一、集成算法是什么?
集成算法是一种通过将多个单一学习器(分类器、回归器等)的预测结果进行结合来提高机器学习性能的技术。在这个过程中,每个单一学习器都是针对相同的数据集进行训练的,但是它们可以有不同的参数设置、算法选择和特征选择,以达到提高预测准确性和稳定性的目的。
集成算法通常分为三种类型:基于Bagging,Boosting,Stacking的算法。
- Bagging算法通过随机抽取数据样本进行有放回的采样,然后使用这些样本训练多个独立的分类器。这些分类器的结果被合并在一起以产生最终的预测结果。
- Boosting算法则是通过训练一系列弱分类器,其中每个分类器都被设计成可以修正先前分类器的错误,以产生一个强大的分类器。
- Stacking算法聚合多个分类或回归模型,可以通过分阶段来训练
因此它的优点有很多
- 集成算法通常比单一学习器具有更好的泛化能力,可以减少过拟合的风险。
- 由于集成算法通过将多个学习器的预测结果进行结合,因此其预测结果通常比单一学习器更准确。
- 集成算法可以应用于多种机器学习问题,包括分类、回归和聚类等问题。
二、Bagging和Boosting案例比较
- 数据集加载
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import BaggingClassifier, RandomForestClassifier, AdaBoostClassifier
from sklearn.metrics import accuracy_score
# 加载Iris数据集
iris = load_iris()
X = iris.data
y = iris.target
# 将数据集拆分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42
我们将使用三种不同的集成算法来训练我们的模型:
- 基于Bagging的决策树算法
# 基于Bagging的决策树算法
dt = DecisionTreeClassifier()
bag_clf = BaggingClassifier(dt, n_estimators=500, max_samples=100, bootstrap=True, random_state=42)
bag_clf.fit(X_train, y_train)
y_pred_bag = bag_clf.predict(X_test)
- 基于随机森林
# 基于随机森林的算法
rf_clf = RandomForestClassifier(n_estimators=500, max_leaf_nodes=16, random_state=42)
rf_clf.fit(X_train, y_train)
y_pred_rf = rf_clf.predict(X_test)
- 基于Adaboost
# 基于Adaboost的算法
ada_clf = AdaBoostClassifier(DecisionTreeClassifier(max_depth=1), n_estimators=200, algorithm="SAMME.R", learning_rate=0.5, random_state=42)
ada_clf.fit(X_train, y_train)
y_pred_ada = ada_clf.predict(X_test)
我们打印他们的准确率看一下
print("Bagging准确率:", accuracy_score(y_test, y_pred_bag))
print("随机森林准确率:", accuracy_score(y_test, y_pred_rf))
print("Adaboost准确率:", accuracy_score(y_test, y_pred_ada))

可以看到Bagging和 随机森林比adaboost好一点,但是不同的数据集会有不同的表现,多多尝试就好
三、软投票与硬投票
集成算法是一种将多个单一分类器的预测结果结合起来,以获得更准确和稳健的分类器的方法。其中两种常用的集成方法是软投票和硬投票。
- 硬投票是指集成算法中,将多个分类器的预测结果按照多数原则进行投票,即选择得票最多的类别作为最终的预测结果。这种方法适用于分类结果为离散值的问题。
例如,假设有三个分类器分别预测一个样本的标签为A、B、B,则硬投票算法会将最终的预测结果确定为B。- 软投票则是指对多个分类器的预测结果进行加权平均,并选择平均得分最高的标签作为最终的预测结果。每个分类器的权重可以根据其在训练集上的表现来确定。这种方法适用于分类结果为连续值的问题。
例如,假设有三个分类器对一个样本进行了预测,其预测结果的概率分别为0.4、0.5、0.6,则软投票算法会将最终的预测结果确定为B,并将其得分计算为(0.4×w1 + 0.5×w2 + 0.6×w3)/ (w1+w2+w3),其中w1、w2和w3是每个分类器的权重。
数据集构造
这次我们依旧构造鸢尾花分类数据
import matplotlib
import matplotlib.pyplot as plt
import mplcyberpunk
import warnings
warnings.filterwarnings('ignore')
plt.style.use('cyberpunk')
import numpy as np
np.random.seed(24)
#%%
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
iris=load_iris()
iris
X_train,X_test,y_train,y_test=train_test_split(iris.data,iris.target)
模型构建
我们这里会用到逻辑回归,随机森林,SVM作为我们的分类,VotingClassifier为我们的分类投票器
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier,VotingClassifier
log_clf=LogisticRegression(random_state=42)
rnd_clf=RandomForestClassifier(random_state=42)
svm_clf=SVC(random_state=42)
硬投票
我们测试单独一个和集成的精确率
voting_vlf=VotingClassifier(estimators=[
('lr',log_clf),('rg',rnd_clf),('svs',svm_clf)],
voting='hard'#hard硬投票,soft软投票
)
voting_vlf.fit(X_train,y_train)
#%%
from sklearn.metrics import accuracy_score
for clf in (log_clf,rnd_clf,svm_clf,voting_vlf):
clf.fit(X_train,y_train)
y_pred=clf.predict(X_test)
print(clf.__class__.__name__,accuracy_score(y_test,y_pred))
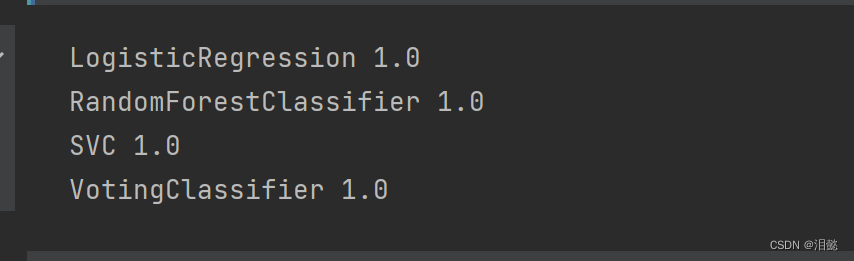
可以看到由于我们数据集比较好,精确度比较高,所以很难看出区别
软投票
svm_clf=SVC(random_state=24,probability=True)
voting_vlf_soft=VotingClassifier(estimators=[
('lr',log_clf),('rg',rnd_clf),('svs',svm_clf)],
voting='soft',#hard硬投票,soft软投票,
)
voting_vlf_soft.fit(X_train,y_train)
for clf in (log_clf,rnd_clf,svm_clf,voting_vlf):
clf.fit(X_train,y_train)
y_pred=clf.predict(X_test)
print(clf.__class__.__name__,accuracy_score(y_test,y_pred))
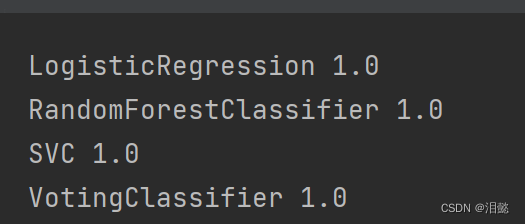
结果的话和上面一样,但如果数据比较不好的情况下,软投票相比硬投票效果会好一点
总结
简单介绍了集成算法,集成算法常见算法比较,以及集成算法的软投票和硬投票,下一节将会更加详细分别去介绍集成算法中的Bagging,Boosting,Stacking,
本人能力有效,上述内容如有错误,欢迎指正
我会继续努力,希望大家多多支持