文章目录
一、前言
倒排索引是全文检索的根基,理解了倒排索引之后才能算是入门了全文检索领域。倒排索引的的概念很简单,也很好理解。但如你知道在全文检索领域Lucene可谓是独领风骚。所以你真的了解Lucene的倒排了吗?Lucene是如何实现这个结构的呢?
倒排索引如此重要,深入理解索引结构显然是非常有益的,对于理解Lucene的索引和搜索流程都非常关键,进而可以参与自定义搜索统计的计算函数扩展开发。
本文我们将对Lucene的倒排索引的实现原理和技术细节展开具体的研读和剖析。
二、理论
在学术上,倒排索引结构非常简明,非常好理解。如下
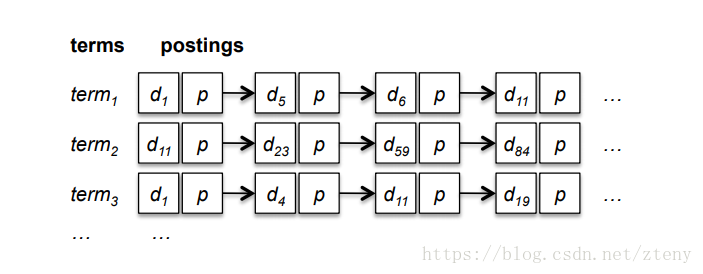
也许你已经很了解倒排索引了,下面这张图你也已经看过很多次了。本文将从你熟悉的部分开始,一步步深入去扣这张图的一个个细节。这里有二部分内容对应分别称之为:
- 索引,索引词表。倒排索引并不需要扫描整个文档集,而是对文档进行预处理,识别出文档集中每个词。
- 倒排表,倒排表中的每一个条目也可以包含词在文档中的位置信息(如词位置、句子、段落),这样的结构有利于实现邻近搜索。词频和权重信息,用于文档的相关性计算。
倒排索引由两部分组成,所有独立的词列表称为索引,词对应的一系列表统称为倒排表。
—— 来自《信息检索》
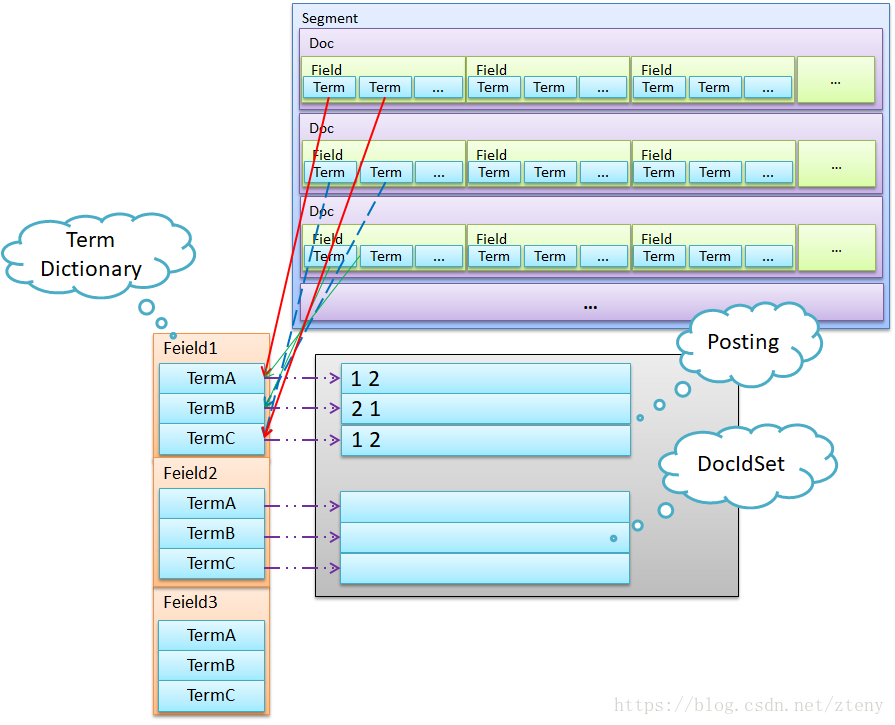
如图,整个倒排索引分两部分,左边是Term Dictionary,我们就叫Dictionary吧;右边是Postings List。
- 索引表,叫
Terms Dictionary,是由于一系列的Term组成的。 - 倒排表,称
Postings List,即是由所有的Term对应的Postings组成的。
实际上Lucene所用的信息信息检索方面的术语基本跟Information Retrieval(《信息检索》原版)保持一致。比如Term、Dictionary、Postings等。
首先,有必须解释一下,每个Segment中的每个字段(Field)都有这么一个结构,且相互独立。其次,她是不可变的,即是不能添加和更改。至于不可变的原因很多,简单说有两方面:一方面是更新对磁盘来说不够友好;另一方面是写性能的影响,同时还引发各种并发问题。
我们先这么来想这个问题,如果用HashMap来实现这个结构,非常贴近这个结构了。这个结构应该是这样的,Map<String, List<Integer>>。这个Map的Key的即是Term,那它的Value即是Postings。所以它的Key的集合即是Dictionary了,这与上图的结构太贴切了。由于HashMap的Key查找还是用了HashTable,所以它还解决Dictionary的快速查找的问题,这真的是太美好了。
这就是一个hello world版的倒排索引的实现了。
三、Lucene的实现
全文搜索引擎通常是需要存储大量的文本,不仅是Postings可能会是非常巨大,同样Dictionary的大小极可能也是非常庞大。因此上面说的实现方式是完全不可能的,真正的搜索引擎的倒排索引实现都极其复杂,因为它直接影响了搜索性能和功能。
实际上Lucene的索引实现也是几经升级优化,每个版本都有或大或小的差异,这里只看Lucene6.x/7.x的实现。
Lucene的实现非常高级,它的关键特性是能够将整个排索引系列化存储在磁盘上,同时它必须是能够满足快速读写的需求。Lucene为了极致的搜索体验,引用多种数据结构和算法。倒排索引变得高效又复杂的同样,给我们带来一次研读和剖析的机会。
四、Lucene索引文件初印象
我们知道Lucene将索引文件拆分为了多个文件,这里我们仅讨论倒排索引部分。Lucene把用于存储Term的索引文件叫Terms Index,它的后缀是.tip;把Postings信息分别存储在.doc、.pay、.pox,分别记录Postings的DocId信息和Term的词频、Payload信息、pox是记录位置信息。Terms Dictionary的文件后缀称为.tim,它是Term与Postings的关系纽带,存储了Term和其对应的Postings文件指针。
总体来说,通过Terms Index(.tip)能够快速地在Terms Dictionary(.tim)中找到你的想要的Term,以及它对应的Postings文件指针。当然还有Term在Segment作用域上的统计信息。
postings: 实际上Postings包含的东西并不仅仅是DocIDs(我们通常把这一个有序文档编号系列叫DocIDs),它还包括文档编号、以及词频、Term在文档中的位置信息、还有Payload数据。
所以关于倒排索引至少涉及5个文件,当然这里不含括(Norms信息和TermVector信息)。
五、 什么是Terms Index
下图我们贴张来自网络的图,我觉得这图非常好。

即是图中.tip部分,Terms Index实际上一个或者多个FST组成的,Segment上每个字段都有自己的一个FST(FSTIndex)记录在.tip上。所以图中FSTIndex的个数即是Segment拥有字段的个数。另外图中为了方便我们理解把FST画成Trie结构,然后其叶子节点又指向了tim的Block的,这实际上是用一种叫Burst-Trie的数据结构。
1. Burst-Trie
.tip看起来是像一棵Trie,所以整张图表现出来就是论文上的Burst-Trie结构了。上面一棵Trie,Trie的叶子节点是Container(即是Lucene中的Block)。非常简单这就是Paper上描述的Burst-Trie的结构,然而Lucene的实现上跟这个还是有一些差异。

来自Burst-Trie论文上的一张图
Burst-Trie,具体能可以拜读一下论文的原文,这里只做简单描述。Burst-Trie可以认为是Trie的一种变种,它主要是将后缀进行了压缩,降低了Trie的高度,从而获取更好查询性能。

由于我们还没有开始介绍FST,然后先把Lucene工程上的实现理解成上图结构。
Burst-Trie在Lucene应用在那里呢?
显然,Lucene是采用Burst-Trie的思想,但在实现上并不是特别一致。甚至可以说出入还比较大,Lucene的Burst-Trie拆成两部分。如果一定把它们对应起来的话,我认为Burst-Trie的AccessTree的实现是FST,在.tip里;Container的实现是Block,在.tim里。Burst-Trie论文上提到Container是开放性结构,可能是Binary-Tree,也可以是List。Lucene的block是数组,准确的说,就是把一系列的Block系列化写到文件上。这里好像并没有特殊的处理。
2. FST
在Lucene,Terms Dictionary被存储在.tim文件上。当一个Segment的文档数量越来越多的同时Dictionary的词汇也会越来越多,那查询效率必然也会慢慢变低。如果有一个很好的结构也为Dictionary建构一个索引,将Dictionary的索引进一步压缩,这就是后来的Terms Index(.tii)。这是在早期的版本中使用的,到Lucene4.0做一次重构和升级,同时改名为.tip。

FST:Finite-State-Transducer,结构上是图。我们知道把一堆字符串放一起并左对齐,把它们的同共前缀进行压缩就会变成Burst-Trie。如果把后缀变成一个一个节点,那么它就是Trie结构了。如果将后缀也进行压缩的话,那你就能发现他更变成一张图结构了。
那么我们易知FST是压缩字典树后缀的图结构,她拥有Trie高效搜索能力,同时还非常小。这样的话我们的搜索时,能把整个FST加载到内存。
那实际上FST的结构实际相当复杂,这里我们简单的理解为一个高效的K-V结构,而且空间占用率更高。也就是FST能提供类似Map的功能,这里可以先这么理解,实际上它别的重大功能。
反正,此时你只需要知道FST是一种非常厉害的数据结构就可以了。甚至为了能够更好的理解它在倒排索引结构和Burst-Trie结构上功能,你把它错误当成是Trie都没有问题的呢。这里我们先不做太详细的介绍了,有机会单独拎出来讲。
此外,我还想多说一句Lucene到底把什么东西放在FST里了呢? 关于FST里面装了什么东西,如果你已经了解FST在Lucene中充当的角色和作用的话,我想你应该会误以为是拿Dictionary中所有Term来构建FST的。即是通过FST是可以找具体的Term的位置,或者通过FST可以切切的知道Terms是否存在。
然而,事实并非如此。 FST即不能知道某个Term在Dictionary(.tim)文件上具体的位置,也不能仅通过FST就能切切的知道Term是否真实存在。它只能告诉你,查询的Term可能在某个或者几个Block上,到底有没有、存不存在FST并不完全知情,还需要通过读取Block的内容才能确定。因为FST是通过Dictionary的每个Block的前缀构成,所以通过FST只可以直接找到这个Block在.tim文件上具体的File Pointer,并无法直接找到Terms。
- FST是字段级别的,在Segment上每个字段有且仅有一张FST图。
- FST最终只能指向一个Block的起始位置,并不能指向具体的一个Term。
下面会详细的介绍Dictionary的文件结构,这里先提一下。每个Block都有前缀的,Block的每个Term实际不记录共同前缀的。只有通过Block的共同的前缀,这是整个Block的所有Term共有的,所以每个Term仅需要记录后缀可以通过计算得到,这可以减少在Block内查找Term时的字符串比较的长度。这也是Burst-Trie主要思想。
简单理解的话,你可以把她当成一个高级的BloomFilter,我们BloomFilter是有一定的错误率的;同时BloomFilter是通过HashCode实现的,只能用她来测试是否存在,并无法快速定位。在FST中,并无错误率且能快速定位。但是BloomFilter有更高的性能。
说了这么一大半天,Terms Index到底带来哪些实质性的功能呢? Terms Index是Dictionary的索引,它采用 了FST结构。上面已经提及了,FST提供两个基本功能分别是:
- 快速试错,即是在FST上找不到可以直接跳出不需要遍历整个Dictionary。类似于BloomFilter的作用。
- 快速定位Block的位置,通过FST是可以直接计算出Block的在文件中位置(offset,FP)。实现了HashMap的功能。
相当于Terms Index也拥有了上述两大能力。
上面已经介绍了FST的一种功能,此外,FST还有别的功能,因为FST也是Automaton,自动状态机。这是正则表达式的一种实现方式,所以FST能提供正则表达式的能力。通过FST能够极大的提高近似查询的性能,包括通配符查询、SpanQuery、PrefixQuery等,甚至是近期社区现在做的正则表达式查询。
六、什么是Terms Dictionary
前面我们已经介绍了Terms Dictionary的索引,Terms Index。已经频频提到的Terms Dictionary到底是个什么东西呢?是的,Terms Dictionary是Segment的字典,索引表。它能够让你知道你的查询的这个Term的统计信息,如tf-idf中df(doc_freq)和Total Term Frequence(Term在整个Segment出现频率);还能让你知道Postings的元数据,这里是指Term的docids、tf以及offset等信息在Postings各个文件的文件指针FP。
Block并不记录这个Block的起始和结束的范围,所以当FST最终指向多个Block时,就会退化线性搜索。那什么时候会出现FST最终指向多个Block呢?最简单的一种情况是,你超过48个的Term,且出现首字母相同的term的个数不超过25个。这种情况下由于没有每个Block都没有共同前缀,所以构建出来的FST只有一个结束节点记录每个Block的文件寻址的偏移增量。
Lucene规定,每个Block的大小在25-48范围内。
说这么多,还是觉得太抽象了,先来看一下.tim文件结构示意图。

主要是大两部分信息,1. 是Block信息,包含所有Term的详情;2. 是Field的自有属性和统计信息。接下来我们将展开来介绍这两部分内容。
1. Block信息 – NodeBlock
在整个.tim文件上,我觉得比较复杂、需要拎出来讲的只有NodeBlock。即是Block是什么东西,又是怎么被构建的呢?实际上这两部分代码我读得起来是感觉挺晦涩的,每次读都有会不同的疑问,所以在阅读的过程中一直在自问为什么,是什么东西。我觉得这也是一种阅读代码比较的方式方法吧。
我们前面所有说的Block即是NodeBlock的一个Entry。
由上图可以知道,Block中有两种OuterNode和InnerNode。这里我想引用代码上两个类名来辅助我们接下来的剖析:PendingTerm/PendingBlock,我们暂且把它们叫作待写的Term和子Block的指针吧。
NodeBlock从构建逻辑上来讲是它是树型结构,所以它由叶子节点和非叶子节点两种节点组成。叶子节点就叫OutterNode,非叶子节点就叫InnerNode。一个Block可能含有一堆的Term(PendingTerm)和PendingBlock(当它是非叶子节点时),实际上PendingBlock也是不可能出现在叶子节点上的。如果是PendingBlock,那么这个Entry只记录两个信息:后缀(这个Block的共同后缀)以及子Block的文件指针,此时就不必再记上所说的统计信息和postings信息了。

如图所示,一个Block记录的信息非常多,首先它会告诉你这个Block的类型和Entry的条数,然后依次写入这个Block拥有的所有Entry。

这里每个Entry含有后缀、统计信息(对应为前面据说的权重,它含有ttf和df)、Postings的位置信息(这就是反复提及postings相关的文件指针,postings是拆分多文件存储的)。
关于Postings更多细节,放到下个节来讨论。
2. Field信息 – FieldMetadata
相对来说FieldMetadata组织结构就相对简单很多了,就是纯粹线性写入便是了。但是Field信息记录的内容实际上也是挺多的,包括字段本身的属性,如字段编号、Terms的个数、最大和最小的Terms;此外还记录了Segment级别的一些统计信息,包括tdf、拥有该字段的文档总数(如果文档没有这字段,或者字段为空就不计了)。
- RootCode实际上指向该字段第一个Block的文件指针。
- LongsSize这个名字有点隐晦,它是说该字段的字段存储哪些Postings信息。因为我们是可以指定Postings存储或者不存储诸如位置信息和Payload信息的,存与不存将被表现在这里了。
从搜索流程上,Lucene先读到FieldMetadata的信息,然后判断Query上Terms是否落在这里字段的MinTerm和MaxTerm之间。如果不在的话,完全不需要去读NodeBlock的。MinTerm和MaxTerm可以有效的避免读取不必要的.tip。
七、结束语
到这里关于倒排索引结构中第一部分当就全部读完了吧,更多有意思的小细节可以去扣的。由于篇幅的原因,就到这里了吧。
总结一下,我们先从Information Retrieve开始了解学术上倒排索引结构,接着我们又对Luecne实现进行深入剖析。Lucene对索引词表也做了索引(叫Terms Index,文件后缀是.tip),索引词表的索引采用Finite-State Transducer这种数据结构。由于这种结构占用空间极小,所以它完成可以被加载到内存加速Terms Dictionary的查找过程。
然后又看Terms Dictionary,Terms Dictionary以Terms Index共同构成与Burst-Trie类似的数据结构,Terms Dictionary含两部分信息。1. NodeBlock记录Dictionary的所有Terms;2. FieldMetadata存储了FieldInfos信息和Segment的统计信息。
关于倒排索引还有Postings List,这部分内容将留到下篇《Lucene倒排索引简述 之倒排表》来介绍。