此处对比批量梯度下降、随机梯度下降、小批量梯度下降算法的优缺点
| 算法 | 批量梯度下降(Batch Gradient Descent, BGD) | 随机梯度下降(Stochastic Gradient Descent, SGD) |
|---|---|---|
| 代价函数 | 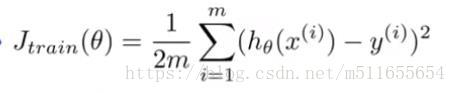 |
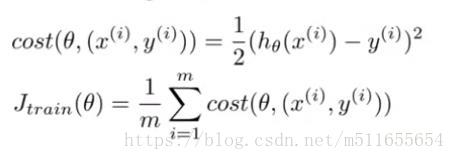 |
| 梯度下降算法 | 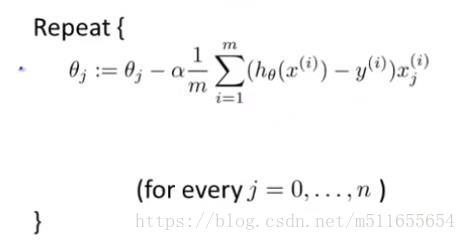 |
 |
| 比较 | 每一次更新参数θ时,都需要计算所有m个训练样本的差平方项求和,然后更新一次θ值,当m很大时,每一次迭代计算量大,且只能更新优化一小步 | 每一次更新参数θ时,不需要对所有m个训练样本的差平方项求和,只需要计算当前一个训练样本,然后更新一次θ,每一次迭代只要保证对一个样本拟合很好就行了 |
| 优点 | 参数基本以直线式方向朝着全局最小值的方向更新,最终达到收敛 | 每次迭代只需使用一个训练样本,当m很大时,训练速度快,计算量小 |
| 缺点 | 每次迭代都需要用到m个训练样本,当m很大时,训练速度慢,计算成本高 | 一般来讲,参数朝着全局最小值的方向更新,但也不一定,会以某个比较随机的、迂回的路径朝全局最小值逼近,并在最小值点附近徘徊,并非直接逼近最小值点并停留在该点上,但这也基本满足了我们实际应用的目的了 |
| 算法 | 小批量梯度下降(Mini-Batch Gradient Descent) |
|---|---|
| 代价函数 | 此处,m=b |
| 梯度下降算法 |  |
| 比较 | 每一次更新参数θ时,需要计算b个训练样本,然后更新一次θ,每一次迭代只要保证对b个样本拟合很好就行了 |
| 优点 | 每次迭代都需要用到b个训练样本(通常b=10,变化范围在2-100之间),算法介于BGD和SGD之间,当m很大时,当拥有一个很好的向量化实现时(能够支持并行计算),有时速度比SGD更快 |
| 缺点 | 增加了一个额外参数b,需要花时间确定参数b的大小 |
当SGD在全局最小值点附近振荡时,通过调试算法、选取学习率α来绘制图表,监测梯度下降是否收敛。
在随机梯度下降中,我们在每一次更新 θ 之前都计算一次代价,然后每 x 次迭代后,求出这 x 次对训练实例计算代价的平均值,然后绘制这些平均值与 x 次迭代的次数之间的函数图表。
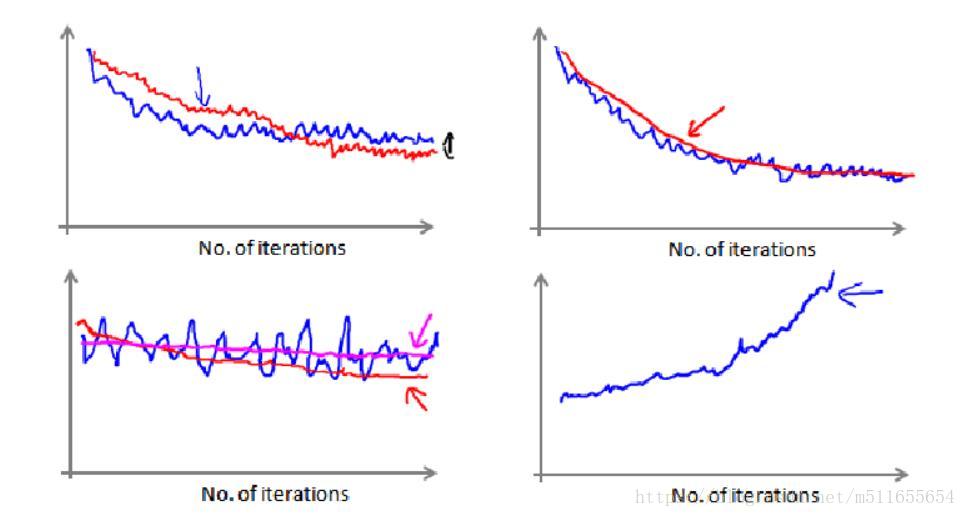
当我们绘制这样的图表时,可能会得到一个颠簸不平但是不会明显减少的函数图像(如上面左下图中蓝线所示)。我们可以增加 α 来使得函数更加平缓,也许便能看出下降的趋势了(如上面左下图中红线所示);或者可能函数图表仍然是颠簸不平且不下降的(如洋红色线所示),那么我们的模型本身可能存在一些错误。
通常学习速度α是不变的,但可以通过修改α(在逼近全局最小值点时,α减小)的方式来收敛到全局最小值点。

随着不断地靠近全局最小值,通过减小学习率,我们迫使算法收敛而非在最小值附近徘徊。但是通常我们不需要这样做便能有非常好的效果了,对α进行调整所耗费的计算通常不值得 。
总结:
这种方法不需要定时地扫描整个训练集,来算出整个样本集的代价函数,而是只需要每次对最后 1000 个,或者多少个样本,求一下平均值。应用这种方法,你既可以保证随机梯度下降法正在正常运转和收敛,也可以用它来调整学习速率 α 的大小。