getIndex?type=uid&value=5610887288&containerid=1076035610887288&page=3
# 发现AJAX传输数据是通过page=后面的参数来传输
# 由于我的微博通过AJAX传输的只有4条,就只抓取4条
base_url = 'https://m.weibo.cn/api/container/getIndex?'
for i in range(1,5):
params = {
'type': 'uid',
'value': '5610887288',
'containerid': '1076035610887288',
'page': i,
}
full_url = base_url + urlencode(params)
html = get_one_page(full_url)
# print(type(html)) # dict
results = parse_json(html)
for result in results:
print(result)
if __name__ == '__main__':
main()运行结果: