Image Classification -- 对于一张图片,如何从一个固定标签集中选一个对它进行标记 ?
从机器的角度看会存在哪些问题和挑战

从一个简单的算法来进行切入,来看刻如何赋予标签。
Nearest Neighbor Classifier
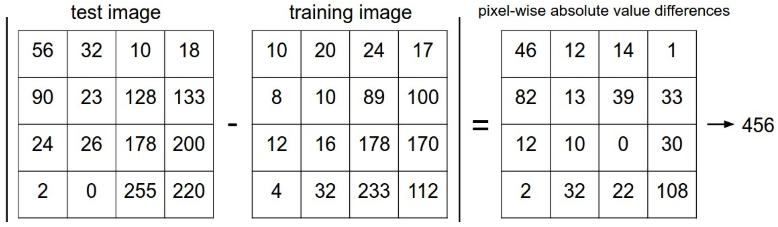
将测试图片和每一个训练图片比较,根据最接近的图片来预测。使用L1 Distance来表示:
是两张图片的向量表示。
经测试发现该算法在CIFAR-10中,只能达到38.6%的准确率。离人工识别的94%以及CNN算法的95%的准确率相差甚远。使用两外一种常用的向量间距离表示法L2 Distance:
计算得到35.4%的准确率,似乎更差了。
k - Nearest Neighbor Classifier
既然找一个最靠近的不行,那就多找几个,然后对测试图片选举投票来决定打什么标签。

上图中5-NN 相比 NN 而言,决策边界更加模糊了,对异常点的抗性更强了。
那 k 的值如何选择,一个个试,看哪个效果好 -_- !,说的有点简单,实际上还是有些门道的。
对于给定的训练数据和测试数据,如何调试超参数,正确的做法是把训练数据分成两部分,训练集和验证集。训练好的模型在验证集上预测,获取最好的结果对应的超参数,将其填入模型,最后在实际的测试集上进行评估。有时候为了获取更好的 k 值会使用交叉验证的方式,如下图所示,将训练数据分成部分,4个训练子集,一个验证子集,这样我们能描绘出一个二维点图,根据平均值即可得到最佳的 k 值。验证时准确率提升到40%。


kNN因为诸多缺点,比如测试缓慢,维度问题等导致其在图像上基本不会被使用, 但是超参数的调试方法是很好的参考。接下来介绍一个更强大的分类方法,且最终会扩展到神经网络和卷积神经网络。
Linear Classification

f 函数如何解释,根据我们为这些权重设置的确切值,f 具有在图像中的某些位置处喜欢或不喜欢(取决于每个重量的符号)某些颜色的能力。由于图像被拉伸成高维列向量,我们可以将每个图像解释为该空间中的单个点(例如,CIFAR-10中的每个图像是3072维空间中32x32×3像素的点)。由于我们将每个类别的得分定义为所有图像像素的加权和,因此每个类别得分是该空间上的线性函数。权重W的另一种解释是W的每一行对应于其中一个类的模板(有时也称为原型)。然后通过使用内积(或点积)将每个模板与图像进行比较来获得图像的每个类的得分)逐个找到“最适合”的那个。

Summary
这节课我认为的重点还是在于图像分类的概念引入,以kNN为例,展示了模型训练、验证和测试的科学方法,介绍了作为CNN组件的线性分类器,包括其数学表达及权重W代表的意义。