使用的编译器是anaconda
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
# 折线图来绘制数据
# np.linespace(strat,stop,num =xx在起始点和终点之间取多少个数值)
date = np.linspace(1,15,15)
endPrice = np.array([2511.90, 2538.26, 2591.66, 2732.98, 2701.69, 2701.29, 2678.67, 2726.50, 2681.50, 2739.17, 2715.07, 2823.58, 2864.90, 2919.08, 2846.34])
beginPrice = np.array([2438.71, 2500.88, 2512.52, 2594.04, 2743.26, 2697.47, 2695.24, 2678.23, 2722.13, 2674.93, 2744.13, 2717.46, 2832.73, 2877.40, 2794.68])
print(date)
# 绘图
plt.figure(num = 'sheet')
for i in range(0,15) :
# 把每一个柱状图当做一个单独的模块来处理
dateOne = np.zeros([2]) #有两个数据,但是描绘的是同一天
dateOne[0] = i
dateOne[1] = i
priceOne = np.zeros([2]) # [ 0., 0.]
priceOne[0] = beginPrice[i] # 給入一个开盘价格
priceOne[1] = endPrice[i] # 給入一个收盘价格
# 判断是上涨还是下跌
if endPrice[i] > beginPrice[i]:
plt.plot(dateOne, priceOne, 'r', lw = 6)
else:
plt.plot(dateOne, priceOne, 'g', lw = 6)
#plt.show()
# A(15X1)*W1(1X10)+b1(1x10) = B(15x10)
# B(15x10)*w2(10x1)+b2(15x1) = C(15X1)
dateNormal = np.zeros([15,1])
priceNormal = np.zeros([15,1])
# 归一化处理
for i in range(0, 15):
dateNormal[i,0] = i/14.0
priceNormal [i,0]= endPrice[i]/3000.0
# 输入
x = tf.placeholder(tf.float32,[None,1])
y = tf.placeholder(tf.float32,[None,1])
# B 从定义来看,最终的结果C与B的值相关,而B的值又与w和b相关
# 在使用梯度下降发的同时,会改变w1,b1,w2,b2的值,所以在这里把b和w的值设置为Variable
w1 = tf.Variable(tf.random_uniform([1,10],0,1)) # tf.random_uniform给一个随机值,[1,10]表示一行十列,且在0,1之间变化
b1 = tf.Variable(tf.zeros([1,10]))
# 实现 A(15X1)*W1(1X10)+b1(1x10) = B(15x10) 得到我们的隐藏层
wb1 = tf.matmul(x,w1)+b1
# 加上一个激励函数
layer1 = tf.nn.relu(wb1)
# C即是输出层的实现
w2 = tf.Variable(tf.random_uniform([10,1],0,1))
b2 = tf.Variable(tf.zeros([15,1]))
wb2 = tf.matmul(layer1,w2)+b2
layer2 = tf.nn.relu(wb2) # 这里的layer2也就是最后得到的C
# 差异的计算
#mean计算的是均值,之后我们再做一个相减的开放,也就是最小二乘
loss = tf.reduce_mean(tf.square(y-layer2))
# 利用梯度下降法来调整w1等这些参数来使得我们的损失逐渐减小
train_step = tf.train.GradientDescentOptimizer(0.1).minimize(loss) #0.1是每次梯度下降的步长,
with tf.Session() as sess:
sess.run(tf.global_variables_initializer()) # 变量的初始化
#我们使用for循环来终止
for i in range(0,10000):
sess.run(train_step,feed_dict = {x:dateNormal,y:priceNormal})
# 我们想运行最后的train_step,究其根本还是在于x,y的输入值
# 在这第77行代码运行之前,通过梯度下降法,我们得到了新的一系列w和b的值
# 我们进行迭代。得到最终的结果pred
pred = sess.run(layer2,feed_dict = {x:dateNormal})
# 对归一化之后的值进行处理
predPrice = np.zeros([15,1])
for i in range(0,15):
predPrice[i,0] = (pred*3000)[i,0]
plt.plot(date,predPrice,'b',lw = 3)
plt.show()
这是全部的代码,用的就是一个简单的神经网络来对股票的收盘价格进行预测,是在ananconda下利用tensorflow框架来实现的。下面我们来分布看一下:
endPrice = np.array([2511.90, 2538.26, 2591.66, 2732.98, 2701.69, 2701.29, 2678.67, 2726.50, 2681.50, 2739.17, 2715.07, 2823.58, 2864.90, 2919.08, 2846.34])
beginPrice = np.array([2438.71, 2500.88, 2512.52, 2594.04, 2743.26, 2697.47, 2695.24, 2678.23, 2722.13, 2674.93, 2744.13, 2717.46, 2832.73, 2877.40, 2794.68])
date = np.linspace(1,15,15)
print(date)endPrice用来表示股票收盘时候的价格。beginPrice则是股票开盘时候的价格。
我记得这里的date应该是表示15天;
下面我们来根据这15天的数据绘制一个柱状图
# 绘图
plt.figure( )
for i in range(0,15) :
# 把每一个柱状图当做一个单独的模块来处理
dateOne = np.zeros([2]) #有两个数据,但是描绘的是同一天
dateOne[0] = i
dateOne[1] = i
priceOne = np.zeros([2]) # [ 0., 0.]
priceOne[0] = beginPrice[i] # 給入一个开盘价格
priceOne[1] = endPrice[i] # 給入一个收盘价格
# 判断是上涨还是下跌
if endPrice[i] > beginPrice[i]:
plt.plot(dateOne, priceOne, 'r', lw = 6)
else:
plt.plot(dateOne, priceOne, 'g', lw = 6)
plt.show()首先利用plt.figure先打开一个画板(大概应该就是这个意思)
之后再利用for循环来对每一组数据进行单独的处理,
dateOne 的作用其实我也是一知半解,我认为应该是一个开盘时间,一个收盘时间,但是肯定都是同一天
priceOne【0】表示的是开盘价格,priceOne【1】表示的是收盘价格;
我们可以利用二者的差来得到今天股票的增跌情况,并利用plt.plot来绘图。
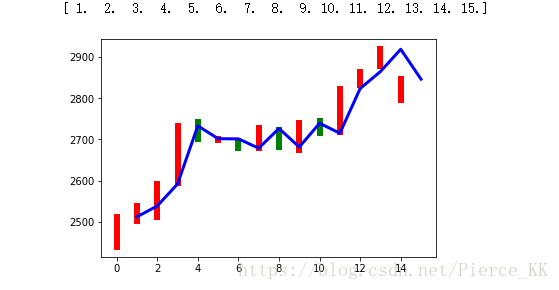
结果就是图中的柱形图(不包括折线图)。
下面我们就开始引入一些简单的神经网络的概念
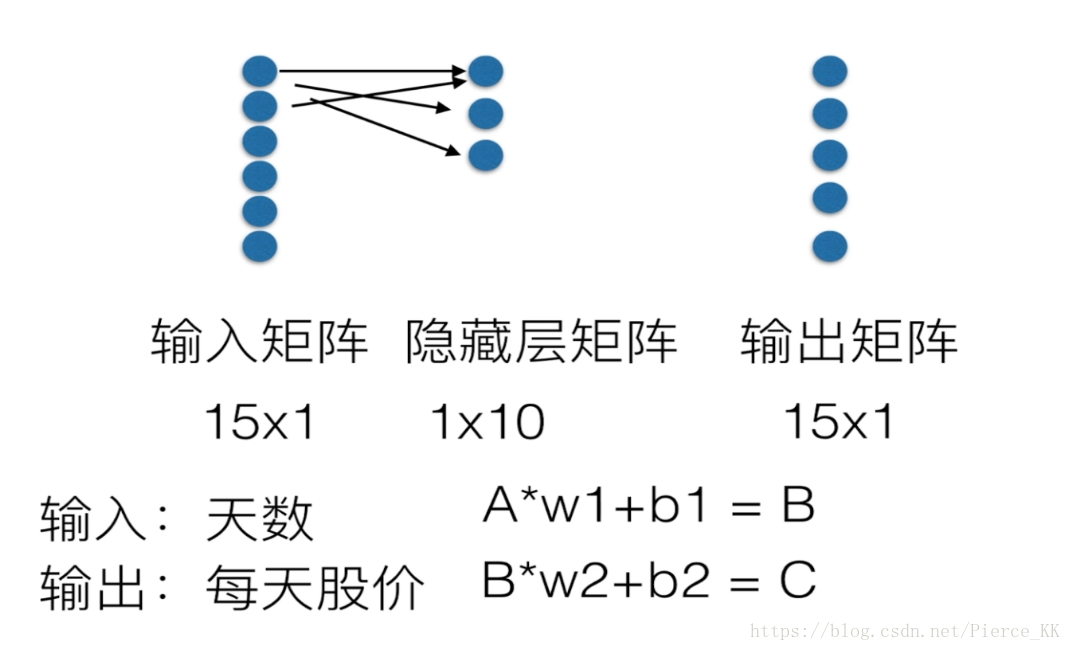


根据这三张图我们回顾一下简单的一层神经网络的基本概念,并且有了对隐层和输出层的计算公式,一次计算后得到的f(x)与h进行对比,再利用梯度下降法和最小二乘求解。
# A(15X1)*W1(1X10)+b1(1x10) = B(15x10)
# B(15x10)*w2(10x1)+b2(15x1) = C(15X1) 这是矩阵运算时候的矩阵阶数。
dateNormal = np.zeros([15,1])
priceNormal = np.zeros([15,1]) 这里定义了两个[ 15x1 ]的输入矩阵
# 归一化处理不再赘述
for i in range(0, 15):
dateNormal[i,0] = i/14.0
priceNormal [i,0]= endPrice[i]/3000.0 归一化处理还需要多花些功夫,不是很理解
#数据的输入,有两个数据,一个是时间,一个是股价
使用placelolder的方式来进行数据的装载
placeholder, 译为占位符,官方说法:”TensorFlow provides a placeholder operation that must be fed with data on execution.”
即必须在执行时feed值。placeholder 实例通常用来为算法的实际输入值作占位符。
(tf.float32,[None,1])表示32位的浮点数,和n行一列
x = tf.placeholder(tf.float32, [None,1]) # x轴表示水平方向上的日期
y = tf.placeholder(tf.float32, [None,1]) # y轴表示
# B 从定义来看,最终的结果C与B的值相关,而B的值又与w和b相关
# 在使用梯度下降发的同时,会改变w1,b1,w2,b2的值,所以在这里把b和w的值设置为Variable
w1 = tf.Variable(tf.random_uniform([1,10],0,1)) # tf.random_uniform给一个随机值,[1,10]表示一行十列,且在0,1之间变化
b1 = tf.Variable(tf.zeros([1,10]))
# 实现 A(15X1)*W1(1X10)+b1(1x10) = B(15x10) 得到我们的隐藏层
wb1 = tf.matmul(x,w1)+b1
# ## ## ## ## ## 矩阵相乘numpy.matmul(a, b, out=None)
# 加上一个激励函数
layer1 = tf.nn.relu(wb1)
# C即是输出层的实现
#这里和中间B层的构建没有什么区别
w2 = tf.Variable(tf.random_uniform([10,1],0,1))
b2 = tf.Variable(tf.zeros([15,1]))
wb2 = tf.matmul(layer1,w2)+b2
layer2 = tf.nn.relu(wb2) # 这里的layer2也就是最后得到的C
# 差异的计算,
# mean计算的是均值,之后我们再做一个相减的开放,也就是最小二乘
loss = tf.reduce_mean(tf.square(y-layer2)) ## tf.reduce_mean用来求均值
#y是我们的真实值,later2是输出层C的一个输出
# 利用梯度下降法来调整w1等这些参数来使得我们的损失逐渐减小
# 在调整的过程中同时调整权重w和偏移b
train_step = tf.train.GradientDescentOptimizer(0.1).minimize(loss) #0.1是每次梯度下降的步长,
#.minimize(loss) 是梯度下降法地的目的
with tf.Session() as sess:
sess.run( tf.global_variables_initializer( ) ) # 变量的初始化,
#我觉得这个 tf.global_variables_initializer( ) 应该是对所有的variable变量同时来初始化
#我们使用for循环来终止
for i in range(0,10000):
sess.run(train_step,feed_dict = { x:dateNormal, y:priceNormal } )
# 我们要运行的是train_step , 这个train_step会调用梯度下降法来不断减小我们的loss, loss源于y与layer2的差,这里的y已知,layer2来源于我们的隐藏层,归根到底,他的输入还是来自于x和y
# 我们想运行最后的train_step,究其根本还是在于x,y的输入值
# 我们进行迭代。得到最终的结果pred,得到这个pred的时候我们的w1,w2等这些参数已经定型了
# pred就是最后的数据
pred = sess.run(layer2,feed_dict = {x:dateNormal})
# 对归一化之后的值进行处理,,( 还原 )
predPrice = np.zeros([15,1])
for i in range(0,15):
predPrice[i,0] = (pred*3000)[i,0]
plt.plot(date, predPrice, 'b', lw = 3)
#用最终的pred来进行价格的还原,就得到了predPrice。
plt.show()