1.添加sudo权限的无密码访问的hadoop用户
(1)[root@hadoop001 ~]# useradd hadoop
(2)跟着修改/etc/sudoers文件,
vi /etc/sudoers

用命令cat /etc/sudoers |grep hadoop 查看一下结果

(3)切换用户:su - hadoop
2.下载hadoop
我们不选择apache hadoop的部署,因为我们不单单部署hadoop,还有hive,hbase等很多,所以要用到一个管理工具把这些东西全部部署好。在生产中,企业一般选择CDH、Ambari、hdp部署。
CDH:
cloudera公司,将Apache hadoop-2.6.0源代码,修复bug,新功能,编译为自己的版本cdh5.7.0。
Apache hadoop-2.6.0 和 hadoop-2.6.0-cdh5.7.0其实是一样的。
(1) 我们在百度或谷歌,输入 CDH tar 便可以看到cloudera公司的下载列表(网址http://archive-primary.cloudera.com/cdh5/cdh/5/)
(2) 创建目录
[hadoop@hadoop001 ~]$ mkdir app #在当前家目录新建一个目录app,作用就是以后的软件都放在此处。source,software,data等文件夹以后会一一创建。
[hadoop@hadoop001 ~]$ cd app #创建完后,进入app目录
(3) 下载到app目录
[hadoop@hadoop001 app]$ wget http://archive-primary.cloudera.com/cdh5/cdh/5/hadoop-2.6.0-cdh5.7.0.tar.gz
(4) 解压
[hadoop@hadoop001 app]$ tar -xzvf hadoop-2.6.0-cdh5.7.0.tar.gz
3.JAVA1.7的部署
(1) 先在/usr 目录创建java文件夹,mkdir -p /usr/java
(2) 将jdk1.7安装包下载到/usr/java,并解压安装 tar -xzvf jdk-7u80-linux-x64.tar.gz
(3) 解压之后,修改一下用户和用户组为root,chown -R root:root jdk1.8.0_45/
[hadoop@hadoop001 hadoop-2.6.0-cdh5.7.0]$ ll /usr/java/

(4) 修改环境变量vi /etc/profile,因为现在是用1.7的,所以需要将之前JDK1.8的那个注释掉。

(5) 检查一下安装jdk1.7安装是否正确,which java, java -version

4. 准备工作
(1) 进入hadoop目录
[hadoop@hadoop001 hadoop-2.6.0-cdh5.7.0]$ cd etc/hadoop
(2) 修改hadoop-env.sh文件
[hadoop@hadoop001 hadoop]$ vi hadoop-env.sh
export JAVA_HOME=/usr/java/jdk1.7.0_80
export HADOOP_PREFIX=/home/hadoop/app/hadoop-2.6.0-cdh5.7.0
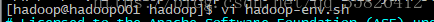

另:如果hadoop-env.sh里面没有HADOOP_PREFIX,就要新加。
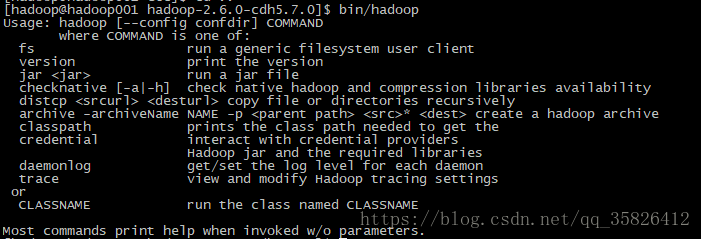
(3) 回到app/hadoop-2.6.0-cdh5.7.0,输入bin/hadoop试试有什么结果,一般有下图的那个提示表示没什么问题了。
[hadoop@hadoop001 hadoop-2.6.0-cdh5.7.0]$ bin/hadoop
Usage: hadoop [--config confdir] COMMAND
5.配置文件
(1)配置core-site.xml,在里面添加如下信息
[hadoop@hadoop001 hadoop]$ vi core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop001:9000</value> # hadoop001是机器名称,根据自己的机器名称修改即可
</property>
</configuration>
(2) 配置hdfs-site.xml,在里面添加如下信息
[hadoop@hadoop001 hadoop]$ vi hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
6.无密码ssh
(1) 先进入家目录 cd 回车

(2) 先删了隐藏文件 .ssh
[hadoop@hadoop001 ~]$ rm -rf .ssh
(3)生成密钥
[hadoop@hadoop001 ~]$ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
Generating public/private dsa key pair.
Created directory '/home/hadoop/.ssh'.
Your identification has been saved in /home/hadoop/.ssh/id_dsa.
Your public key has been saved in /home/hadoop/.ssh/id_dsa.pub.
The key fingerprint is:
a3:c7:ba:e9:2e:77:ff:6f:50:bd:bc:f7:1b:1d:a6:e1 hadoop@hadoop001
The key's randomart image is:
+--[ DSA 1024]----+
| |
| |
| . |
| . .|
| S o.o.|
| o . o +oo|
| . o E .o|
| . .+. ..o|
| =*o ....o..=|
+-----------------+
(4) cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
此时要注意一点,我们先cd .ssh ,再ll

authorized_keys文件的权限是664,会有问题,需要修改,所以
chmod 600 authorized_keys
修改后是

(5) 试试无密登陆,ssh 机器名称

7.配置个人环境变量
(1) cd 回车 ,进入家目录

(2) [hadoop@hadoop001 ~]$ vi .bash_profile
export JAVA_HOME=/usr/java/jdk1.7.0_80
export HADOOP_PREFIX=/home/hadoop/app/hadoop-2.6.0-cdh5.7.0
export PATH=$HADOOP_PREFIX/bin:$JAVA_HOME/bin:$PATH

(3) 重新试试无密码登陆
[hadoop@hadoop001 ~]$ ssh hadoop001
(4)验证一下
[hadoop@hadoop001 ~]$ which hdfs
~/app/hadoop-2.6.0-cdh5.7.0/bin/hdfs
[hadoop@hadoop001 ~]$
[hadoop@hadoop001 ~]$ cd ~/app/hadoop-2.6.0-cdh5.7.0
[hadoop@hadoop001 hadoop-2.6.0-cdh5.7.0]$
(5) 修改slaves文件,将里面改成机器名称
[hadoop@hadoop001 hadoop]$ vi slaves
hadoop001

8.格式化
[hadoop@hadoop001 hadoop-2.6.0-cdh5.7.0]$ bin/hdfs namenode -format
9.启动hdfs
[hadoop@hadoop001 hadoop-2.6.0-cdh5.7.0]$ sbin/start-dfs.sh

10.用jps查看进程,有NameNode,DataNode,SecondaryNameNode三个进程表示启动正常。

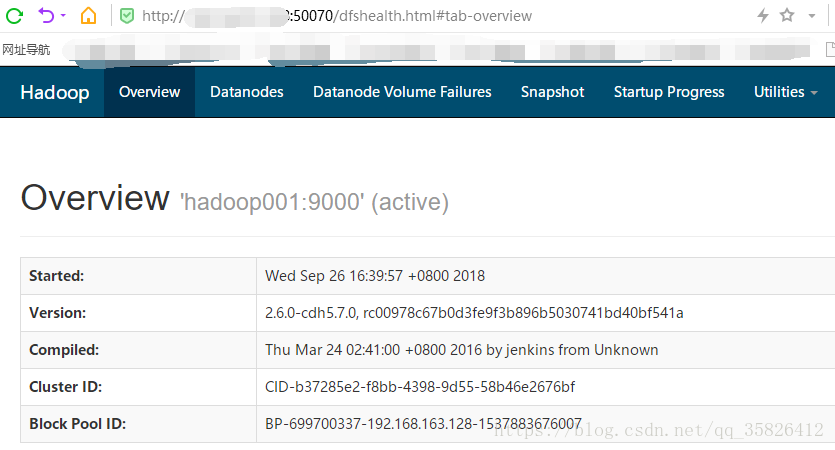
11.登录网站的web界面
在浏览器输入机器的IP地址和端口号,即可访问,hdfs默认的web界面端口号是50070