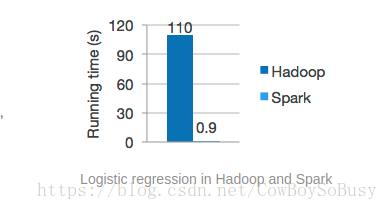
Spark是一个高性能的分布式计算框架,由于是在内存中进行操作,性能比MapReduce要高出很多.
具体的我就不介绍了,直接开始安装部署并进行实例测试
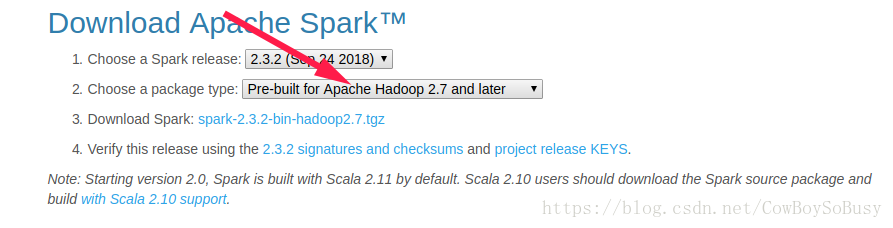
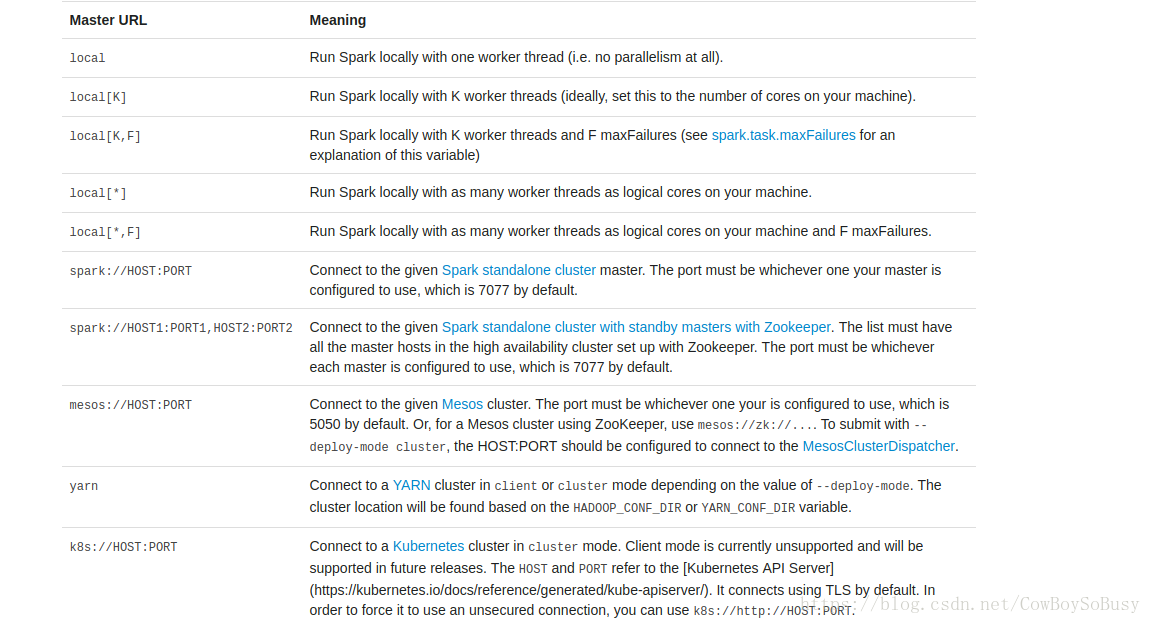
首先在官网下载http://spark.apache.org/downloads.html
注意要根据你的hadoop版本选择,2.7极以后可以选这个
如果选Source Code的话后面启动spark-shell会报这样的错
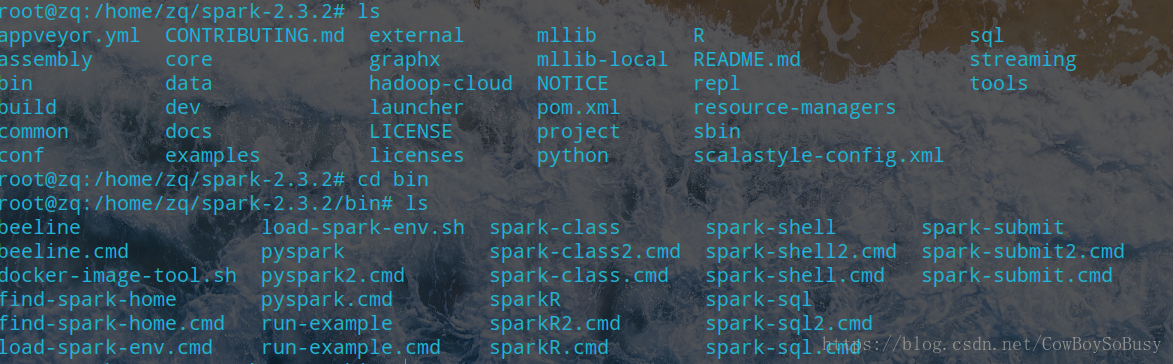
下好解压缩,进入bin目录,
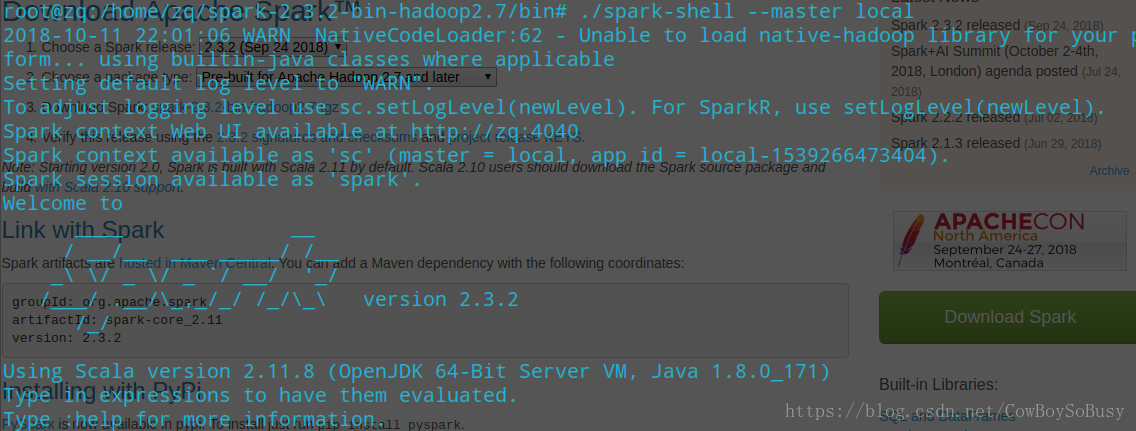
启动spark-shell
参考官网快速启动教程http://spark.apache.org/docs/latest/quick-start.html

./spark-shell --master local[2]
2代表开两个线程,*代表开本地所有线程
下面开始词频统计小案例,我感觉spark比MapReduce操作更简单,速度和效率更快更好.
先准备一个源文件(用于统计),为了简单,我直接把源文件放在桌面上
按照如下命令一步一步来
spark.read.textFile("")和sc.textFile("")都行
flatMap的作用是将两层及以上的list推成一层
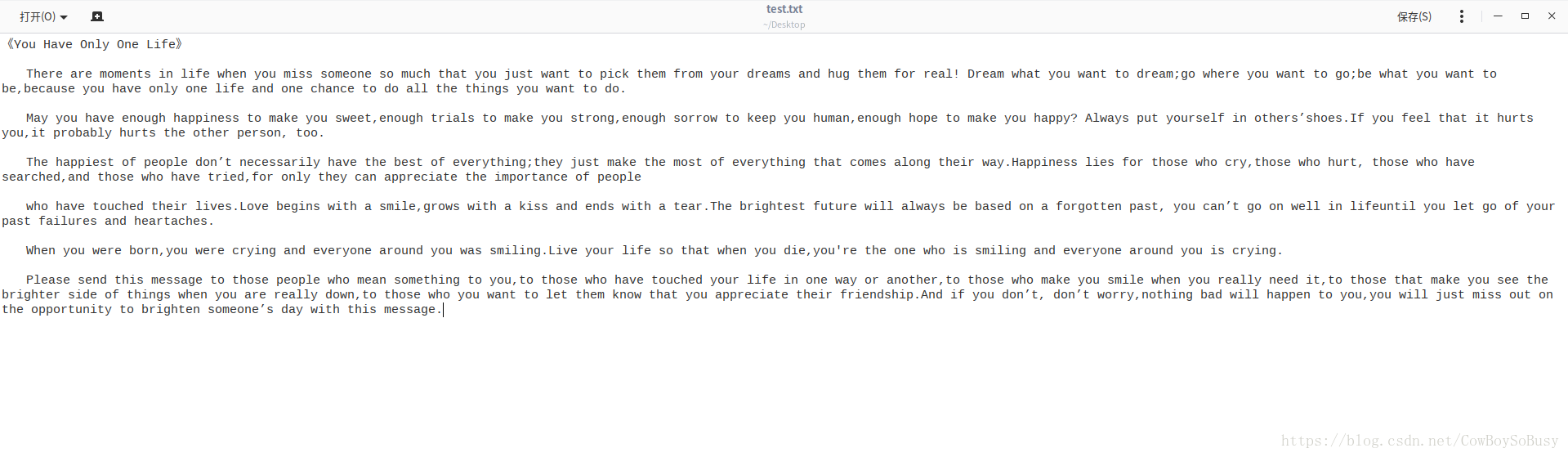
var file = sc.textFile("file:///home/zq/Desktop/test.txt")
file.collect
file.count
file.first()
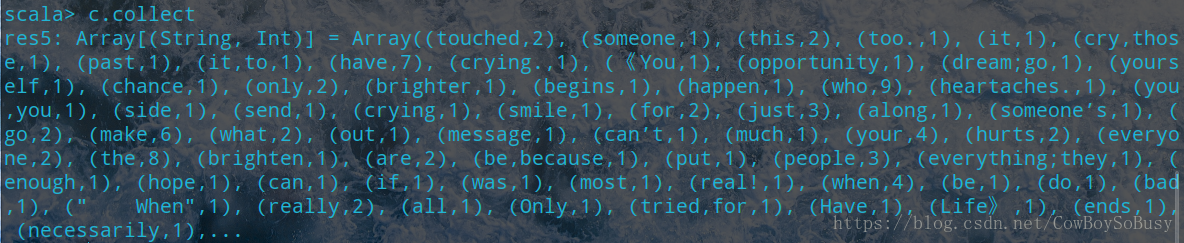
val a = file.flatMap(line=>line.split(" "))
val b = a.map(word=>(word,1))
val c = b.reduceByKey(_ + _)
c.collect
简化操作(效果一致):
sc.textFile("file:///home/zq/Desktop/test.txt").flatMap(line=>line.split(" ")).map(word=>(word,1)).reduceByKey(_ + _).collect
在启动的时候发现一条语句显示如下
Spark context Web UI available at http://zq:4040
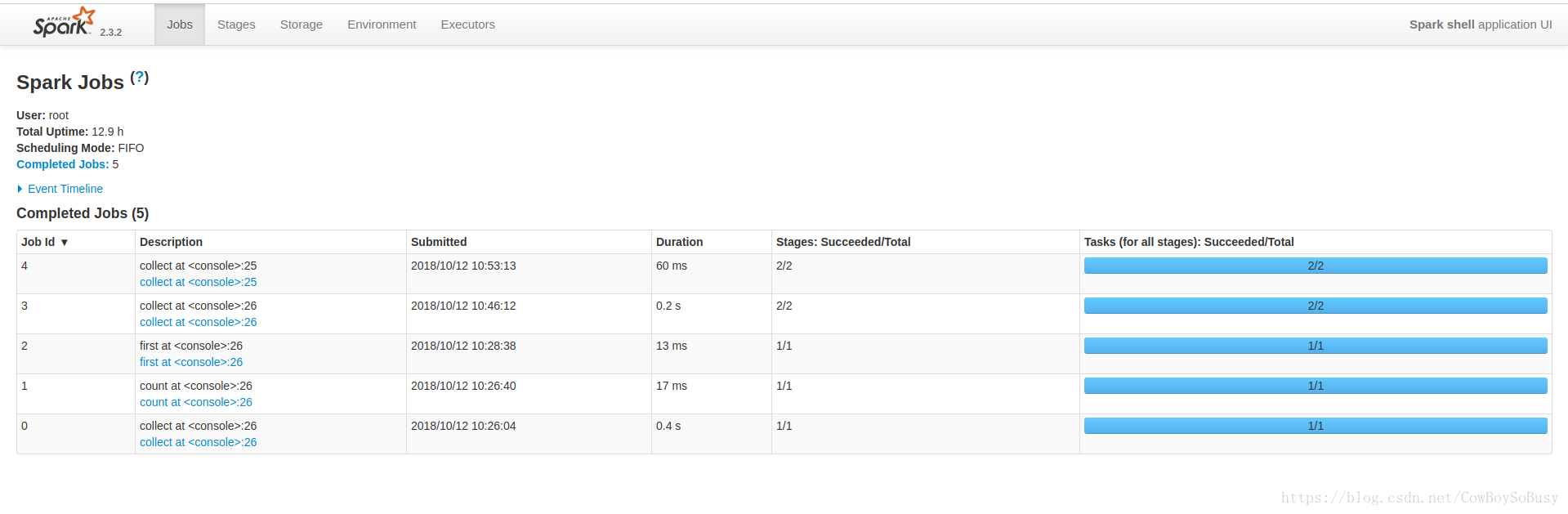
可知本地浏览器访问http://zq:4040,可以看到Web UI界面
上面演示的first,count,map,collect操作在这上面都有历史记录,点击进去即可看到具体情况
你们可以参考一下我的前面几篇博客,是通过Hadoop里面的MapReduce来做的单词统计的程序,
和spark的效果一对比,我个人感觉spark更快更方便,效率更高!
有兴趣可以阅读我的这两篇系列博客
基于MapReduce的词频统计程序WordCountApp(一)
基于MapReduce的词频统计程序WordCount2App(二)
再通过这篇spark的操作,你会发现它们之间的差别与各自的优缺点