在实际应用中,很多应用程序保持多个分离的Lucene索引,但有需要在搜索过程中能够将结果合并输出,比如新闻网站每天都会建立不同索引,但是搜索一个月的新闻时就需要合并输出结果。这时可以使用如下方式:
mreader = new MultiReader(readera,readern);
searcher = new IndexSearcher(mreader);//4.0以后的MultiSearcher替换成这样可以看到我们需要使用MultiReader这个类,将读不同索引的reader封装在一块。
下面是实现代码
import java.io.IOException;
import junit.framework.TestCase;
import org.apache.lucene.analysis.*;
import org.apache.lucene.analysis.core.*;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.StringField;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.MultiReader;
import org.apache.lucene.search.*;
import org.apache.lucene.store.*;
public class MultiSearcherTest extends TestCase{
private static IndexSearcher searcher;
static IndexReader readera;
static IndexReader readern;
static MultiReader mreader;
public static void testMulti() throws IOException{
String[] animals = {
"aardvark","beaver","coati","dog",
"elephant","frog","gila monster",
"horse","iguana","javelina","kangroo",
"lemur","moose","rematode","orca",
"python","quoka","rat","scorpion",
"tarantula","uromastyx","vicuna",
"walrus","xiphias","yak","zebra"
};
Analyzer analyzer = new WhitespaceAnalyzer();
Directory aTOmDirectory = new RAMDirectory();//建立两个目录
Directory nTOzDirectory = new RAMDirectory();
IndexWriterConfig configa = new IndexWriterConfig(analyzer);
IndexWriterConfig confign = new IndexWriterConfig(analyzer);
IndexWriter aTOmWriter = new IndexWriter(aTOmDirectory,configa);
IndexWriter nTOzWriter = new IndexWriter(nTOzDirectory,confign);
for(int i = animals.length - 1;i >= 0;i--){
Document doc = new Document();
String animal = animals[i];
doc.add(new StringField("animal",animal,Field.Store.YES));
if(animal.charAt(0) < 'n'){
aTOmWriter.addDocument(doc);
}else{
nTOzWriter.addDocument(doc);
}
}
readera = DirectoryReader.open(aTOmWriter,true);
readern = DirectoryReader.open(nTOzWriter,true);
aTOmWriter.close();
nTOzWriter.close();
mreader = new MultiReader(readera,readern);
searcher = new IndexSearcher(mreader);//4.0以后的MultiSearcher替换成这样
TermRangeQuery query = TermRangeQuery.newStringRange("animal","h","t",true,true);
TopDocs hits = searcher.search(query, 10);
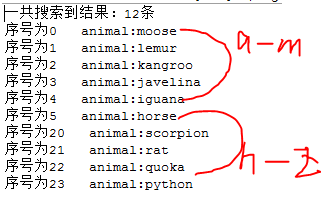
System.out.println("一共搜索到结果:"+hits.totalHits+"条");
for(ScoreDoc s:hits.scoreDocs){
Document doc = searcher.doc(s.doc);//通过序号得到文件
System.out.println("序号为"+s.doc+" "+"animal:"+doc.get("animal"));
}
assertEquals("tarantula not included",12,hits.totalHits);
}
public static void main(String args[]) throws IOException{
testMulti();
}
}
TermRangeQuery类查询包含从h到t开头的动物名称,匹配的文档来自于两个不同的索引。结果如下:
当然上面程序是一个searcher单线程操作,也可以使用多线程的办法,lucene5中提供了ParalleLeafReader类。