Linux系统下spark终端运行中文文档词频统计的python程序。
1.环境配置
*前提
(1) 由于spark是基于hadoop环境下运行的,所以要先完成hadoop的环境配置。
(2)完成hadoop环境配置后,再配置好spark环境。
这里采用的编程语言为python,完成以上两个步骤后,我们开始配置编程环境。
(1)在windows系统上下载python-3.7.3(不会的,网上有教程),并解压,然后将解压后的python包复制到spark文件夹下;
(2)在windows系统上下载jieba(python的一个中文分词库,不会的,网上有教程),并解压,同样将解压后的jieba包复制到spark文件夹下,然后进入spark终端jieba包setup.py文件所在目录下运行右侧代码:python setup.py install
例如
2.文件下载
(1)查询用的小说文件:在网上随意查找一篇小说,并复制到自己新建的txt文档中。
(2)中文停用词文件:在网上百度‘中文停用词’,大概有1890个左右,复制到自己新建的txt文档中。
(3)python程序:先在windows系统下编写测试好你的python程序是否可用,这样复制到linux系统下只需要改动一点点即可。将测试好的python程序保存为.py文件。
spark终端python程序运行代码
[yyl@master spark-2.4.2-bin-hadoop2.7]$ spark-submit --master spark://10:7077 dd.py
3.文件转码
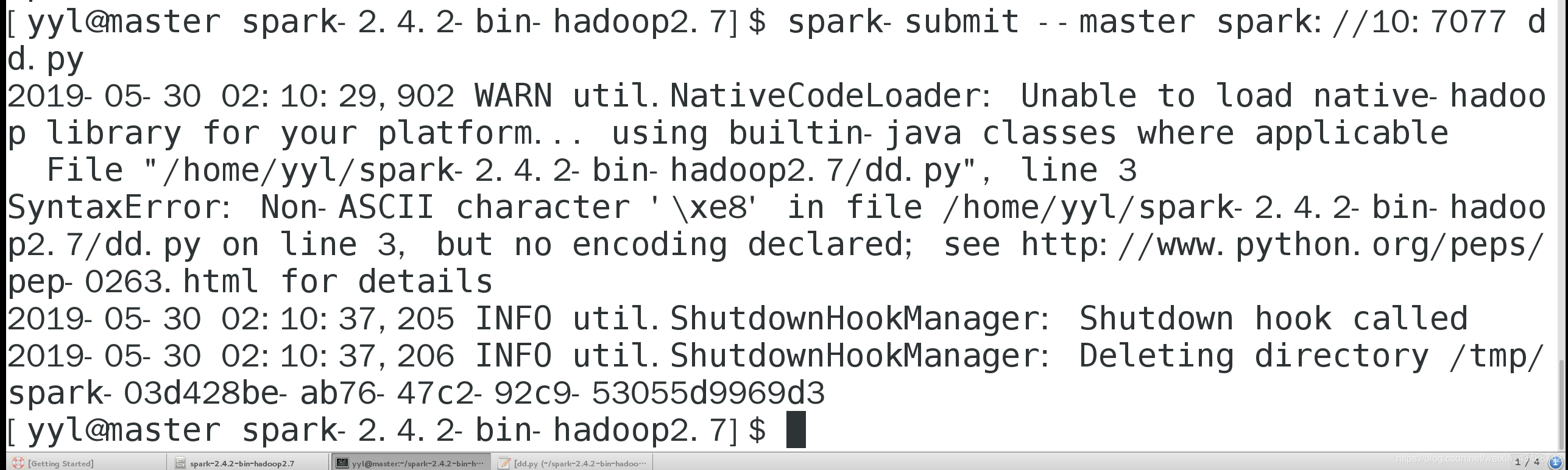
(1)避免出现一切编码不匹配等问题(如下图),准备的中文中文停用词,查询用的小说,python程序等,统一使用utf-8编码。
(2)由于linux系统无法更改文档编码,以下操作均在windows下进行。将python程序文件以记事本方式打开,另存为如下图,将编码选为UTF-8,保存即可(如下图)。中文停用词及查询的txt文本文档均修改为UTF-8编码。然后复制到虚拟机中。
(3)在linux系统下,找到刚才复制过来的python文件,使用gedit打开python程序,并在里面添加如下代码:import sys reload(sys) sys.setdefaultencoding('utf8')(4)如果还是出现以下乱码问题,
则需进入spark文件夹的python文件下修改Python本环境:
在Python的Lib\site-packages文件夹下新建一个sitecustomize.py文件,内容为:#coding=utf8 import sys reload(sys) sys.setdefaultencoding('utf8')


这样程序就可以运行了

spark终端的程序代码如下
import sys
import jieba
reload(sys)
sys.setdefaultencoding('utf8')
#读取数据
text = open('/home/yyl/u8xiaoshuo8.txt','r').read()
len(text)
#全部字符变成小写字符
text = text.lower()
#读取停用词,创建停用词表
stwlist = [line.strip() for line in open ('/home/yyl/u8stop.txt').readlines()]
#先进行分词
words = jieba.cut(text,cut_all = False,HMM = True)
#cut_all:是否采用全模式
#HMM:是否采用HMM模型
#去停用词,统计词频
word_ = {}
for word in words:
if word.strip() not in stwlist:
if len(word) > 1:
if word != '\t':
if word != '\r\n':
#计算词频
if word in word_:
word_[word] += 1
else:
word_[word] = 1
#将词汇和词频以元组的形式保存
word_freq = []
for word,freq in word_.items():
word_freq.append((word,freq))
#进行降序排列
word_freq.sort(key = lambda x:x[1],reverse = True)
#查看前200个结果
for i in range(200):
word,freq =word_freq[i]
print('{0:10}{1:5}'.format(word,freq))
with open('/home/yyl/shuchu.txt','w') as fw:#将结果保存到shuchu文件
for word,freq in str:
fw.write('%s,%d\n' %(word,freq))