提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
十五、大规模机器学习
我们已经知道,得到一个高效的机器学习系统的最好的方式之一是,用一个低偏差(low bias)的学习算法,然后用很多数据来训练它。
但是同样的,当有着大量的训练数据时,会导致以下问题对于梯度下降,我们的计算量非常大,由此也就导致我们的时间消耗非常大。(建立在低偏差的问题上)
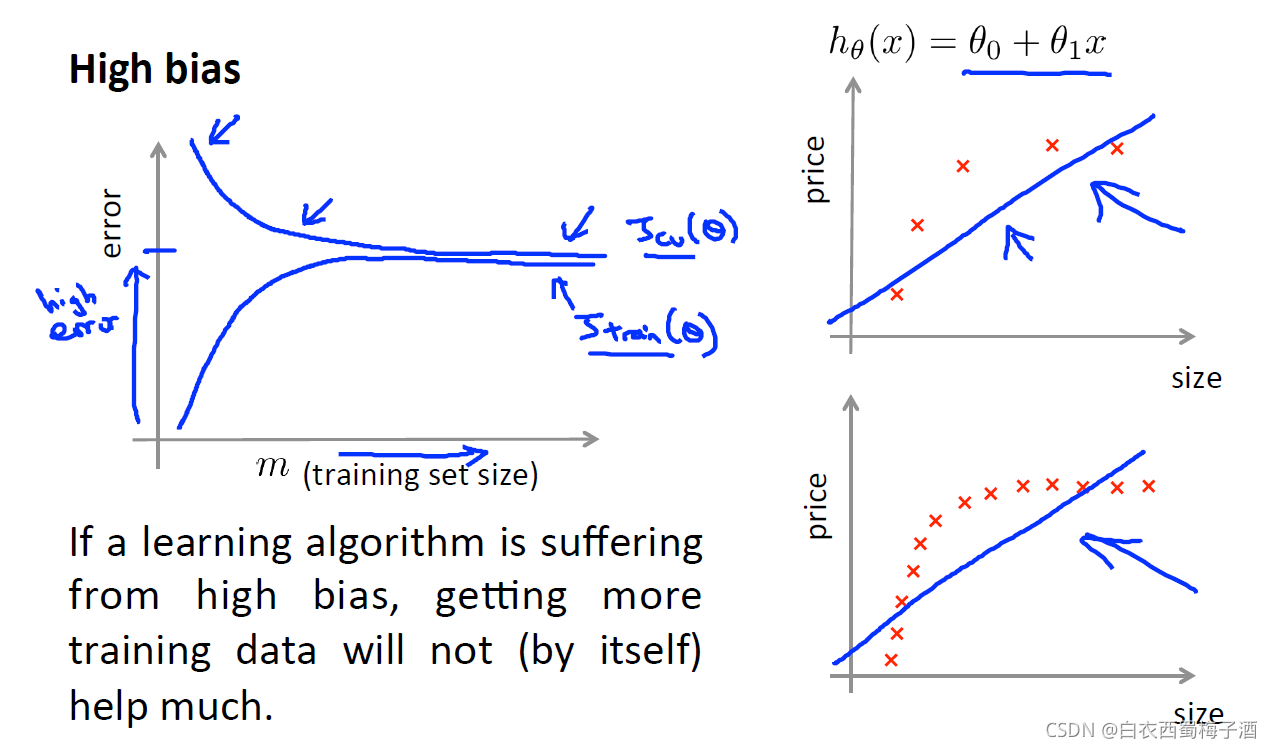 我们发现当学习曲线属于低偏差(高方差)时,可以通过提高训练集的样本数目来提高准确率。
我们发现当学习曲线属于低偏差(高方差)时,可以通过提高训练集的样本数目来提高准确率。
15.1 随机梯度下降(stochastic gradient descent)
梯度下降法的问题是当m值很大时,计算这个微分项的计算量就变得很大,因为需要对所有m个训练样本求和。
由此,我们引入随机梯度下降算法。
具体如下
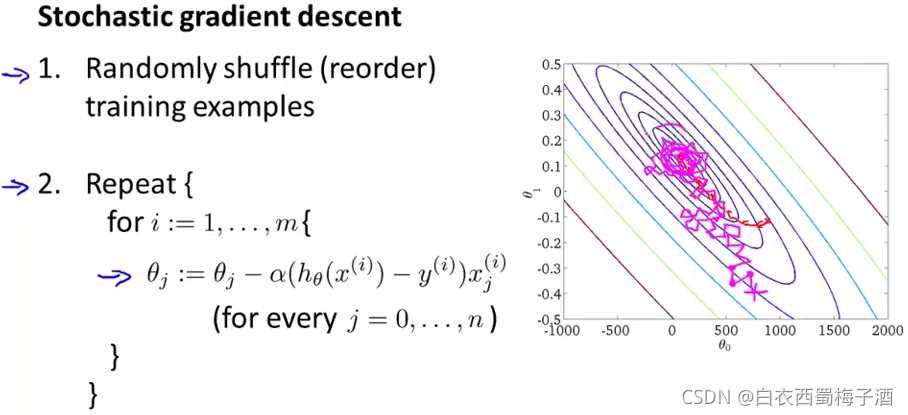 即每次更新都只关注一个样本点,然后计算一小步梯度下降。
即每次更新都只关注一个样本点,然后计算一小步梯度下降。
补充与批量梯度下降算法不同的是,随机梯度算法的下降方向不像批量梯度下降算法那样径直向全局最小值走去,而是以一种比较随机、迂回的路径逼近全局最小值
通常外部的循环1-10次
15.2 小批量梯度下降
小批量梯度下降 每次处理b个样本。
具体如下
 补充 如果能够较好的用向量化来实现该方法,有时甚至比随机梯度下降更快。
补充 如果能够较好的用向量化来实现该方法,有时甚至比随机梯度下降更快。
15.3 大规模数据下的收敛判断以及参数选择
对于随机梯度下降,我们采用如下方法
当随机梯度下降法对训练集进行扫描时,在我们使用某个样本(x(i),y(i))(x(i),y(i))来更新θθ前。让我们来计算出这个假设对这个训练样本的表现(在更新θθ前来完成这一步,原因是如果我们用这个样本更新θθ以后,再让它在这个训练样本上预测,其表现就比实际上要更好了。
最后,为了检查随机梯度下降的收敛性, 要做的就是每1000次迭代运算中,对最后1000个样本的cost值求平均然后画出来,通过观察这些画出来的图,我们就能检查出随机梯度下降是否在收敛。
对于学习速率α的选择,我们可以将其固定为一个常数,也将其改为一个随时间减少的值,例如

15.4 Online Learning
在线学习机制让我们可以模型化问题,在拥有连续一波数据或连续的数据流涌进来 而我们又需要 一个算法来从中学习的时候来模型化问题。
1.使用连续的数据流去建立模型
2.类似随机梯度下降算法,对每个样本进行梯度(学习后就丢弃该样本)
3.自适应个体偏好(例如个体随着时间、经济环境等因素产生的偏好不同问题)
补充 如果利用协同过滤系统,以得到产品更多的特征,从而可以对于不同类型的产品也进行相应的预测分析。
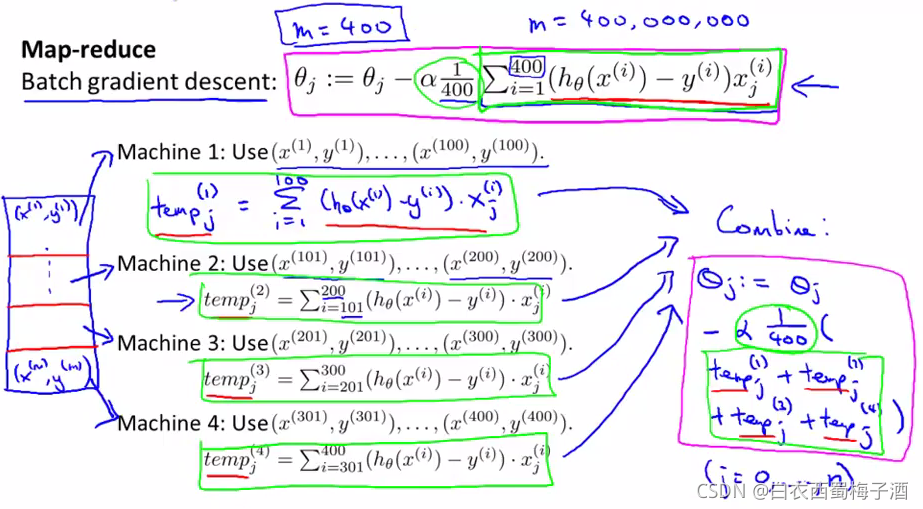
15.5 映射约减(Mapreduce function)
将数据集进行划分,然后发送到每个任务节点,让它们各自执行,然后反馈给一个中央节点,让它对结果进行整合。
具体如下