前言
前面我们学习了机器学习一种最重要的优化方式——梯度下降法(也就是批量梯度下降法)这种方法很好的对我们的数据进行拟合,通过合适的代价函数来求解函数的权值,从而得到我们的算法模型。但是这种方法也有缺点,下面来学习下梯度下降法的细节。
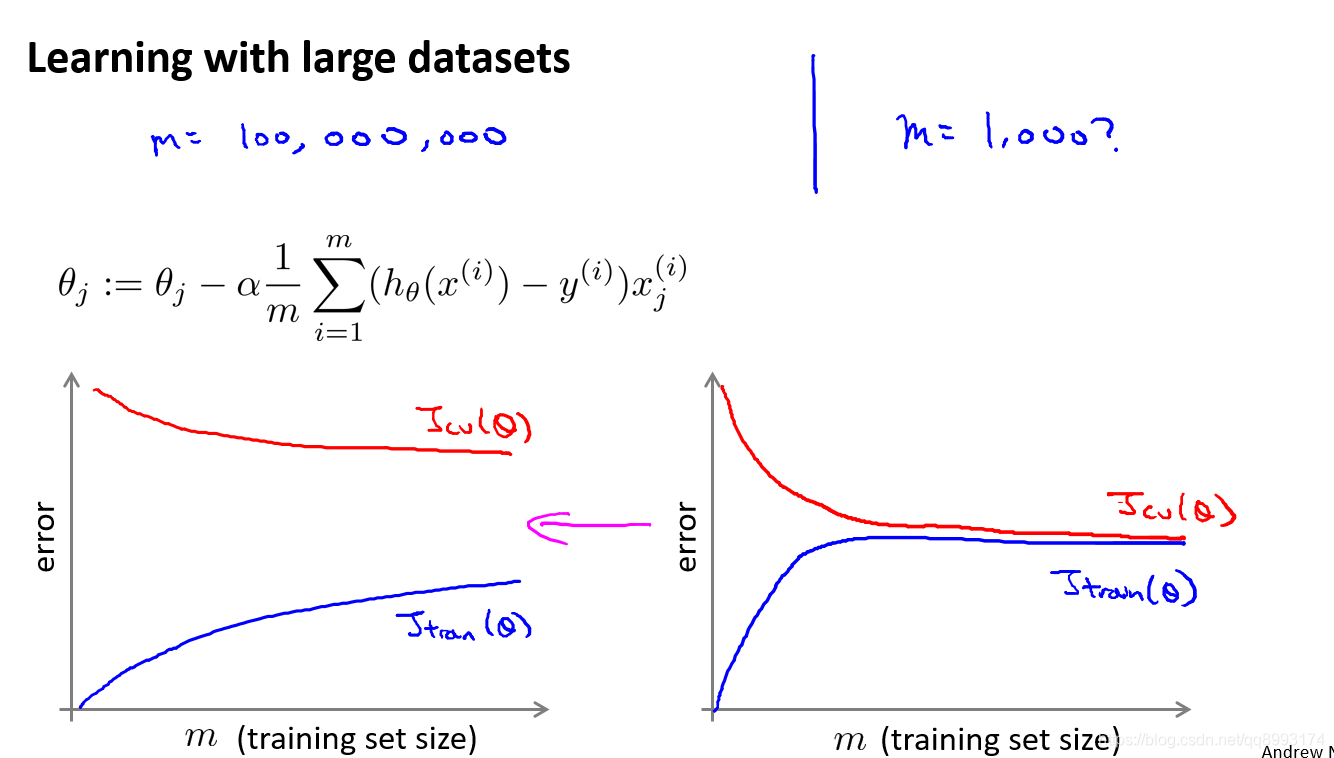
一、大数据集的学习
假设我们有一个亿级的数据集,如m = 100 000 000,以线性回归模型为例,每一次梯度下降迭代,我们都需要计算训练集的误差的平方和,如果我们的学习算法需要有 20 次迭代,那就是20 * 100 000 000的运算次数。这便已经是非常大的计算代价,所以针对大数据集的学习,用批量梯度下降法有待考量。
二、几种梯度下降法
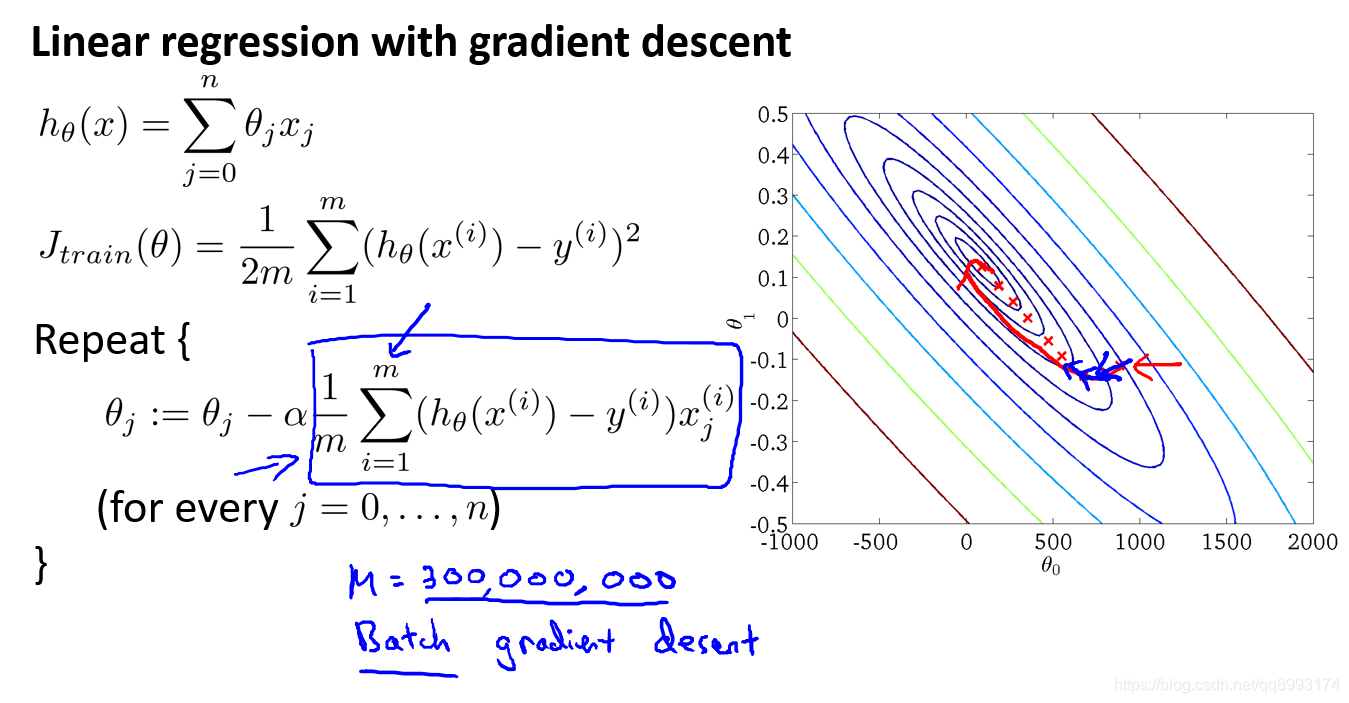
1、批量梯度下降法
批量梯度下降法(Batch Gradient Descent)简称为BGD,就是我们前面学习的方法,它是指在每一次迭代时使用所有样本来进行梯度的更新。
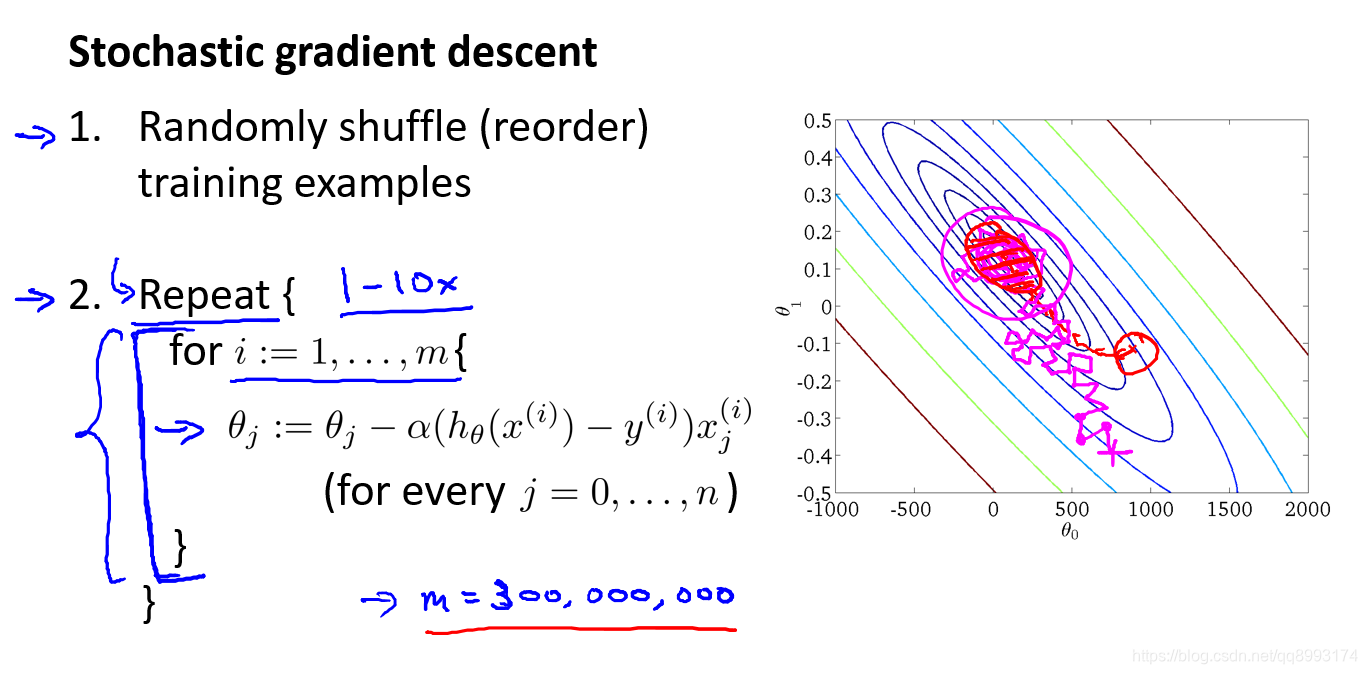
2、随机梯度下降法
随机梯度下降法(Stochastic Gradient Descent,简称SGD)不同于批量梯度下降,随机梯度下降是每次迭代使用一个样本来对参数进行更新。使得训练速度加快。具体做法为首先对训练集随机“洗牌”, 随机梯度下降算法在每一次计算之后便更新参数 θ ,而不需要首先将所有的训练集求和,在梯度下降算法还没有完成一次迭代时,随机梯度下降算法便已经走出了很远。但是这样的算法存在的问题是, 不是每一步都是朝着”正确”的方向迈出的。 因此算法虽然会逐渐走向全局最小值的位置,但是可能无法站到那个最小值的那一点,而是在最小值点附近徘徊。
3、小批量梯度下降法
小批量梯度下降法(Mini-Batch Gradient Descent,简称MBGD)是介于批量梯度下降算法和随机梯度下降算法之间的算法,每计算常数b次训练实例, 便更新一次参数 θ 。

4、在线学习
在线学习(online learning)有点类似上述讨论的随机梯度下降法。如假使我们正在经营一家物流公司,每当一个用户询问从地点 A 至地点 B 的快递费用时,我们给用户一个报价,该用户可能选择接受(y = 1)或不接受(y = 0)。现在,我们希望构建一个模型,来预测用户接受报价使用我们的物流服务的可能性。因此报价 是我们的一个特征,其他特征为距离,起始地点,目标地点以及特定的用户数据。模型的输出是:p(y = 1)。在线学习的算法与随机梯度下降算法有些类似,我们对单一的实例进行学习,而非对一个提前定义的训练集进行循环。

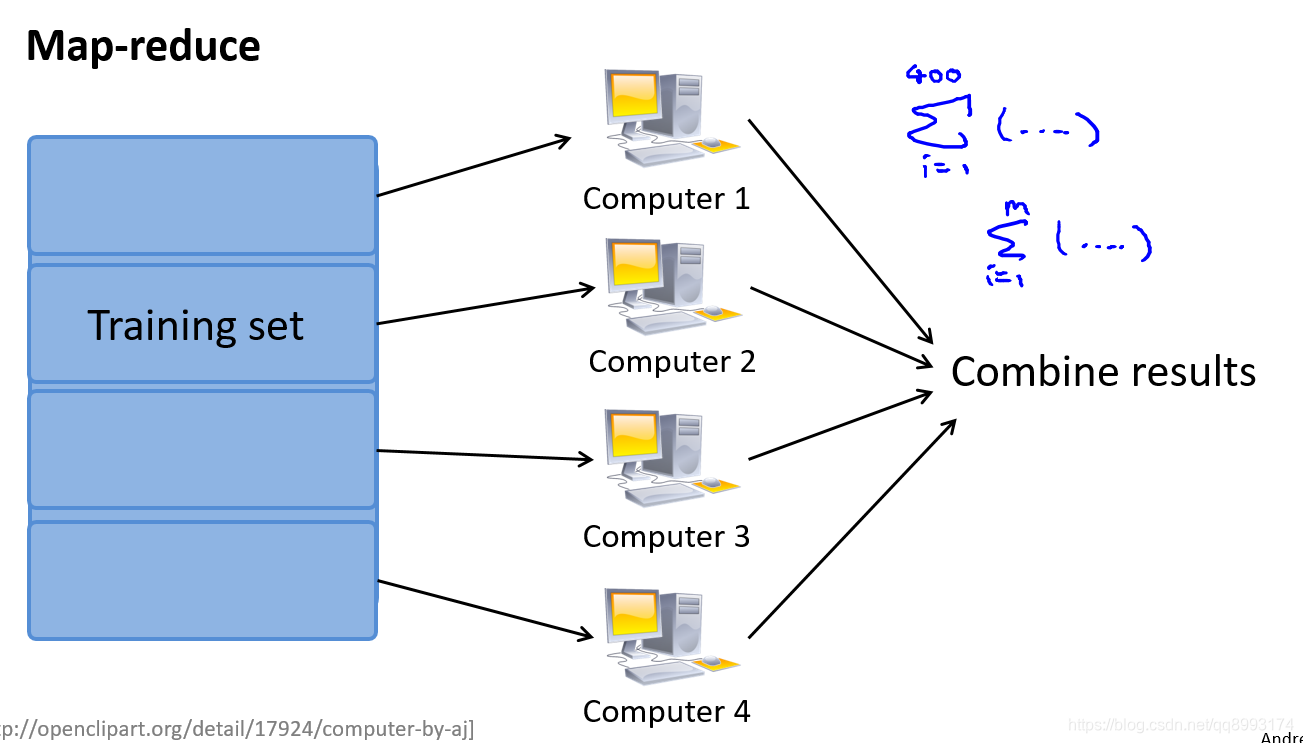
三、数据并行
如果我们用批量梯度下降算法来求解大规模数据集的最优解,我们需要对整个训练集进行循环,计算偏导数和代价,再求和,计算代价非常大。如果我们能够将我们的数据集分配给不多台计算机,让每一台计算机处理数据集的一个子集,然后我们将计所的结果汇总在求和。这样的方法叫做映射简化。例如,我们有 400 个训练实例,我们可以将批量梯度下降的求和任务分配给 4 台计算机进行处理
总结
以上就是《吴恩达机器学习》系列视频 大规模机器学习 的内容笔记,以便后续学习和查阅。