一以分布式集群运行
- 修改配置文件/hadoop_opt/spark-2.3.2-bin-hadoop2.6/conf/spark-env.sh
export HADOOP_CONF_DIR=/hadoop_opt/hadoop-2.6.1/etc/hadoop
export JAVA_HOME=/hadoop_opt/jdk1.8.0_181
export HADOOP_HOME=/hadoop_opt/hadoop-2.6.1
export SCALA_HOME=/hadoop_opt/scala-2.12.7
export SPARK_MASTER_IP=192.168.197.128
修改/hadoop_opt/spark-2.3.2-bin-hadoop2.6/conf/slaves,在最后加入如下代码
master
slave1
slave2
2.slave执行和master相同的操作,登陆master执行向slave分发操作
scp -r /hadoop_opt/spark root@slave1 /hadoop_opt
scp -r /hadoop_opt/spark root@slave2 /hadoop_opt
3.在master终端输入
进入spark安装目录的sbin文件夹下,先启动master,再启动slaves
[root@master sbin]# ./start-master.sh
[root@master sbin]# ./start-slaves.sh
使用jps分别查看master和slave的进程
[root@master sbin]# jps
4786 Master
4850 Jps
3527 ResourceManager
3181 NameNode
3374 SecondaryNameNode
[root@slave1 hadoop01]# jps
1904 NodeManager
2421 Worker
3470 Jps
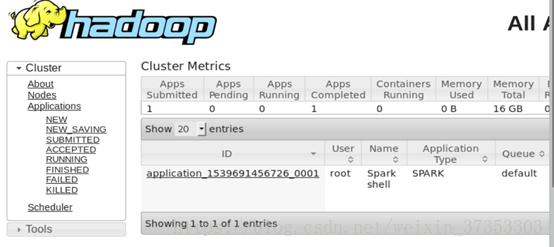
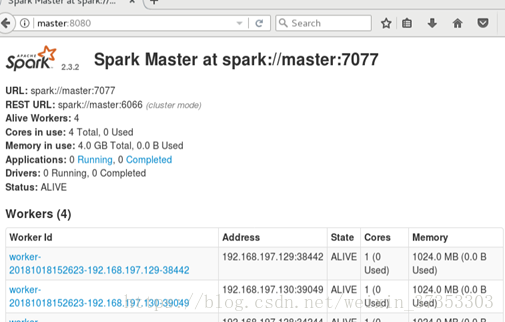
4.在浏览器中输入http://master:8080
二以yarn client运行
1.master 终端输入
spark-shell --master yarn-client即可,最后出现如下截图
注:输入命令spark-shell --master yarn --deploy-mode client也可
sprk的配置是按照分布式集群方式配置的,但是在这种方式配置下这两种方式都可以运行。
网上的配置方法有点把我绕晕了,有的没有安装hadoop就配置spark集群了,有的却需要安装hadoop。真是被搞晕了。