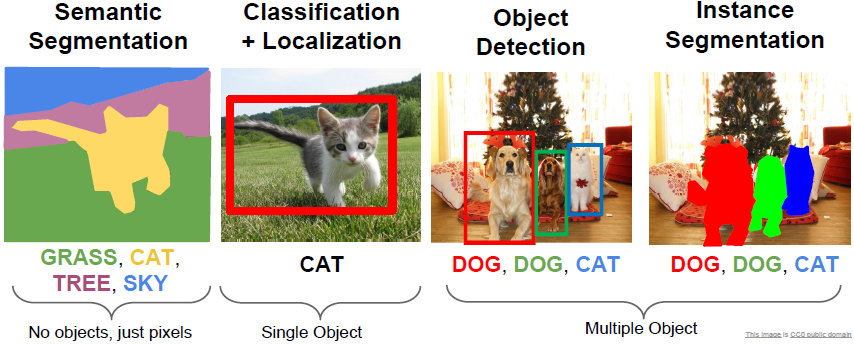
Lecture 11主要讲解的是分割、定位与检测。具体包括语义分割、分类定位、目标检测和实例分割四部分。
文章目录
- 语义分割(Semantic Segmentation)
- Semantic Segmentation Idea: Sliding Window
- Semantic Segmentation Idea: Fully Convolutional
- Semantic Segmentation Idea: downsampling+upsampling
- 分类与定位(Classification + Localization)
- 目标检测(Object Detection)
- Object Detection as Regression
- Object Detection as Classification: Sliding Window
- Object Detection as Classification: Region Proposals
- Detection without Proposals: YOLO / SSD
- 实例分割(Instance Segmentation)
语义分割(Semantic Segmentation)

语义分割为每一个像素产生一个分类标签,但并不区分同类目标。
Semantic Segmentation Idea: Sliding Window
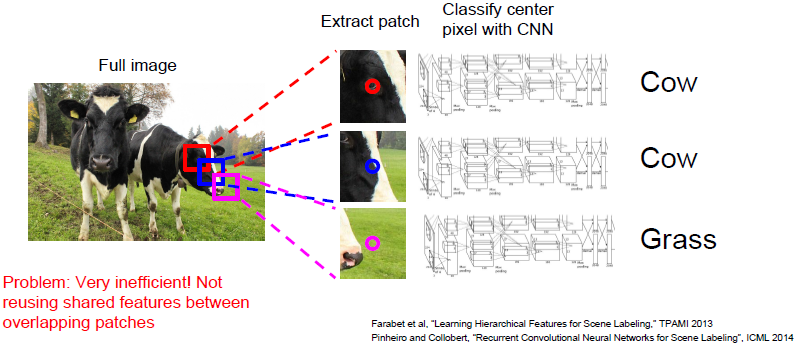
输入一幅图像,将其打碎为许多小的局部图像块。以图中为例,三个包含牛头的小块,对其分别进行分类,判断它的中心像素属于哪类。这个计算复杂度相当的高,因为我们想要标记图像中的每个像素点,我们需要为每个像素准备单独的小块。
当我们希望区分彼此相邻甚至重叠的两块图像块时,这些小块的卷积特征最终通过同样的卷积层,因此,我们可以共享这些图像块的很多计算过程。
Semantic Segmentation Idea: Fully Convolutional
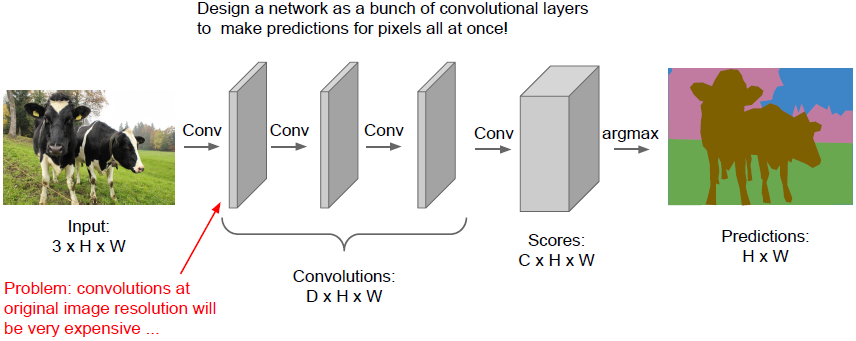
通过数个卷积层最后得到的张量数据的大小是
,
是类的数量,这个张量会对每一个像素的分类进行评分,因此我们可以通过堆叠卷积层一次性完成所有计算。但这种方法存在一个问题,我们的每一个卷积层都保持着与原始输入图像相同的尺寸,这导致计算量非常大。
Semantic Segmentation Idea: downsampling+upsampling
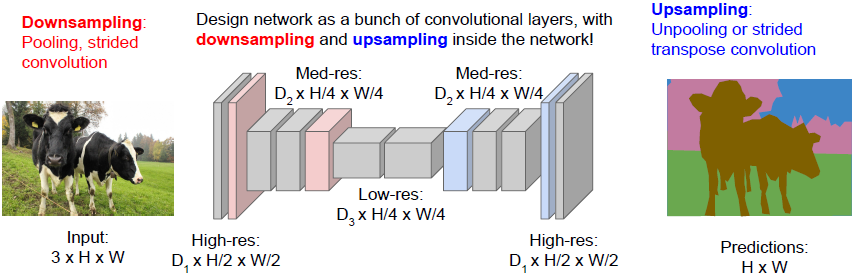
常用方法是对输入图像做下采样,之后再做上采样。相较于基于图像的全维度做卷积,我们仅仅对一部分卷积层做原清晰度处理,之后对特征进行下采样(最大池化,或stride>1的卷积)。在后部分网络中我们希望增加清晰度,这样能使我们的输出维持原有的图像尺寸。这种方法更加方便计算,因为我们可以让网络很深,每层的清晰度降低但是有很多层叠加。
上采样(upsampling):去池化(unpooling)
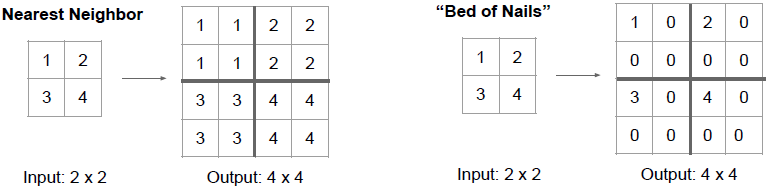
平均池化在下采样中是针对每个池化区域取平均,而在上采样中做的是最近距离(nearest neighbor)去池化。如上图左所示,输出是输入的
stride 2 nearest neighbor去池化结果,在去池化区域中使用输入的当前元素进行填充。如上图右所示为钉床函数的去池化,我们将输入元素放在去池化区域的左上角,并将去池化区域的其他元素置0。
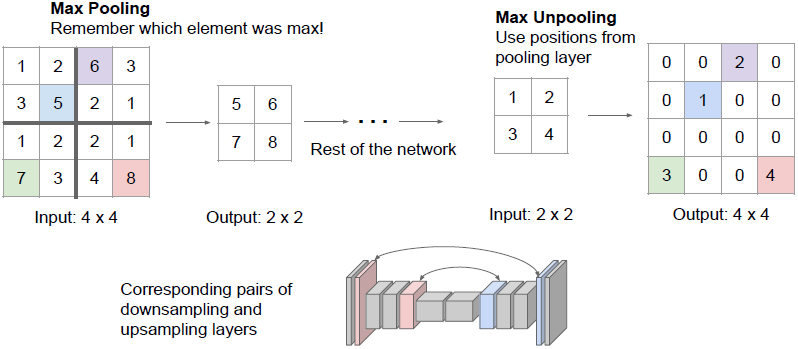
许多神经网络结构是对称的,尤其是下采样的神经网络之后会进行上采样。我们在下采样时用最大池化的同时,会记住池化区域中的最大元素索引,之后我们会执行类似钉床函数去池化的操作,不过这里我们是将输入的元素放在去池化区域中与之前记住的最大元素索引相对应的地方。
将向量去池化可以帮助我们很好地处理细节,存储空间信息(在池化后会丢失这些信息)。
上采样(upsampling):卷积转置(Transpose Convolution)
前面所谈到的各种去池化方法都是使用固定的方程,并不是真的在学习如何上采样。而strided convolution既是一种可学习的层,它可以学习如何下采样,与之对应的我们称之为卷积转置,用于进行上采样,即上采样特征图,又能学习权重。
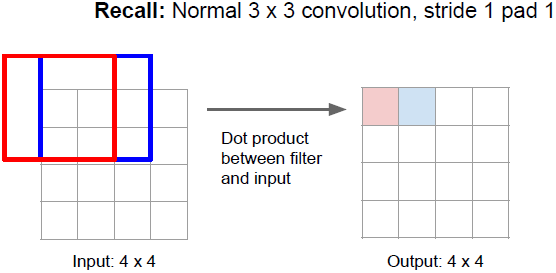
上图所示为3x3卷积的常规操作。
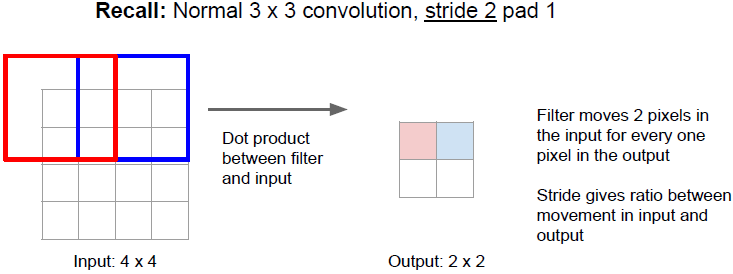
上图所示为3x3的 strided convolution的常规操作。
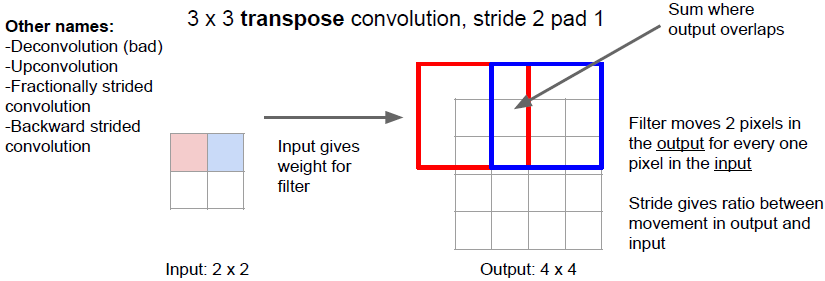
上图所示为卷积转置操作。卷积转置依次取出特征图的输入元素(标量),我们用这个标量乘以filter,以filter的size复制到输出的相应位置,这样输出便是带有权重的filters的叠加(把输入看做权重)。
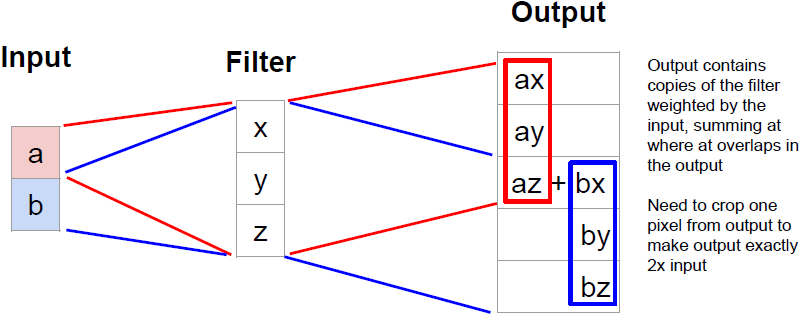
如上图所示我们在一维情况下来理解卷积转置。上图中输入为
,filter为
。我们可以看到输出是对输入做加权,最后对输出中的感受野重叠部分进行叠加。
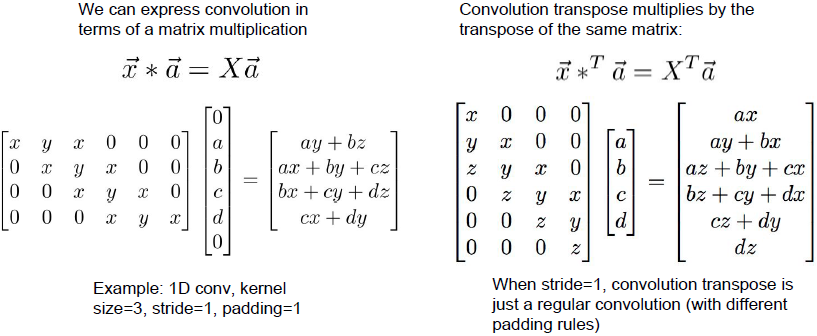
(上图左侧的矩阵X每行的最后一个
应为
。)
我们可以把卷积写成矩阵相乘的形式。如上图所示, 表示有三个元素的卷积向量, 表示有4个元素的输入向量。我们将向量 转变成矩阵形式X,X包含很多由不同区域偏移的卷积核 。卷积转置的意思是我们乘以相同权重矩阵的转置。

当步长为2时情况会有些不一样。对应的转置矩阵不再是卷积。
关于卷积转置有不理解的地方可以参考下CSDN的这篇[深度学习]转置卷积(Transposed Convolution)或是知乎的如何理解深度学习中的deconvolution networks?。
分类与定位(Classification + Localization)
我们不只预测图像的类别(如猫),同时绘制一个bounding box将该类别(猫)包裹进去。与目标检测不同的是分类与定位会提前知道有一个(或更多)物体是我们需要寻找的,且只产生一个bounding box。
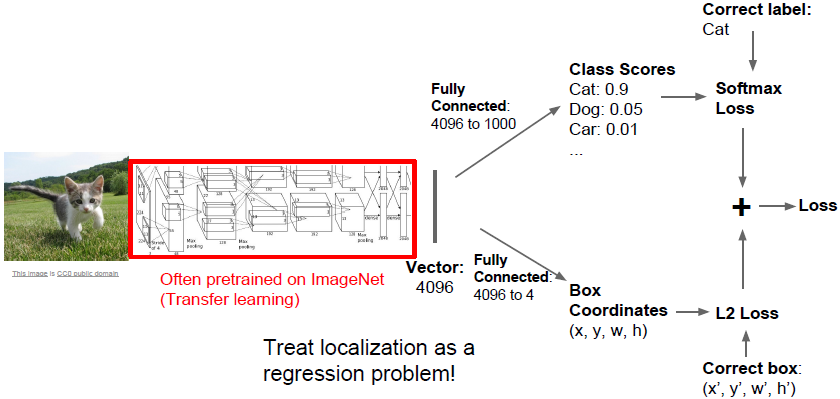
与前面章节所讲解的图像分类类似,这里我们通过AlexNet最后的FC(
)得到类别的scores。此外,我们新增另一个FC(
),输出维度4代表了bounding box的
坐标,宽度和高度。于是网络会产生两个不同的输出,一个是类别的scores,一个是bounding box的四个属性,其中前者是分类问题,后者是回归问题。
训练此网络时,我们有两组损失,使用softmax Loss计算类别的损失,使用L2 Loss计算bounding box的损失,我们对两组损失加权求和得到最终的网络Loss。
姿态估计(Human Pose Estimation)

上图为14关节点的样本示例,来定义人的姿态。
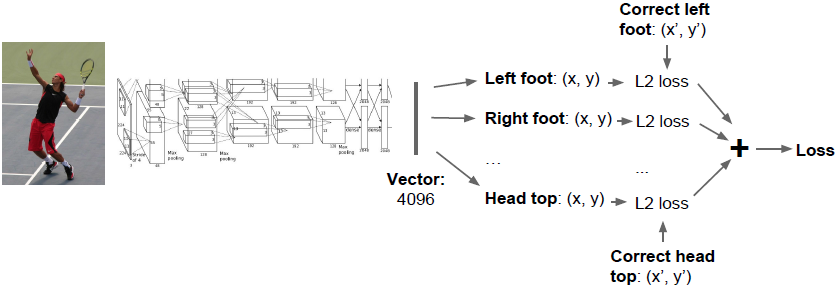
输入这张人像后将输出14组参数,逐一给出这14个关节点的
坐标,然后用回归损失(L2损失、L1损失等)来评估这14个点的预测表现。
目标检测(Object Detection)
目标检测主要研究的是,假设我们已有一些类别已知,我们输入一幅图像,每当在图像中出现其中某一类对象时,围绕对象绘制一个框并预测对象所属类别。与分类定位任务的区别在于每一张输入图像对象的数量是不定的。
Object Detection as Regression
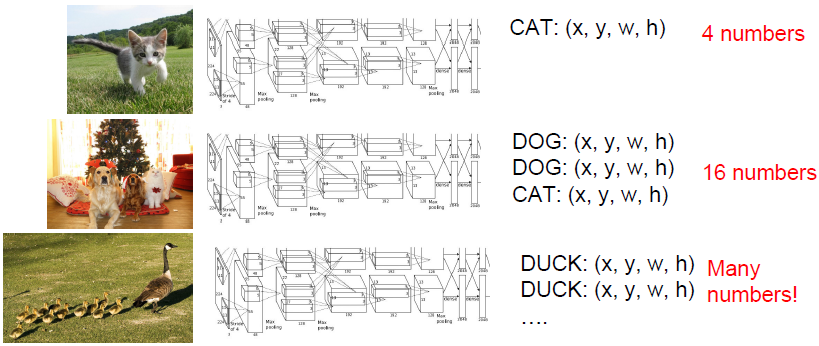
从上图可以看出每幅图像经过网络后需要输出目标bounding box的四个参数信息,然而三幅图的输出参数数量都是不相同的,因此将目标检测问题等同于回归问题来考虑是十分棘手的。
Object Detection as Classification: Sliding Window
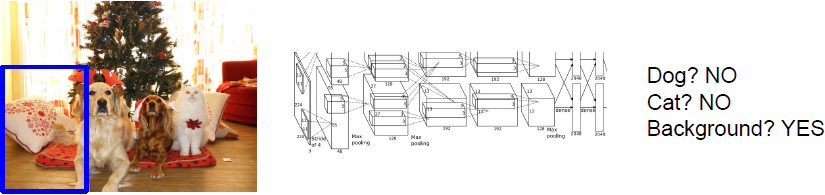
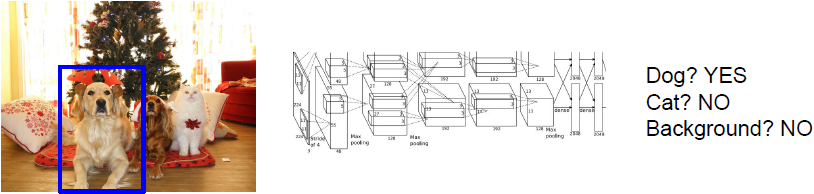
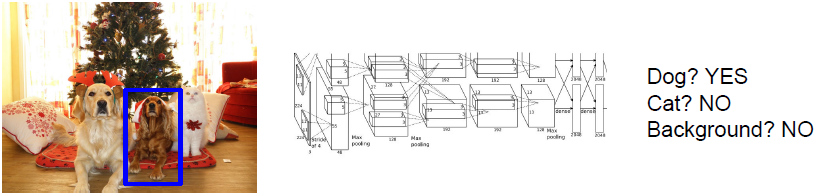
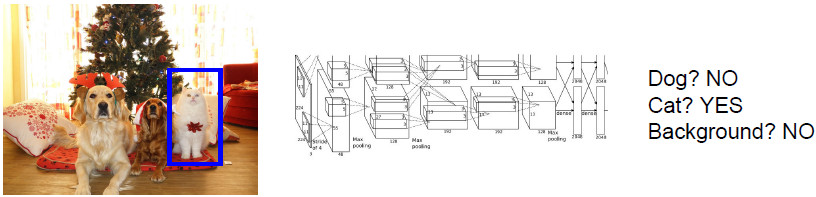
滑动窗口方法类似于图像分割方法中将图像切分为一小块一小块,我们将图像块输入到卷积神经网络中,之后网络会对输入的图像块进行分类决策。
此方法的问题在于你该如何选择图像块,因为图像中对象的数量、尺寸与位置都不确定。(一般不会用此方法。)
Object Detection as Classification: Region Proposals

通常我们使用的是一种称为候选区域的方法。对给定的输入图像,候选区域网络会在目标可能出现的地方绘制上千个框,我们可以将这一步理解为做一些定位操作,也就是寻找图像的边界并且尝试绘制可以包含闭合边界的矩形框。区域选择网络会在输入图像中寻找点状的候选区域,然后给我们一些候选的区域,也就是对象可能出现的区域。
一种常见的区域选择方法是selective search,会给你2000个备选区域(而不是上图的1000),CPU运行2s后输入图像会被切分成2000个可能包含目标体的区域。
我们一般会先使用候选区域网络找到物体可能存在的备选区域,再用卷积神经网络对这些备选区域进行分类。
R-CNN
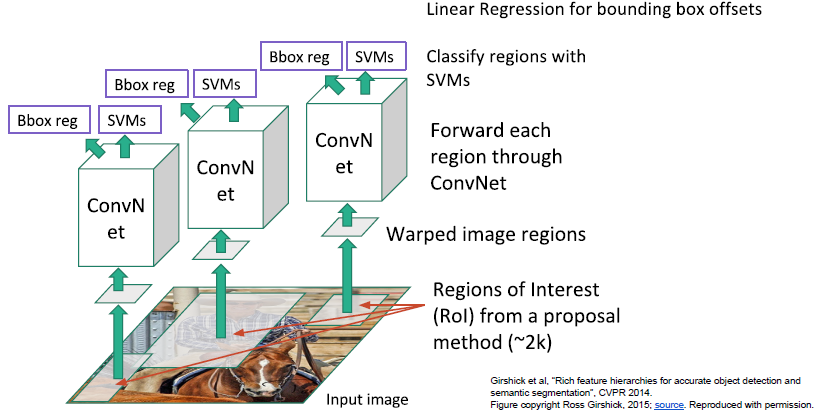
给定输入图像,我们运行一些区域选择网络,去找到备选区域(也称之为兴趣区域ROI),selective search寻找到大约2000个兴趣区域。其中一个问题是这些输入中的区域可能有不同的尺寸,但都要在同一个卷积神经网络中运行做分类。由于全连接层的特性,我们希望所有的输入尺寸一致,因此我们需要处理这些区域,将输入尺寸调整为固定尺寸,使之与下游网络输入相匹配,输入到卷积神经网络中,然后使用SVM基于样本做分类,预测出对应的类别。
另外,R-CNN也可以用于回归预测,校正bounding box的参数,预测边界框四个参数的补偿与修正值。
存在问题:
- 训练阶段十分耗时(84h),需独立训练2000个区域,且图像特征的存储极占空间;
- 测试阶段也十分耗时(30s/幅);
- 区域选择算法不是一种学习算法,参数固定。
Fast R-CNN
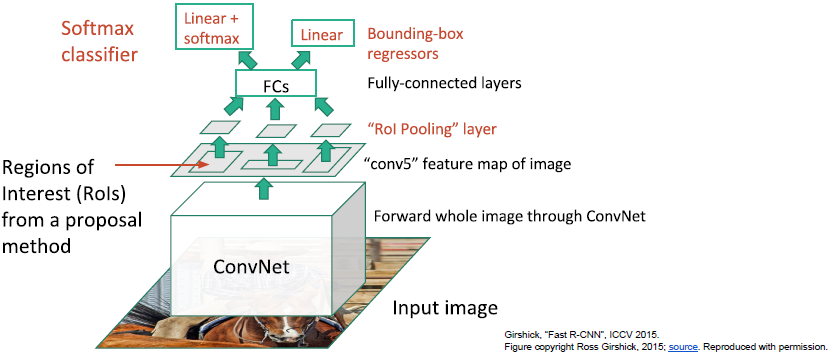
现在不再按兴趣区域处理,而是将整幅图像通过一些卷积层,得到整个图像的高分辨率特征映射。然后我们仍会用一些备选区域选择算法,但并不是使用固定算法(如selective search),我们将这些备选区域投影到卷积特征映射(feature map),之后从卷积特征映射中提取属于备选区域的卷积块,而不是直接截取备选区域的像素。通过对整个图像进行处理,我们可以重用很多卷积计算。另外,如果我们在下游有很多全连接层,这些全连接层的输入应该是固定尺寸的,所以我们需要对从卷积映射提取的图像块进行reshape(用可微的方法)。这里我们使用被称之为ROI 池化层的网络层(ROI Pooling layer)。之后数据经过FC得到预测分类结果以及对包围盒的线性回归补偿。
Fast R-CNN训练过程如下:
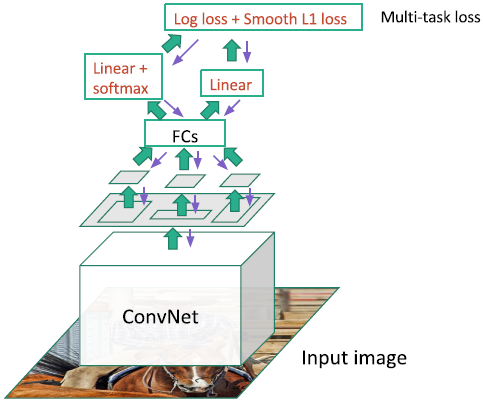
当我们训练这个的时候,在BP阶段我们有一个多任务损失,我们可以基于全局反向传播同时学习。
ROI Pooling
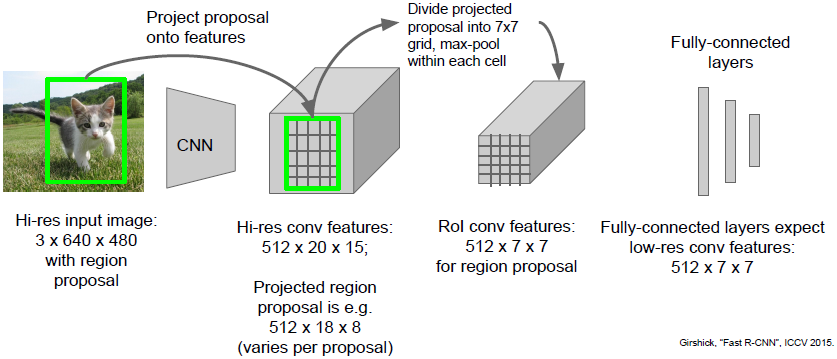
ROI池化有点像最大池化,其主要作用包括以下两点:
- 缩小region proposal的尺寸,加速FC层的训练速度;
- 将数据尺寸reshape为固定的大小,以确保能够进入之后的FC进行训练,实现end-to-end training。
ROI pooling层有两个输入:
- 一个从具有多个卷积核池化的深度网络中训练得到的feature map矩阵;
- 一个表示了所有感兴趣区域的ROI矩阵(维度为 ), 表示ROI的数目,第1列表示区域的index,其余4列表示区域左上角和右下角坐标。
如上图所示,原图像尺寸为 ,输出数据尺寸为 。经过卷积层后数据尺寸变为 的feature map,感兴趣区域大小为 并投影到feature map二维平面中的某一部分,之后我们需要将 的区域划分成 个sections,在每一个sections中取最大元素(此处类似max pooling),最终得到进入FC前尺寸为 的数据。(ROI Pooling有不明了的地方可参考这里。)
Faster R-CNN
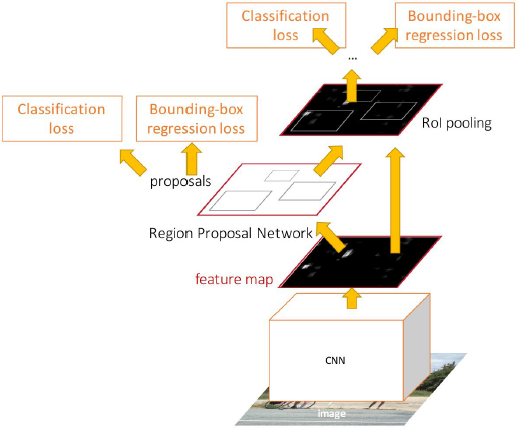
用固定的函数计算备选区域成为提升计算性能的瓶颈,因此我们让网络自身去做这个。同样的,我们在卷积层中运行整个输入图像去获取特征映射(feature map)来表示整个高清晰度图像。然后这里有一个分离备选区域的网络工作于卷积特征的上层,在网络内部预测自己的备选区域,当我们有了这些备选区域后,后续工作就和fast R-CNN一样了。
模型最终Loss包含四个Loss,对应了模型需要完成的四个任务。
区域选择网络需要完成两件事情:
- 他们是否是待识别物体;
- 对包围盒进行校正。
最后FC层网络还需要再做上述的这两件事。
Detection without Proposals: YOLO / SSD
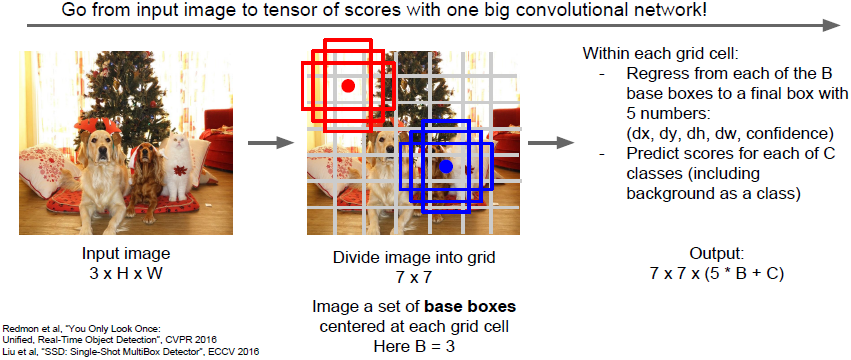
该方法尝试将目标检测作为回归问题处理。给出输入图像,将输入图像分成数个(如
)网格。在每一个网格中,你可以想象一系列的基本边界框(如图所示,绘制了三个基本边界框)。我们需要对每一个网格和每一个基本边界框预测几种参数,一是预测边界框偏移,从而预测出边界框与目标物体的位置偏差;二是预测目标对应类别的classification scores,每个边界框会对应一个类别分数。
最后我们得到如上图所示的输出: ,我们有B个基本边界框,每个边界框对应5个值,分别对应边界框4个参数的差值和我们的置信度;C对应C个目标类别(包括背景类)。我们可以把这种目标检测看做输入一张图像,输出一个三维张量。
基于候选框的网络,正如faster R-CNN中所使用的,最终会寻找出一系列比较接近的图像网格的边界框,另外一些基于候选框的网络除了预测类别之外,还会对预测框做回归。
在faster R-CNN中我们将目标区域的选择看做是一个端到端的回归问题,然后我们对提出的区域分别进行处理。但是在SSD中,我们只做第一步,通过一个前馈网络一次进行所有的目标检测。
目标检测中各式各样的variables:

实例分割(Instance Segmentation)
实例分割指的是,给定一张输入图像,我们想预测出一个图像中某个目标的类别和目标的位置。与目标检测不同之处在于实例分割不是预测出每个目标的边框,而是想要预测出每个物体的整个分割区域,即预测输入图像的哪些元素对应着预测物体。这有点像是语义分割和目标检测的融合。
Mask R-CNN
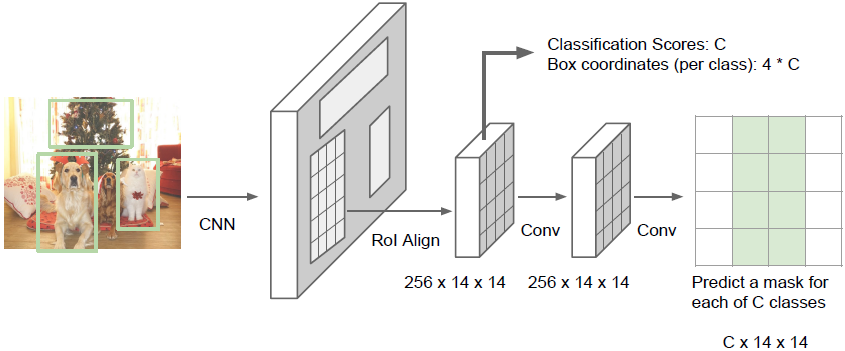
我们将整张图像输入到卷积网络和训练好的候选框生成网络中,得到训练好的候选区域后,我们将这些候选区域投影到卷积特征上(到这一步之前都和faster R-CNN类似)。但现在不只是进行分类预测类别或回归预测边界框,我们同时希望对每一个候选区域预测出一个分割区域。如上图所示的下面一个分支会对输入候选框中的像素进行分类,确定这是不是属于某个物体。
可以看出Mask R-CNN是前述几种模型的整合。
Mask R-CNN也能用于姿态估计:
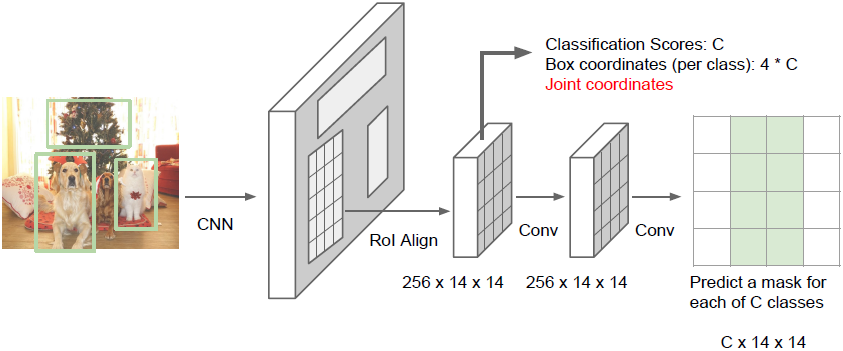
通过回归预测人体每一个关节点的坐标,我们可以进行姿态估计。我们可以使用Mask R-CNN做目标识别、姿态估计和实例分割,唯一需要修改的部分是对于每一个候选框额外添加一个分支。
本博客与https://xuyunkun.com同步更新