了解关系型数据库的童靴都了解它底层结构采用b+tree的实现,而Lucene则是基于反向索引实现,并将它发挥到了极致。如果不了解Lucene是什么,可以参阅《系列一之全文检索》
1. 什么是反向索引
反向索引英文名叫做 Inverted index,顾名思义,是通常意义下索引的倒置,词到文章id的索引,这就是:反向索引(Inverted index)。举个例子:
| 1 | I love you |
| 2 | I love you too |
| 4 | I dislike you |
如果要用单词作为索引,而句子的位置作为被索引的元素,那么索引就发生了倒置:
I : {1,2,3}
love : {1,2}
you : {1,2,3}
dislike : {3}
如果要检索I dislike you这句话,那么就可以这么计算 : {1,2,3} ^ {3} ^ {1,2,3} (^是交集)
2. 如何创建索引
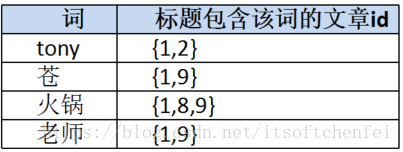
2.1 如何快速查询与苍老师有关的新闻?
分析:输入的是苍老师,想要得到标题或内容中包含“苍老师”的新闻列表。
标题列索引:
内容列索引:

那如果是这样的文章呢?
| id | 标题 | 新闻内容 |
| 1 | Tony 与苍老师一起吃火锅 | 2018年4月1日,Tony 在四川成都出席某活动时,碰巧主办方也邀请了苍老师来提高人气,在主办方的邀请下和苍老师一起吃了个火锅,很爽! |
如果是英文文章(It’s one thing to find the 10 best documents to match your query)好不好分?英文好分(有空格)。
中文则不好分,一定分的话,就必须写一套专门的程序来做这个事情:分词器(有个词的字典,对语句前后字进行组合,与字典匹配,歧义分析)。
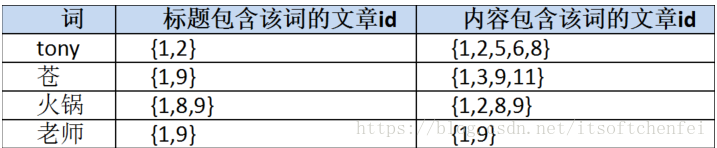
2.2 有标题列索引和内容列索引会有什么问题
两个索引需要合并,好处是:可以减少访问数据库的次数
2.3 反向索引的记录数【英文/中文】会不会很大
| 英语 | 单词的大致数量是10万个 |
| 汉字 | 汉字的总数已经超过了8万,而常用的只有3500字,《现代汉语规范词典》比《现代汉语词典》收录的字和词数量更多。 前者是13000多字,72000多词,后者是11000多字,69000多词 |
结论:量不会很大,30万以内;通过这个索引找文章会很快
2.4 开源中文分词器有哪些
准确率、分词效率、中英文混合分词支持,常用中文分词器有:IKAnalyzer、mmseg4j
2.5. 你、我、他、my、she、it、标点符号怎么办
这些词称为:停用词。分词器支持指定/添加停用词,不需要为其创建索引
2.6.当出现了新词了该怎么办
撩妹 老司机、软妹子、直男、腿玩年、苍老师...
分词器应支持为其词典添加新词
总结
我们创建反向索引,大概如下所示:

3. 如何进行搜索
搜索与 “tony OR 苍老师” 相关的新闻,怎么做?
Step 1: 对搜索输入进行分词,得到:tony 、苍老师
Step 2:在反向索引中找出包含tony、苍老师的文章列表
Step3:合并两个列表,排序输出
4. 反向索引是存储在内存中还是磁盘
大的放磁盘,小的放内存,同时需要做持久化
5.反向索引更新问题
问1:新增时,需要怎么更新?
问2:删除时,需要怎么更新?
问3:修改时,需要怎么更新?
搜索引擎的工作原理是:
- 从数据源加载数据,分词、建立反向索引
- 搜索时,对搜索输入进行分词,查找反向索引
- 计算相关性,排序,输出