深层神经网络,目前TensorFlow提供了7种不同的非线性激活函数, tf.nn.relu 、tf.sigrnoid和tf.tanh是其中比较常用的几个。当然,TensorFlow 也支持使用自己定义的激活函数 。简单eg:异或运算(同为0,异为1)
通过神经网络解决多分类问题最常用的方法是设置n个输出节点,其中n为类别的个数。对于每一个样例,神经网络可以得到的一个n维数组作为输出结果.数组中的每一个维度(也就是每一个输出节点)对应一个类别。
Softmax回归本身可以作为一个学习算法来优化分类结果,但在TensorFlow中,softmax回归的参数被去掉了,它只是一层额外的处理层,将神经网络的输出变成一个概率分布。
在实现交叉熵的代码中直接将两个矩阵通过“*”操作相乘。这个操作不是矩阵乘法,而是元素之间直接相乘。矩阵乘法需要使用tf.matmul函数来完成。
因为交叉熵一般会与softmax回归一起使用,所以TensorFlow对这两个功能进行了统一封装,并提供了tf.nn.softmax_cross_entropy_with_logits()函数。在只有一个正确答案的分类问题中,TensorFlow提供了tf.nn.sparse_softmax_cross_entropy_with_logits函数来进一步加速计算过程。
回归问题解决的是对具体数值的预测。比如房价预测、销量预测等都是回归问题。这些问题需要预测的不是一个事先定义好的类别,而是一个任意实数。解决回归问题的神经网络一只有一个输出节点,这个节点的输出值就是预测值。对于回归问题,最常用的损失函数是均方误差(MSE,mean squared error)。
函数为:tf.reduce_mean(tf.square(y_y_))
参数的梯度可以通过求偏导的方式计算,对于参数 θ ,其梯度为主J(θ)。有了θ梯度,还需要定义一个学习率(learning rate)来定义每次参数更新的幅度。从直观上理解,可以认为学习率定义的就是每次参数移动的幅度。参数更新公式为:
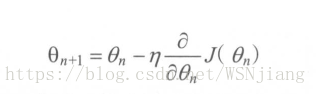
学习率的设置:通过指数衰减的学习率既可以让模型在训练的前期快速接近较优解,又可以保证模型在训练后期不会有太大的波动,从而更加接近局部最优。
tf.train.exponential_ decay函数实现了指数衰减学习率。通过这个函数,可以先使用较大的学习率来快速得到一个比较优的解,然后随着迭代的继续逐步减小学习率,使得模型在训练后期更加稳定。exponential_decay函数会指数级地减小学习率,
正则化的思想就是在损失函数中加入刻画模型复杂程度的指标。假设用于刻画模型在训练数据上表现的损失函数为j(θ)的,那么在优化时不是直接优化j(θ)的,而是优化J(θ)+λR(w)。其中R(w)刻画的是模型的复杂程度,而λ表示模型复杂损失在总损失中的比例。注意这里θ表示的是一个神经网络中所有的参数,它包括边上的权重w和偏置项b。一般来说模型复杂度只由权重w决定。常用的刻画模型复杂度的函数 R(w)有两种,公式为:
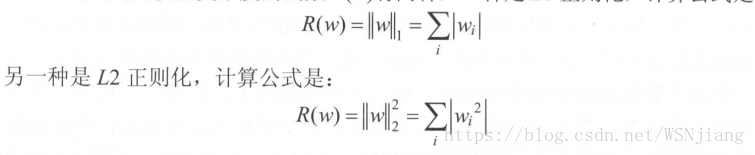
tensorflow函数为:tf.contrib.layers.l1_regularizer(lamba)(w)和tf.contrib.layers.l2_regularizer(lamba)(w)。tensorflow 通过集合在计算图上保存张量,通过调用计算图来提取正则化所需要的W。