漏洞利用是二进制安全的核心内容之一。当安全研究员挖掘到一个新的漏洞时,首先要做的事情就是尝试写POC和exploit。所谓POC,一般来说就是一个能够让程序崩溃的输入,且能够证明控制寄存器或者其他违反安全规则的行为。Exploit则条件更严格一些,是对漏洞的完整利用,通常以弹出一个shell作为目标。
从程序到漏洞再到利用,这个过程需要对二进制程序(或者加上源代码)及其运行过程进行非常透彻的分析,往往需要安全研究员花费数日的心血去研究。漏洞挖掘的过程自动化程度已经较高,工业界利用fuzzer可以得到大量让程序崩溃的输入,但这些输入及相关漏洞并不全都是可利用的。从崩溃输入到利用的过程,需要大量人工分析,如果这个工作也可以自动化,那么将大大节省人的工作量,从而提升安全研究与防护的效率。
漏洞利用自动化在学术界已经不是一个新鲜的话题。有一个专有的名词来定义这个领域:Automatic Exploit Generation。这个词来源于2011年NDSS上CMU的David Brumley的一篇论文,这篇论文也可以说是漏洞利用自动化的开山之作。经过了六年的发展,AEG已经是一个比较成熟的课题,也产生了大量非常实用的解决方案,但仍然有很多问题没有解决,所以依然是二进制安全研究领域的一个热门方向。
这篇文章简单介绍漏洞利用自动化的基本理念和方法,主要依据David Brumley 2011年发表的论文。文中所介绍的,是最简化的条件下漏洞利用问题的建模和求解,因此很多实际问题都没有考虑。无论如何,作为AEG提出的开山之作,用这篇文章来建立漏洞利用自动化的基本思路,是再好不过的。
0x00 从实际出发
讲起栈溢出利用,懂点二进制安全的人肯定非常熟悉。这是所有漏洞利用教程的第一篇,一个简单的由strcpy引起的栈溢出漏洞,通过覆盖返回地址,跳转到shellcode,从而能够弹出shell。
仔细回想一下手动利用的过程,最关键的是以下几个步骤:
1)定位溢出点,通常用不同长度的输入去试验,看什么时候会产生崩溃——严格来说,这是漏洞挖掘的过程。
2)定位返回地址的位置,在有源代码的情况下可以自行分析栈帧的布局,从而计算出返回地址的偏移,或者在无源代码的情况下用一些工具去试验,比如metasploit的pattern_create.rb。
3)精心构造shellcode布局,在精确的返回地址的位置上放置我们的shellcode的起始地址,然后把shellcode的位置也安排好。如果一切计算无误,那么将构造好的输入传给漏洞程序,就会触发漏洞,返回到shellcode的地址并执行shellcode,顺利弹出shell。
那么这个过程中,有哪些信息是需要人工去获取的呢?
1)漏洞位置定位,主要表现为什么样的输入会让程序崩溃触发漏洞。
2)返回地址定位,应该覆盖哪一部分为要跳转的地址。
3)栈的布局,此信息将指导如何精心构造shellcode布局。
4)安排最后的整个输入的布局,每个部分放在什么位置,要基于上面的信息进行推理。
所以,如果我们要进行漏洞自动利用,那么就必须能够自动生成上述所有进行利用必需的信息。
0x01 问题定义
我们要做的是一件什么事情?给AEG系统输入一个程序,经过该系统内部的各种计算和运行,就能够输出一个有效的利用输入。这里的“有效”,姑且定义为能够弹出shell。2011年的AEG还不具备只依靠二进制程序就能产生利用的功能,所以我们再加一个条件,就是拥有这个二进制程序的源代码。所以我们要做的是,在仅有源代码的情况下(AEG系统可自行编译为二进制),不需要人做任何事情,AEG系统就可以自动生成一个有效的利用。
是不是听起来很诱人?当然,2011年的AEG还是一个非常简化的模型,还要有以下几个条件:①漏洞类型限制为栈溢出或者格式化字符串漏洞;②利用类型限制为覆盖返回地址的控制流劫持导致弹出shell;③没有考虑任何系统的安全防护措施,包括栈保护、NX、ASLR等。④必须有程序的源代码;⑤系统环境限制为基于x86的Linux系统。
我们首先来看一个实际的例子,来描述这个问题。所用的例子是iwconfig程序,有大约3400行C代码。截取其中的一小段:

我们可以看到,15行有一个经典的strcpy造成的栈缓冲区溢出。如果我们要对这个漏洞进行利用,就需要完成以下4个步骤。
1. 定位漏洞位置。
这一步主要是通过分析源代码完成,也就是说,我们要找到一个输入,能够让程序顺利地执行到漏洞存在的那个点,也就是找到从输入到漏洞点的路径。AEG利用符号执行技术完成这件事情。
具体说来,就是iwconfig的这段代码中有多个条件和循环语句,如果画出控制流图,我们可以发现程序路径是非常非常多的,但是能够到达15行的strcpy的路径却不多。顺着路径main->print_info->get_info,就可以到达15行,检测到越界内存错误,而且可以发现错误发生在变量ifr.ifr_name上。这些信息就是我们要用符号执行去检测的。
2. 获取程序实际运行时的栈布局及其他信息。
这一步需要二进制程序,就用上一步生成的输入去运行,并且要得到运行时的信息,例如漏洞函数名称、溢出点的地址、栈的布局等等,这些信息是生成利用必备的。AEG通过动态二进制分析完成这一过程。
如果我们手动分析这个漏洞,很显然会得到下图中的执行时栈布局,这个信息对于我们判断如何利用起到非常大的作用。比如说,我们可以获知漏洞函数get_info的返回地址位于栈中的第几个字节的偏移上。
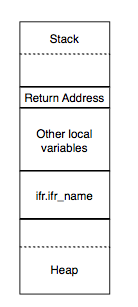
3. 根据上述信息生成利用。
这就要对利用进行形式化描述,将漏洞利用编程一个形式化验证问题,用符号执行产生生成利用的约束公式,然后用求解器进行求解。通俗点说,就是我们要把一些条件转化为形式化的描述,变成路径条件的约束。
这些条件在例子中包括:1)ifr.ifr_name必须包含shellcode;2)覆盖的返回地址必须包含shellcode地址。我们把这两个条件加在路径的约束上,那么约束求解器就会求解出满足这两个条件的答案,也就是能够生成利用的答案。
4. 对利用进行验证。
约束求解器求出来的满足的答案就是我们要的利用输入。最后AEG会用这个输入去运行以验证。如果求解不出来就重新去寻找另一个漏洞尝试进行利用。
0x02 符号执行
在讲解AEG问题的形式化定义之前,我们先来简单介绍一下符号执行。整个AEG方案的基础和关键就是符号执行,正是因为有了这个技术,我们才能够将AEG变成一个形式化的问题去研究。
1 int a, b;
2 scanf(“%d”, &a);
3 if(a > 1)
4 b = a - 1;
5 else
6 b = a + 1;
7 printf(“%d”, b);
将程序的执行抽象为很多条不同的路径,其分支在于代码中的条件跳转。例如下面这段非常简单的C程序,在第3行就有一个分支条件,这里的条件会让路径分开为2条,一条是条件a>1为true,一条是a>1为false。符号执行就是把程序的执行用符号化的公式进行表示,直到最后才求解出满足约束的值,从而达到遍历程序所有约束的目的。
比如说,这个示例程序中,符号执行器会先将输入a定义为一个符号化的int值,其大小为32字节,这32字节的每一位都是符号化的。然后继续运行,会分支出两个条件,一个是a>1为true的,这条路径的条件约束就是“a>1”,走这条路径的话,最后输出的b的约束条件就是“a-1”。同理,另一条路径的条件约束就是“a<=1”,输出b的约束条件就是“a+1”。
如果我们想要程序能够走到两条路径,达到100%执行覆盖率,那很简单,求解器会随便取两个值,一个是大于1的值,另一个是小于等于1的值,这两个输入就足够覆盖两条路径。
如果我们想要b输出一个特定值,也很简单。假如我们想要b输出一个值“2”,那么我们有两条约束:1)a>1且a-1=2;2)a<=1且a+1=2。1)可计算出a=3,2)可计算出a=0,也就说约束求解器会给出两个答案:a=0或a=3。又如我们想让b输出0,那么两条约束:1)a>1且a-1=0;2)a<=1且a+1=0。这就只能算出一个答案a=-1。
有了符号执行,我们可以把非常复杂的程序变成如同例子一样的形式化的约束求解问题,于是可以解决很多以前解决不了的问题,只要我们能够把这个问题转化为约束求解问题,进行形式化的建模。当然,用于真实的、大型的程序的符号执行是非常复杂的,而且求解器又是另外一个非常难的研究领域,具体的细节这里不表,知道这些就足够了。
0x03 形式化建模
现在让我们回到AEG问题的形式化建模上来。一个漏洞利用的生成,其实主要就是两个条件:1)有漏洞;2)可以利用。这两个条件看起来是废话,但如果细究,其实是包含很多具体的约束条件的。我们先将可利用状态用两个布尔谓词定义:有漏洞的执行路径谓词和控制流劫持利用谓词
。你可以把这两个谓词理解为“两个条件”的形式化定义。其中,
定义了漏洞存在的条件,
定义了控制流劫持的条件。那么,一个有效的利用exploit,就是一个能够满足下面这个布尔表达式的输入
:
其实这个式子很好理解。一个输入,既能满足触发漏洞条件,又能满足利用条件,当然就是一个可用的利用。但是关键问题是,这两个条件如何定义。
首先是不安全路径谓词。这个谓词表示执行的路径违反了一个安全特性,我们用
表示。这个
是什么,要根据漏洞的类型去定义。比如说,C程序常见的一些安全问题包括越界读写、不安全的格式化字符串等等,所谓的安全特性
就是一些安全规则的定义。所以,
可以理解为对漏洞的定义和描述,那么找到什么样的漏洞,取决于安全特性
如何定义。在符号执行过程中,
就是定义了能够到达漏洞所在路径的条件。比如我们实例中展示的那一种缓冲区溢出漏洞,复制的输入字符串大小显然超过了缓冲区大小的界限,这就是一个明显的漏洞条件。
然后是利用谓词。
定义了攻击者的逻辑,也就是说如果能够劫持EIP,攻击者会做什么。例如,如果攻击者只想让程序崩溃,谓词就可以是简单的“将eip设置为无效地址,在获取控制之后”。然而我们的目的是弹出shell,那么
就会定义:①shellcode必须存在于内存中;②EIP必须要指向shellcode的起始位置。如果满足了
和之前的
就是最终的结果。如果不满足,说明漏洞是不可利用的。
这样一来,我们就把问题转换为了将漏洞类型建模为,和将利用类型建模为
的过程。那么问题的关键就在于,如何定义这两个条件,尤其是
,需要对各种漏洞利用方式非常熟悉。当然这里的利用方式是最简单的,如果涉及到非常复杂的利用条件,那么又是另外一种情况,这个
的定义就不那么容易了。
很好,我们已经将漏洞挖掘和利用的问题转化为了一个形式化验证的问题,要做的说白了就是生成一大堆复杂的公式,然后去求解它就好了。那么这复杂的公式怎么生成?具体的约束应该是什么?需要的信息怎么获取?最终公式如何求解?接下来要做的,就是如何实现。
0x04 系统总览
整个AEG系统的实现,可以分为六大部分,如图所示。
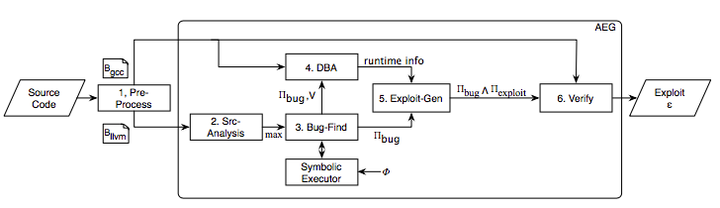
1)PRE-PROCESS
第一个步骤就是预先处理,可以用如下公式表示:
其实就是把源代码分别用GCC和LLVM进行编译,得到二进制和字节码表示
。其中,
其实是一种中间代码,用于符号执行器进行分析,以找到漏洞条件
;而
则是用于二进制分析,用来获取运行时信息,以生成利用条件
。
2)SRC-ANALYSIS
第二个步骤就是分析源代码,可以用如下公式表示:
具体说来就是分析LLVM生成的中间代码,这是一个静态分析的过程,可以得到程序的一些静态信息,比如说buffer创建的时候的最大长度是什么,也就是说通过搜索最大的静态分配buffer大小来定义max。这个max就是符号化输入数据的最小长度——这很好理解,要触发漏洞,显然必须要给定比buffer更长的输入,才有可能覆盖栈中的其他数据造成崩溃。这其实是为下一步符号执行器的分析做准备,这样可以提升符号执行器的分析效率。
3)BUG-FIND
第三个步骤就是寻找漏洞并定位,可以用如下公式表示:
以作为输入,以及一个安全特性
,会输出一个元组
表示漏洞。
是表示漏洞的路径谓词,V是源代码级别的信息,这个信息主要包括关于被检测到的漏洞的各种信息,例如要被覆盖的对象的名称,漏洞函数是什么等等。这些信息V对约束生成以及下一步的利用分析都是有用的。
4)DBA
第四个步骤就是动态二进制分析,可以用如下公式表示:
之前第三步其实我们就可以得到一个能够造成程序崩溃的证明漏洞的输入了,就用表示,实际上是一个符号执行器生成并进行求解的约束条件,崩溃输入就是求出的结果。用这个崩溃输入去运行二进制程序
,并在这个运行过程中进行二进制分析,得到提取出的运行时信息R。这个R信息的获取,要用到V中定义的源代码级别信息,如漏洞函数。R信息包括一些利用时必须用到的信息,如有漏洞的缓冲区在栈上的地址,漏洞函数的返回地址,以及漏洞触发前的栈内存内容等。最终生成利用要依据的主要就是R信息。
5)EXPLOIT-GEN
第五个步骤就是生成利用,可以用如下公式表示:
二进制程序和利用表达式作为输入,用约束求解器进行求解。如果可以满足有效利用的条件,就返回一个利用
,否则返回
表示利用不存在。而且作者还增加一步用
去运行二进制
,检查是否达成条件,例如弹出shell,这个是否成功的验证将反馈给约束求解器,以供利用的生成和选择。
整个系统的关键在于两个条件的定义,其实也就是把漏洞利用问题转化为形式化验证问题。LLVM的分析属于漏洞挖掘领域,的生成才是论文创新的重点,关键在于利用条件的定义。在没有任何保护的情况下,这个条件的定义相当简单:①能够控制一块区域且把shellcode放在这里;②能够控制eip跳到shellcode。当然,这一切的实现都因为有符号执行这个非常厉害的工具。
了解到AEG系统的整体原理之后,我们再来分别单独介绍一下漏洞挖掘和利用生成这两部分的细节究竟是如何实现的。
0x05 基于符号执行的漏洞挖掘
上述所谓生成约束条件的过程,本质上就是利用符号执行挖掘漏洞的过程。自动化漏洞挖掘在工业界通常都是用fuzzer完成的,因为效率比较高,较短的时间内就能得到很多导致崩溃的输入,然后再手动分析验证是否可利用就好。但学术界更青睐符号执行,因为相比fuzzing能够得到更多的语义信息,能够深入到fuzzer走不到的深层程序路径,挖到质量更好的漏洞。但是符号执行最大的问题就在于效率,现实世界的程序是非常复杂的,有无数的分支。由于符号执行器的实现通常是在遇到路径分支的时候会复制出来一个interpreter进行分析,那么在分支不断产生的过程中,程序的开销是以指数级增长的,又称为“路径爆炸”问题。所以主流的符号执行研究都是基于如何能够减少路径爆炸,提升符号执行的可用性。
AEG的作者在这个问题上也提出了几种面向利用生成的优化方法,用来提升漏洞挖掘的效率。具体说来有这么几种:①前置条件的符号执行、②路径优先级选择、③环境建模。
1)前置条件的符号执行
给约束加上一个前置条件,就能够缩小原来很大的一个搜索空间。在AEG中,这个前置条件具体说来,就是输入的长度必须足够大道能够触发漏洞,覆盖缓冲区,才有可能产生利用。

在这个例子中,input最多42个字节,如果没有前置条件,那么在第3行的while语句块中,由于循环产生的分支,完全符号执行需要复制出42个interpreter去进行分析,而且循环里面还套着循环,这就会产生很大的路径爆炸。
但是,如果加上前置条件,即buf长度要超过20字节才有可能触发漏洞并且产生利用,那么这样就将复制的interpreter数量大大减小,能够提升符号执行的效率。
AEG中还有另一种条件,就是输入前缀。输入前缀要根据程序的具体功能来看,比如HTTPGET请求总是以GET开始,那么GET就是相关输入的前缀;又比如是一个图片处理程序,处理的格式是PNG,那么所有的PNG文件的标准是前8字节头部以PNG_H开头,这就是要给前缀。如果有这个条件,比将输入所有字节都符号化,显然效率高了很多。
2)路径优先级选择
在上一个方法中,搜索空间缩小了,但仍然有一个路径选择的问题,就是复制了那么多条分支路径,哪一条应该先探索,哪一条应该后探索呢?解决方法就是路径优先级,所有的路径都被插入一个优先级队列,基于路径的排名进行探索。这里有两种排序方法。
第一是漏洞路径优先。这个方法基于的思想是,如果一条路径上出现了一个小错误,那么说明程序员很容易犯错误,那么在这条路径的后面就更有可能有别的漏洞。在作者的实验中,就发现一条路径上,先是出现了一个off-by-one的漏洞,虽然没法直接利用,但说明程序员对边界并不是很在意。他们继续分析,果然在这条路径后面又发现了一个长度相关的缓冲区溢出。
第二就是循环耗尽策略。传统的符号执行对于循环的处理多是把带有循环的路径优先级降低,或者只循环一定次数。但是这种方法是在基于保证覆盖率的前提下提出的,并不适用于漏洞挖掘。事实上,常出现漏洞的strcpy函数本质上就是一个复制字节的循环,只要没遇到NULL字节就会一直循环,所以要想发现漏洞,我们就必须保证每一个循环都能够耗尽。当然,这可能产生非常大的路径爆炸,这个问题其实不用在意,因为前面的前置条件方法的使用已经解决这个问题了——因为我们知道了能够覆盖缓冲区的最小长度,其实就是知道了strcpy的覆盖长度,也就是它的循环长度。所谓的strcpy循环,其实就是每个字节都判断一下是不是0。当我知道strcpy长度的时候,就不需要判断前面的字节是不是0了,所以实际上可以只用一个解释器,这就不存在路径爆炸问题了。
3)环境建模
程序在运行中是不断与运行环境进行交互的,所以就需要系统能够自动化地对环境进行模拟。AEG对环境建模比较完全,包括文件系统、网络包、标准输入、程序参数、环境变量,而且还能够处理常见的系统函数和库函数调用。虽然文中没有详细解释,但我想应该是AEG对每个可能的环境变量进行设置与解析,而库函数则有相应的建模和信息传递。
总而言之,上述的三种方法其实都是只有一个目的,就是加快符号执行发现漏洞的效率。另外值得注意的是,采用前置条件的实现是对程序进行了静态分析,提取出相关的信息,才能够定义程序的前置条件。
0x06 利用生成与验证
我们之前讲过,利用生成模块的公式是这样的:
其中已经在符号执行的过程中得到了,那么下面就介绍如何获取运行时信息R。
利用生成步骤所需要的信息R是由二进制动态分析实现的,具体方法是插桩。在进行分析前,首先需要输入三个信息:1)目标二进制,2)导致漏洞的路径约束
,3)漏洞函数和缓冲buffer的名称。这些信息是上一步的符号执行步骤中获取的。
这里有一个非常重要的内容,就是栈恢复。如果在漏洞函数返回之前,栈上的信息有被使用的话,就会造成程序崩溃或者已构造的部分被覆盖。举个例子来说,在下面的代码中,攻击者想要利用strcpy的缓冲区溢出,但是ptr参数在返回地址和buf之间,ptr是在栈溢出之后被使用的,那么我们的栈溢出会导致原本的ptr被破坏,程序对ptr解引用时就会出错终止。所以一个复杂的攻击必须考虑上述情况,不要覆盖有效的内存指针。AEG解决的办法就是在动态二进制分析的时候检查整个栈空间的内容,把具体的信息μ传递给利用生成模块,其实理解起来很简单,就是既然这个位置的数不能改,那我就记录下来,在构造输入覆盖的时候让原本应该是ptr的位置还放置ptr的值就可以了。
 有了运行时信息R,我们就可以生成路径约束
有了运行时信息R,我们就可以生成路径约束
具体的算法伪代码如下:
 我们可以看到,算法是对要构造的栈空间内容逐个进行恢复,第2行就是栈恢复,本质上是对栈中内容符号化。第4行的jmp_target =&retaddr - bufaddr + 8是最简单的栈溢出利用的套路,即确定返回地址跳转到什么位置。1-5行的内容是检查是否可以劫持eip这个条件,具体说来就是exp_str[offset]代表返回地址的位置,jmp_target是shellcode放置的位置,要看返回地址能否跳到jmp_target。6-7行是检查shellcode是否放置在从exp_str[offset]开始的位置。最后就是返回这个约束
我们可以看到,算法是对要构造的栈空间内容逐个进行恢复,第2行就是栈恢复,本质上是对栈中内容符号化。第4行的jmp_target =&retaddr - bufaddr + 8是最简单的栈溢出利用的套路,即确定返回地址跳转到什么位置。1-5行的内容是检查是否可以劫持eip这个条件,具体说来就是exp_str[offset]代表返回地址的位置,jmp_target是shellcode放置的位置,要看返回地址能否跳到jmp_target。6-7行是检查shellcode是否放置在从exp_str[offset]开始的位置。最后就是返回这个约束
现在我们有了约束,接下来要做的就是求解了。这就是VERIFY步骤,是利用约束求解器对符号公式进行求解。具体如何求解是一个非常复杂的知识,属于形式化验证的范畴。目前安全研究使用约束求解器基本都是当黑盒用,其内在原理有一些在形式化验证方面更加专业的科学家在研究。总而言之,最后约束求解器产生的那个符合条件的输入,就是能够产生利用的输入
。VERIFY还会进一步实际执行一下这个输入,看看是否真的能弹出shell。
0x07 总结
至此我们就介绍完了整个AEG系统的基本原理和实现。这里还需要说一下AEG的工程实现:由C++和Python编写,其中符号执行器是在KLEE的基础上加了大约5000行代码以实现原创的技术和功能;动态二进制分析是用Python编写,使用了GDB wrapper的接口实现;约束求解器使用了STP。
总结来说,AEG是安全研究领域第一次将“利用自动生成”提出来作为一个研究课题,漏洞利用自动化的研究热潮也自此拉开序幕。当然,这毕竟是2011年的文章,其模型和条件都十分简单,有很多内容是没有考虑的。
我相信读者读了这篇文章,一定会想,如果有NX、ASLR、栈保护的话,可以自动绕过吗?其他漏洞类型和利用类型可以实现吗?Windows平台的利用也可以自动化吗?
可以说,经过了短短六年的发展,AEG已经相当成熟,后续的研究包括Mayhem、Q、Angr、rex等系统,多多少少解决了上述的一些问题,让漏洞利用自动化的程度越来越高。最近在安全界备受关注的美国DARPA CGC比赛,就是一次全自动的漏洞攻防赛。这场比赛从2013年初赛到2016年8月决赛,取得第一名的正是David Brumley团队开发的Mayhem系统。关于CGC的团队和研究,又可以洋洋洒洒写下许多,这里暂时按下不表。总而言之,AEG已经成为二进制安全领域的一个研究热点。
本人才疏学浅,是刚刚接触二进制安全的一个小菜鸟,文章中若有错误之处还请各位大牛多多包涵,且能不吝赐教,悉数指出。如果学有余力,未来可能将继续介绍Mayhem、Q等更加完善的自动利用系统。希望喜欢二进制安全的朋友们能够有所收获。
参考文献:Avgerinos T, Sang K C, Hao B L T, et al. AEG: Automatic ExploitGeneration.[J]. Internet Society, 2011, 57(2).
https://zhuanlan.zhihu.com/p/26690230