目录
合并数据集--数据库风格的DataFrame合并
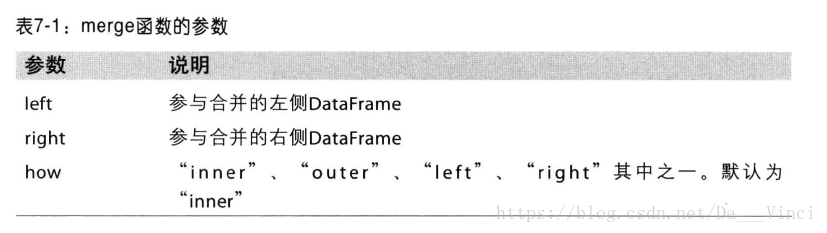
数据集的合并或连接运算是通过一个或多个键将行连接起来,这些运算是关系型数据库的核心。
merge默认进行内连接,即是键的交集,保存最大集合数量。
如果要根据多个列进行合并,传入一组由列名组成的列表即可
对于重复列名,使用suffixes选项设置参数即可。如suffixes(‘_left’,‘_right’)
>>> from pandas import DataFrame
Backend TkAgg is interactive backend. Turning interactive mode on.
>>> df1 = DataFrame({'key':['b','b','a','c','a','a','b'],'data1':range(7)})
>>> df2 = DataFrame({'key':['a','b','d']})
>>> df1
data1 key
0 0 b
1 1 b
2 2 a
3 3 c
4 4 a
5 5 a
6 6 b
>>> df2
key
0 a
1 b
2 d
>>> import pandas as pd
>>> pd.merge(df1,df2,on='key')
data1 key
0 0 b
1 1 b
2 6 b
3 2 a
4 4 a
5 5 a
>>> pd.merge(df2,df1,on='key',how = 'left')
key data1
0 a 2.0
1 a 4.0
2 a 5.0
3 b 0.0
4 b 1.0
5 b 6.0
6 d NaN
>>> pd.merge(df2,df1,on='key',how = 'right')
key data1
0 a 2
1 a 4
2 a 5
3 b 0
4 b 1
5 b 6
6 c 3
>>> pd.merge(df2,df1,on='key',how = 'outer')
key data1
0 a 2.0
1 a 4.0
2 a 5.0
3 b 0.0
4 b 1.0
5 b 6.0
6 d NaN
7 c 3.0

索引上的合并
有时候DataFrame中的连接件位于索引中,这是你可以传入left_index=True或right_index=True,用以说明索引应该被用作连接键:
>>> left1 = DataFrame({'key':['a','b','a','a','b','c'],'value':range(6)})
>>> right1 = DataFrame({'group_val':[3.5,7]},index=['a','b'])
>>> left1
key value
0 a 0
1 b 1
2 a 2
3 a 3
4 b 4
5 c 5
>>> right1
group_val
a 3.5
b 7.0
>>> pd.merge(left1,right1,left_on='key',right_index=True)
key value group_val
0 a 0 3.5
2 a 2 3.5
3 a 3 3.5
1 b 1 7.0
4 b 4 7.0
如过遇到层次化索引,你必须以列表的形式指明用作合并键的多个列。
同时使用双方的合并索引也没问题,即left_index=True,right_index=True
>>> import numpy as np
>>> lefth = DataFrame({'key1':['Onio','Onio','Onio','Neada','Nevada'],'key2':[2000,2001,2002,2001,2002],'data':np.arange(5.)})
>>> righth = DataFrame(np.arange(12).reshape((6,2)),index=[['Nevada','Nevada','Ohio','Ohio','Ohio','Ohio'],[2001,2000,2000,2000,2001,2002]],columns=['event1','event2'])
>>> lefth
data key1 key2
0 0.0 Onio 2000
1 1.0 Onio 2001
2 2.0 Onio 2002
3 3.0 Neada 2001
4 4.0 Nevada 2002
>>> righth
event1 event2
Nevada 2001 0 1
2000 2 3
Ohio 2000 4 5
2000 6 7
2001 8 9
2002 10 11
>>> pd.merge(lefth,righth,left_on=['key1','key2'],right_index=True)
Empty DataFrame
Columns: [data, key1, key2, event1, event2]
Index: []
轴向连接
使用concat可以将值和索引粘合在一起;
当传入的不是列表而是一个字典,则字典的键就会被当作keys选项的值
>>> def1 = DataFrame(np.arange(6).reshape((3,2)),columns=['one','two'],index=['a','b','c'])
>>> def2 = DataFrame(5+np.arange(4).reshape(2,2),index=['a','c'],columns=['three','four'])
level1 level2
one two three four
a 0 1 5.0 6.0
b 2 3 NaN NaN
c 4 5 7.0 8.0
合并重叠数据
有一种数据不能简单的合并或连接运算来处理,比如索引全部或部分重叠的数据集
>>> from pandas import DataFrame,Series
Backend TkAgg is interactive backend. Turning interactive mode on.
>>> import numpy as np
>>> a = Series([np.nan,2.5,np.nan,3.5,4.5,np.nan],index=['f','e','d','c','b','a'])
>>> b = Series(np.arange(len(a),dtype=np.float64),index=['f','e','d','c','b','a'])
>>> b[-1] = np.nan
>>> a
f NaN
e 2.5
d NaN
c 3.5
b 4.5
a NaN
dtype: float64
>>> b
f 0.0
e 1.0
d 2.0
c 3.0
b 4.0
a NaN
dtype: float64
>>> import pandas as pd
>>> np.where(pd.isnull(a),b,a)
array([0. , 2.5, 2. , 3.5, 4.5, nan])
>>> b[:-2].combine_first(a[2:])
a NaN
b 4.5
c 3.0
d 2.0
e 1.0
f 0.0
dtype: float64comdline_first合并即使使用后面的数据补全前面的数据,同时保持最大规格。
>>> df1 = DataFrame({'a':[1.,np.nan,5.,np.nan],'b':[np.nan,2.,np.nan,6.],'c':range(2,18,4)})
>>> df2 = DataFrame({'a':[5.,4.,np.nan,3.,7.],'b':[np.nan,3.,4.,6.,8.]})
>>> df1
a b c
0 1.0 NaN 2
1 NaN 2.0 6
2 5.0 NaN 10
3 NaN 6.0 14
>>> df2
a b
0 5.0 NaN
1 4.0 3.0
2 NaN 4.0
3 3.0 6.0
4 7.0 8.0
>>> df1.combine_first(df2)
a b c
0 1.0 NaN 2.0
1 4.0 2.0 6.0
2 5.0 4.0 10.0
3 3.0 6.0 14.0
4 7.0 8.0 NaN
>>> df2.combine_first(df1)
a b c
0 5.0 NaN 2.0
1 4.0 3.0 6.0
2 5.0 4.0 10.0
3 3.0 6.0 14.0
4 7.0 8.0 NaN
重塑和轴向旋转--重塑层次化索引
使用stack方法可以将DataFrame转换为Series
反之unstack,默认从内层开始,还可以传入参数
stack会默认过滤缺失数据,设stack(dropna=False)即可不过滤
>>> data = DataFrame(np.arange(6).reshape(2,3),index=pd.Index(['Onio','Colorado'],name='state'),columns=pd.Index(['one','two','three'],name='number'))
>>> data
number one two three
state
Onio 0 1 2
Colorado 3 4 5
>>> data.stack()
state number
Onio one 0
two 1
three 2
Colorado one 3
two 4
three 5
dtype: int32
>>> data.stack().unstack()
number one two three
state
Onio 0 1 2
Colorado 3 4 5
>>> data.stack().unstack('state')
state Onio Colorado
number
one 0 3
two 1 4
three 2 5
在对DataFrame进行unstack操作时,作为轴转换的级别将会是成为结果中的最低级别:
>>> df.unstack('state')
side left right
state Onio Colorado Onio Colorado
number
one 0 3 5 8
two 1 4 6 9
three 2 5 7 10
>>> df.unstack('state').stack('state')
side left right
number state
one Onio 0 5
Colorado 3 8
two Onio 1 6
Colorado 4 9
three Onio 2 7
Colorado 5 10
将长格式转换为宽格式
使用pivot(‘date','item','value')
数据转换--移除重复数据
>>> data = DataFrame({'k1':['one']*3+['two']*4,'k2':[1,1,2,3,3,4,4]})
>>> data
k1 k2
0 one 1
1 one 1
2 one 2
3 two 3
4 two 3
5 two 4
6 two 4
>>> data.duplicated()
0 False
1 True
2 False
3 False
4 True
5 False
6 True
dtype: bool
>>> data.drop_duplicates()
k1 k2
0 one 1
2 one 2
3 two 3
5 two 4去重方法默认保留第一个出现的集合。
>>> data['v1'] = range(7)
>>> data
k1 k2 v1
0 one 1 0
1 one 1 1
2 one 2 2
3 two 3 3
4 two 3 4
5 two 4 5
6 two 4 6
>>> data.drop_duplicates('k1')
k1 k2 v1
0 one 1 0
3 two 3 3
利用函数或映射进行数据转换
map方法是一种实现元素级转换以及其他数据清理工作的便捷方式
>>> meat_to_animal = {'bacon':'pig','pulled pork':'pig','pastrami':'cow','corned beef':'cow','honey ham':'pig','nova lox':'salmon'}
>>> data['animal'] = data['food'].map(str.lower).map(meat_to_animal)
>>> data
food ounces animal
0 bacon 4.0 pig
1 pulled pork 3.0 pig
2 bacon 12.0 pig
3 Pastrami 6.0 cow
4 corned beef 7.5 cow
5 Bacon 8.0 pig
6 pastrami 3.0 cow
7 honey ham 5.0 pig
8 nova lox 6.0 salmon
>>> data['food'].map(lambda x: meat_to_animal[x.lower()])
0 pig
1 pig
2 pig
3 cow
4 cow
5 pig
6 cow
7 pig
8 salmon
Name: food, dtype: object
替换值
除了fillna方法填充缺失值还有其他方法:
要替换多个值,传入待替换的列表即可,
>>> data = Series([1.,-999,2.,-999.,-1000.,3.])
>>> data
0 1.0
1 -999.0
2 2.0
3 -999.0
4 -1000.0
5 3.0
dtype: float64
>>> data.replace(-999,np.nan)
0 1.0
1 NaN
2 2.0
3 NaN
4 -1000.0
5 3.0
dtype: float64
>>> data.replace([-999,-1000],np.nan)
0 1.0
1 NaN
2 2.0
3 NaN
4 NaN
5 3.0
dtype: float64离散化和面元划分
为了便于分析,连续数据常常被离散化或拆分为“面元”。
>>> ages = [20,22,25,27,21,23,37,31,61,45,41,32]
>>> bins = [18,25,35,60,100]
>>> cats = pd.cut(ages,bins)
>>> cats
[(18, 25], (18, 25], (18, 25], (25, 35], (18, 25], ..., (25, 35], (60, 100], (35, 60], (35, 60], (25, 35]]
Length: 12
Categories (4, interval[int64]): [(18, 25] < (25, 35] < (35, 60] < (60, 100]]
pandas返回的是一个特殊的Categorical对象,你可以将其看作一组表示面元名称的字符串。
圆括号表示开端,方括号表示闭端,可设置改变方向。
>>> cats = pd.cut(ages,bins,right=False)
>>> cats
[[18, 25), [18, 25), [25, 35), [25, 35), [18, 25), ..., [25, 35), [60, 100), [35, 60), [35, 60), [25, 35)]
Length: 12
Categories (4, interval[int64]): [[18, 25) < [25, 35) < [35, 60) < [60, 100)]
csdes的内容是bins的元素索引组成的代表分类后的集合。
>>> cats.codes
array([0, 0, 0, 1, 0, 0, 2, 1, 3, 2, 2, 1], dtype=int8)也可以设置自己的面元名称。
>>> group_names=['Youth','YouthAdult','MiddleAged','Senior']
>>> pd.cut(ages,bins,labels=group_names)
[Youth, Youth, Youth, YouthAdult, Youth, ..., YouthAdult, Senior, MiddleAged, MiddleAged, YouthAdult]
Length: 12
Categories (4, object): [Youth < YouthAdult < MiddleAged < Senior]
如果向cut传入的是面元数量而不是确切的面元边界,则它会跟据最小值和最大值计算等长面元。
>>> data = np.random.randn(20)
>>> pd.cut(data,4,precision=2)
[(0.12, 0.9], (-0.66, 0.12], (0.12, 0.9], (0.12, 0.9], (0.9, 1.68], ..., (0.9, 1.68], (-0.66, 0.12], (0.9, 1.68], (-0.66, 0.12], (-0.66, 0.12]]
Length: 20
Categories (4, interval[float64]): [(-1.44, -0.66] < (-0.66, 0.12] < (0.12, 0.9] < (0.9, 1.68]]
qcut是一个非常类似于cut的函数,它可以根据样本分位数对数据进行面元划分,qcut使用的是样本分位数,所以可以得到大小基本相等的面元。
qcut同样可以设置自定义的分位数
>>> data = np.random.randn(1000)
>>> cats = pd.qcut(data,4)
>>> cats
[(0.71, 3.162], (-3.442, -0.603], (-3.442, -0.603], (-0.603, 0.117], (0.117, 0.71], ..., (-3.442, -0.603], (0.117, 0.71], (-3.442, -0.603], (0.71, 3.162], (0.71, 3.162]]
Length: 1000
Categories (4, interval[float64]): [(-3.442, -0.603] < (-0.603, 0.117] < (0.117, 0.71] < (0.71, 3.162]]
>>> pd.value_counts(cats)
(0.71, 3.162] 250
(0.117, 0.71] 250
(-0.603, 0.117] 250
(-3.442, -0.603] 250
dtype: int64
检测和过滤异常值
异常值的过滤和运算在很大程度上就是数组运算
>>> np.random.seed(12345)
>>> data = DataFrame(np.random.randn(1000,4))
>>> data.describe()
0 1 2 3
count 1000.000000 1000.000000 1000.000000 1000.000000
mean -0.067684 0.067924 0.025598 -0.002298
std 0.998035 0.992106 1.006835 0.996794
min -3.428254 -3.548824 -3.184377 -3.745356
25% -0.774890 -0.591841 -0.641675 -0.644144
50% -0.116401 0.101143 0.002073 -0.013611
75% 0.616366 0.780282 0.680391 0.654328
max 3.366626 2.653656 3.260383 3.927528
检测某列大于三的数据
>>> col = data[3]
>>> col[np.abs(col) > 3]
97 3.927528
305 -3.399312
400 -3.745356
Name: 3, dtype: float64含有‘3’的行
>>> data[(np.abs(data)>3).any(1)]
0 1 2 3
5 -0.539741 0.476985 3.248944 -1.021228
97 -0.774363 0.552936 0.106061 3.927528
102 -0.655054 -0.565230 3.176873 0.959533
305 -2.315555 0.457246 -0.025907 -3.399312
324 0.050188 1.951312 3.260383 0.963301
400 0.146326 0.508391 -0.196713 -3.745356
499 -0.293333 -0.242459 -3.056990 1.918403
523 -3.428254 -0.296336 -0.439938 -0.867165
586 0.275144 1.179227 -3.184377 1.369891
808 -0.362528 -3.548824 1.553205 -2.186301
900 3.366626 -2.372214 0.851010 1.332846通过下面的设置可以将值限定在-3到3之间
np.sign返回的是又1,-1组成的数组,即原始值的符号。
>>> data[np.abs(data) > 3] = np.sign(data)*3
>>> data.describe()
0 1 2 3
count 1000.000000 1000.000000 1000.000000 1000.000000
mean -0.067623 0.068473 0.025153 -0.002081
std 0.995485 0.990253 1.003977 0.989736
min -3.000000 -3.000000 -3.000000 -3.000000
25% -0.774890 -0.591841 -0.641675 -0.644144
50% -0.116401 0.101143 0.002073 -0.013611
75% 0.616366 0.780282 0.680391 0.654328
max 3.000000 2.653656 3.000000 3.000000排列和随机取样
>>> df = DataFrame(np.arange(5*4).reshape(5,4))
>>> sampler = np.random.permutation(5)
>>> sampler
array([1, 0, 2, 3, 4])
>>> df
0 1 2 3
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
3 12 13 14 15
4 16 17 18 19
>>> df.take(sampler)
0 1 2 3
1 4 5 6 7
0 0 1 2 3
2 8 9 10 11
3 12 13 14 15
4 16 17 18 19
如果不想用替换的方式选取子集,则可以直接使用permutation.
>>> df.take(np.random.permutation(len(df))[:3])
0 1 2 3
1 4 5 6 7
3 12 13 14 15
4 16 17 18 19
>>> df.take(np.random.permutation(len(df))[:len(df)])
0 1 2 3
1 4 5 6 7
3 12 13 14 15
0 0 1 2 3
2 8 9 10 11
4 16 17 18 19要通过替换方式产生样本,最快的方式是通过np.random.randint得到一组随机整数:
>>> bag = np.array([5,7,-1,6,4])
>>> sampler = np.random.randint(0,len(bag),size = 10)
>>> sampler
array([1, 1, 2, 3, 0, 1, 2, 2, 3, 2])
>>> draws = bag.take(sampler)
>>> draws
array([ 7, 7, -1, 6, 5, 7, -1, -1, 6, -1])
计算指标/哑变量
另一种常用与统计建模或机器学习的转换方式是:将分类变量转换为哑变量矩阵或指标矩阵。
如果DataFrame的某一列中含有k个不同的值,则可以派生出一个k列矩阵或DatFrame
>>> df = DataFrame({'key':['b','b','a','c','a','b'],'data1':range(6)})
>>> pd.get_dummies(df['key'])
a b c
0 0 1 0
1 0 1 0
2 1 0 0
3 0 0 1
4 1 0 0
5 0 1 0
使用get_dummies()可以给DataFrame列加上一个前缀
>>> dummies = pd.get_dummies(df['key'],prefix='key')
>>> df_with_dummy = df[['data1']].join(dummies)
>>> df_with_dummy
data1 key_a key_b key_c
0 0 0 1 0
1 1 0 1 0
2 2 1 0 0
3 3 0 0 1
4 4 1 0 0
5 5 0 1 0
字符串操作--字符串对象方法
>>> val = 'a,b,guido'
>>> val.split(',')
['a', 'b', 'guido']
>>> pieces = [x.strip() for x in val.split(',')]
>>> pieces
['a', 'b', 'guido']
>>> '::'.join(pieces)
'a::b::guido'
>>> 'guido' in val
True
>>> val.count(',')
2
>>> val.replace(',','::')
'a::b::guido'


正则表达式 regex
re模块函数可以分为三个大类:模式匹配,替换,及拆份,他们之间相辅相成。
>>> import re
>>> text = 'foo bar\t baz \tqux'
>>> re.split('\s+',text)
['foo', 'bar', 'baz', 'qux']
>>> regex = re.compile('\s+')
>>> regex.split(text)
['foo', 'bar', 'baz', 'qux']

python正则表达式的详细用法会另写一篇文章。
pandas中矢量化的字符串函数
>>> data = {'Dave':'[email protected]','Steve':'[email protected]','Rob':'[email protected]','Wes':np.nan}
>>> data = Series(data)
>>> data
Dave [email protected]
Rob [email protected]
Steve [email protected]
Wes NaN
dtype: object
我们可以通过str.contains()检查是否含有目标字符串
>>> data.str.contains('gmail')
Dave False
Rob True
Steve True
Wes NaN
dtype: object
操作数量化字符串
>>> data.str[:5]
Dave dave@
Rob rob@g
Steve steve
Wes NaN
dtype: object
