1.什么是泛化能力?
在机器学习方法中,泛化能力通俗来讲就是指学习到的模型对未知数据的预测能力。在实际情况中,我们通常通过测试误差来评价学习方法的泛化能力。
泛化能力(generalization ability)是指一个机器学习算法对于没有见过的样本的识别能力。我们也叫做举一反三的能力,或者叫做学以致用的能力。
举个例子,通过学习,小学生就可以熟练的掌握加减法,那么他们是怎么做到的呢?第一步学生们先感性的知道了在有一个苹果的基础上再拿来一个苹果的话就是一种加法,第二步知道个数可以用阿拉伯数字抽象的表示,到了0到9这十个数字和他们的抽象含义,第三步学习十以内的加减法,第四步推广到了多位数的加减法。
我们训练一个机器学习算法也是如此,通过感性的告诉机器一个加上一个等于两个,之后算法通过自己的学习,推广计算多位数的加减法,多位数的加减法是无穷多个的,如果机器在不断的测试中都能够算对,那么我们认为机器已经总结出了加法的内部规律并且能够学以致用,如果说机器只会计算你给机器看过的比如3+3=6,而不会计算没有教过的8+9=17,那么我们认为机器只是死记硬背,并没有学以致用的能力,也就是说泛化能力非常的低,同时我们也把这种现象叫做这个算法过拟合(over-fitting)了。(过拟合是一种分类器会发生的现象,而泛化能力可以理解为对分类器的一种性能的评价)
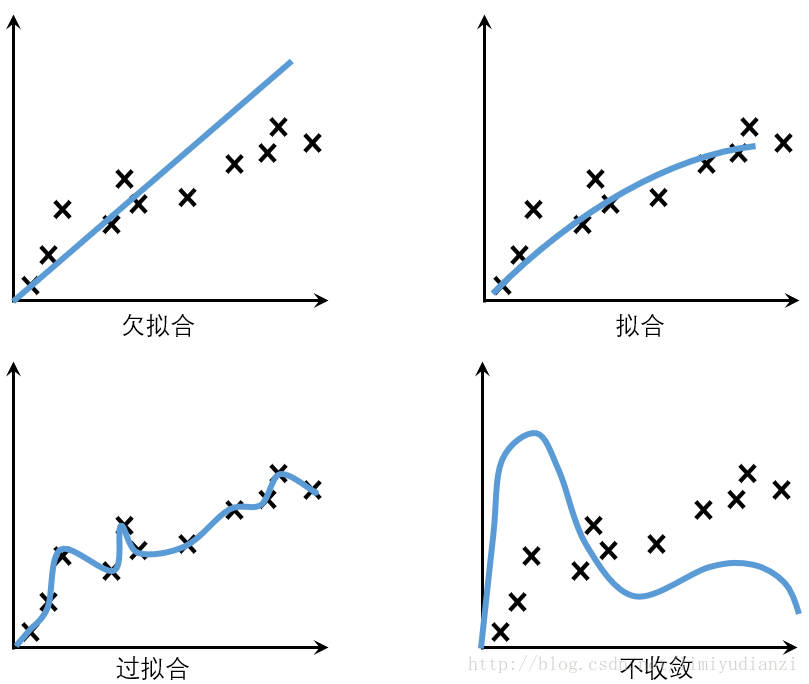
2. 什么是过拟合
过拟合通常可以理解为,模型的复杂度要高于实际的问题,所以就会导致模型死记硬背的记住,而没有理解背后的规律。就比如说人脑要比唐诗复杂得多,即使不理解内容,我们也能背下来,但是理解了内容和写法对于我们理解记忆其他唐诗有好处,如果死记硬背那么就仅仅记住了而已。
3. 什么是欠拟合
欠拟合(under-fitting)是和过拟合相对的现象,可以说是模型的复杂度较低,没法很好的学习到数据背后的规律。就好像开普勒在总结天体运行规律之前,他的老师第谷记录了很多的运行数据,但是都没法用数据去解释天体运行的规律并预测,这就是在天体运行数据上,人们一直处于欠拟合的状态,只知道记录过的过去是这样运行的,但是不知道道理是什么。
4. 什么是不收敛
不收敛一般是形容一些基于梯度下降算法的模型,收敛是指这个算法有能力找到局部的或者全局的最小值,(比如找到使得预测的标签和真实的标签最相近的值,也就是二者距离的最小值),从而得到一个问题的最优解。如果说一个机器学习算法的效果和瞎蒙的差不多那么基本就可以说这个算法没有收敛,也就是根本没有去学习。
5. 什么是鲁棒性
鲁棒性亦称健壮性、稳健性、强健性,是系统的健壮性,它是在异常和危险情况下系统生存的关键,是指系统在一定(结构、大小)的参数摄动下,维持某些性能的特性。例如,计算机软件在输入错误、磁盘故障、网络过载或有意攻击情况下,能否不死机、不崩溃,就是该软件的鲁棒性。响应快速性所谓的响应快速性就是处于稳定状态的系统对于外部环境改变的快速反应能力,也是系统在受到扰动后迅速进入稳态的能力。对于生物模块来讲,任何输入信号,无论是信号分子、蛋白质,还是代射物,都会降解、排出或者转化成其他物质。生物模块必须要在这些输入信号消失之前做出响应,才能确保自身功能的发挥。 --------------------- 本文来自 乐观的Madge 的CSDN 博客 ,全文地址请点击:https://blog.csdn.net/lmj1436140682/article/details/51984734?utm_source=copy