《A Survey on Deep Learning for Localization and Mapping: Towards the Age of Spatial Machine Intelligence》。
目录
摘要
基于深度学习的定位和建图最近引起了极大的关注。基于深度学习的解决方案不是通过利用物理模型或几何理论来创建人工设计的算法,而是提供了一种以数据驱动的方式解决问题的替代方案。受益于不断增加的数据量和计算能力,这些方法正在快速发展成为一个新领域,该领域提供准确和强大的系统来跟踪运动和估计场景及其结构以用于现实世界的应用。在这项工作中,我们提供了全面的调查,并提出了一种使用深度学习进行定位和建图的新分类法。我们还讨论了当前模型的局限性,并指出了可能的未来方向。涵盖了广泛的主题,从学习里程估计、建图到全局定位和同时定位和映射(SLAM)。我们重新审视了使用车载传感器感知自我运动和场景理解的问题,并展示了如何通过将这些模块集成到未来的空间机器智能系统(SMIS)中来解决这个问题。我们希望这项工作能够将机器人、计算机视觉和机器学习社区的新兴工作联系起来,并为未来的研究人员应用深度学习来解决定位和建图问题提供指导。
一、引言
定位和建图是人类和移动机器人的基本需求。作为一个激励的例子,人类能够通过多模态感官感知来感知他们的自我运动和环境,并依靠这种意识在复杂的三维空间中定位和导航自己[1]。这种能力是人类空间能力的一部分。此外,感知自我运动及其周围环境的能力在发展认知和运动控制方面起着至关重要的作用[2]。同样,人工代理或机器人也应该能够感知环境并使用板载传感器估计其系统状态。这些代理可以是任何形式的机器人,例如自动驾驶车辆、送货无人机或家庭服务机器人,感知周围环境并自主做出决策[3]。同样,随着新兴的增强现实(AR)和虚拟现实(VR)技术交织网络空间和物理环境,机器感知的能力支撑着无缝的人机交互。进一步的应用还包括移动和可穿戴设备,例如智能手机、腕带或物联网(IoT)设备,为用户提供范围广泛的基于位置的服务,从行人导航[4]到运动/活动监测[5]、动物追踪[6]或急救人员的应急响应[7]。
为这些和其他数字代理启用高度自治需要精确和强大的定位,并逐步建立和维护世界环境模型,并具有持续处理新信息和适应各种场景的能力。这样的任务在我们的工作中被称为“空间机器智能系统(SMIS)”,或者最近在[8]中被称为空间人工智能。在这项工作中,广义而言,定位是指获取机器人运动的内部系统状态的能力,包括位置、方向和速度,而建图表示感知外部环境状态和捕捉周围环境的能力,包括几何、外观和2D或3D场景的语义。这些组件可以单独行动以分别感知内部或外部状态,也可以联合行动,如同时定位和建图(SLAM)以跟踪姿势并在全局框架中建立一致的环境模型。
1.1 为什么学习基于深度学习的定位与建图
定位和建图问题已经研究了几十年,开发了各种复杂的手工设计模型和算法,例如里程估计(包括视觉里程计[9]、[10]、[11]、视觉-惯性里程计[12]、[13]、[14]、[15]和LIDAR里程计[16])、基于图像的定位[17]、[18]、位置识别[19]、SLAM[10]、[20]、[21]和运动结构(SfM)[22]、[23]。在理想条件下,这些传感器和模型能够准确地估计系统状态而不受时间限制和跨越不同环境。然而,在现实中,不完善的传感器测量、不准确的系统建模、复杂的环境动态和不切实际的约束都会影响手动系统的准确性和可靠性。
基于模型的解决方案的局限性,以及机器学习,尤其是深度学习的最新进展,促使研究人员考虑将数据驱动(学习)方法作为解决问题的替代方法。图1将输入传感器数据(例如视觉、惯性、激光雷达数据或其他传感器)与输出目标值(例如位置、方向、场景几何或语义)之间的关系总结为映射函数。传统的基于模型的解决方案是通过手工设计算法和校准到特定的应用领域来实现的,而基于学习的方法通过学习的知识构建这个映射函数。基于学习的方法的优点有三个:

首先,学习方法可以利用高度表达的深度神经网络作为通用逼近器,并自动发现与任务相关的特征。这一特性使学习模型能够适应环境,例如无特征区域、动态强光条件、运动模糊、精确的相机校准,这些都是手动建模的挑战[3]。作为一个有代表性的例子,视觉里程计通过在其设计[24]、[25]中结合数据驱动的方法,在鲁棒性方面取得了显着的进步,优于最先进的传统算法。此外,学习方法能够将抽象元素与人类可理解的术语[26]、[27]联系起来,例如SLAM中的语义标签,这很难用正式的数学方式来描述。
其次,学习方法允许空间机器智能系统从过去的经验中学习,并积极利用新信息。通过构建一个通用的数据驱动模型,它避免了在部署之前指定有关数学和物理规则的全部知识[28]来解决特定领域问题的人力。这种能力可能使学习机器能够在新场景或面对新情况下自动发现新的计算解决方案,进一步发展自己并改进他们的模型。一个很好的例子是,通过使用新颖的视图合成作为自监督信号,可以从未标记的视频中恢复自运动和深度[29]、[30]。此外,通过构建任务驱动的地图,学习的表示可以进一步支持高级任务,例如路径规划[31]和决策制定[32]。
第三个好处是它能够充分利用越来越多的传感器数据和计算能力。深度学习或深度神经网络具有扩展到大规模问题的能力。DNN框架内的大量参数通过最小化损失函数、通过反向传播和梯度下降算法在大型数据集上进行训练来自动优化。例如,最近发布的GPT-3[33],最大的预训练语言模型,具有令人难以置信的超过1750亿个参数,即使没有微调。此外,还发布了各种与定位和建图相关的大规模数据集,例如在自动驾驶汽车场景中,[34]、[35]、[36]具有丰富的传感器数据组合的集合,以及运动和语义标签。这给了我们一种想象,即可以利用数据和计算的力量来解决定位和建图问题。
然而,还必须指出的是,这些学习技术依赖于大量数据集来提取具有统计意义的模式,并且很难推广到集合外的环境。缺乏模型可解释性。此外,虽然高度可并行化,但它们通常比简单模型的计算成本更高。第7节讨论了限制的详细信息。
1.2 与其他综述对比
有很多篇调查论文广泛讨论了基于模型的定位和建图方法。[37]、[38]很好地总结了SLAM问题在早期几十年的发展。开创性的调查[39]对现有的SLAM工作进行了彻底的讨论,回顾了发展的历史并描绘了几个未来的方向。尽管本文包含简要讨论深度学习模型的部分,但并未全面概述该领域,尤其是由于过去五年该领域研究的爆炸式增长。其他SLAM调查论文仅关注SLAM系统的个别风格,包括SLAM[40]的概率公式、视觉里程计[41]、位姿图SLAM[42]和动态环境中的SLAM[43]。我们建议读者参考这些调查,以便更好地了解基于传统模型的解决方案。另一方面,[3]讨论了深度学习在机器人研究中的应用;然而,它的主要关注点并不是专门针对定位和建图,而是更广泛地看待深度学习在机器人技术的广泛背景下的潜力和局限性,包括机制学习、推理和规划。
值得注意的是,虽然定位和建图问题属于机器人技术的关键概念,但学习方法的结合与机器学习、计算机视觉甚至自然语言处理等其他研究领域同步发展。因此,在将相关工作全面总结成调查论文时,这个跨学科领域带来了不小的困难。据我们所知,这是第一篇全面而广泛地涵盖现有基于深度学习的定位与和建图工作的调查文章。
1.3 综述结构
本文的其余部分组织如下:第2节概述并介绍了现有基于深度学习的定位和建图的分类;第3、4、5、6节分别讨论了现有的关于相对运动(里程计)估计的深度学习工作,几何、语义和一般的建图方法、侧重于SLAM后端的全局定位以及同时定位和建图;第7节总结了开放性问题,讨论现有工作的局限性和未来前景;最后第8节结束了论文。
二、现有方法分类
我们提供了与定位和建图相关的现有深度学习方法的新分类,以连接机器人、计算机视觉和机器学习领域。从广义上讲,它们可以分为里程估计、建图、全局定位和SLAM,如图 2 所示的分类所示:(以下为不同分类中深度学习的作用)

2.1 里程计估计
里程计估计涉及计算两帧或多帧传感器数据之间在平移和旋转方面的相对变化。它持续跟踪自身运动,然后根据位置和方向将这些姿势变化相对于初始状态进行整合,以得出全局姿势。这被广泛称为所谓的航位推算解决方案。里程计估计可用于提供位姿信息并作为里程计运动模型来辅助机器人控制的反馈回路。关键问题是从各种传感器测量中准确估计运动变换。为此,应用深度学习以端到端的方式对运动动力学进行建模,或提取有用的特征以混合方式支持预构建的系统。
2.2 地图构建
Mapping 建立和重建一个一致的模型来描述周围环境。建图可用于为人类操作员和高级机器人任务提供环境信息,限制里程估计的误差漂移,并检索全局定位的查询观察[39]。深度学习被用作从用于建图的高维原始数据中发现场景几何和语义的有用工具。基于深度学习的建图方法被细分为几何映射、语义映射和一般映射,这取决于神经网络是学习场景的显式几何或语义,还是将场景编码为隐式神经表示。
2.3全局定位
全局定位在具有先验知识的已知场景中检索移动代理的全局位姿。这是通过将查询输入数据与预先构建的2D或3D地图、其他空间参考或之前访问过的场景进行匹配来实现的。它可以用来减少航位推算系统的位姿漂移或解决“被绑架机器人”问题[40]。深度学习用于解决因视图、光照、天气和场景动态、查询数据和地图之间的变化而变得复杂的棘手数据关联问题。
2.4同步定位和建图
同步定位和建图(SLAM)将上述里程估计、全局定位和建图过程集成为前端,并联合优化这些模块以提高定位和建图的性能。除了上述这些模块之外,其他几个SLAM模块执行以下操作以确保整个系统的一致性:局部优化确保相机运动和场景几何的局部一致性;全局优化旨在约束全局轨迹的漂移,并在全局范围内;关键帧检测用于基于关键帧的SLAM以实现更有效的推理,而一旦通过闭环检测检测到闭环,则可以通过全局优化来减轻系统误差漂移;不确定性估计提供了对学习姿势和建图的置信度量,这对于SLAM系统中的概率传感器融合和后端优化至关重要。
尽管各个组件的设计目标不同,但上述组件可以集成到空间机器智能系统(SMIS)中以解决现实世界的挑战,从而实现稳健的操作和恶劣环境下的长期自治。这种基于深度学习的集成定位和建图系统的概念图如图3所示,显示了这些组件的关系。在以下部分中,我们将详细讨论这些组件。
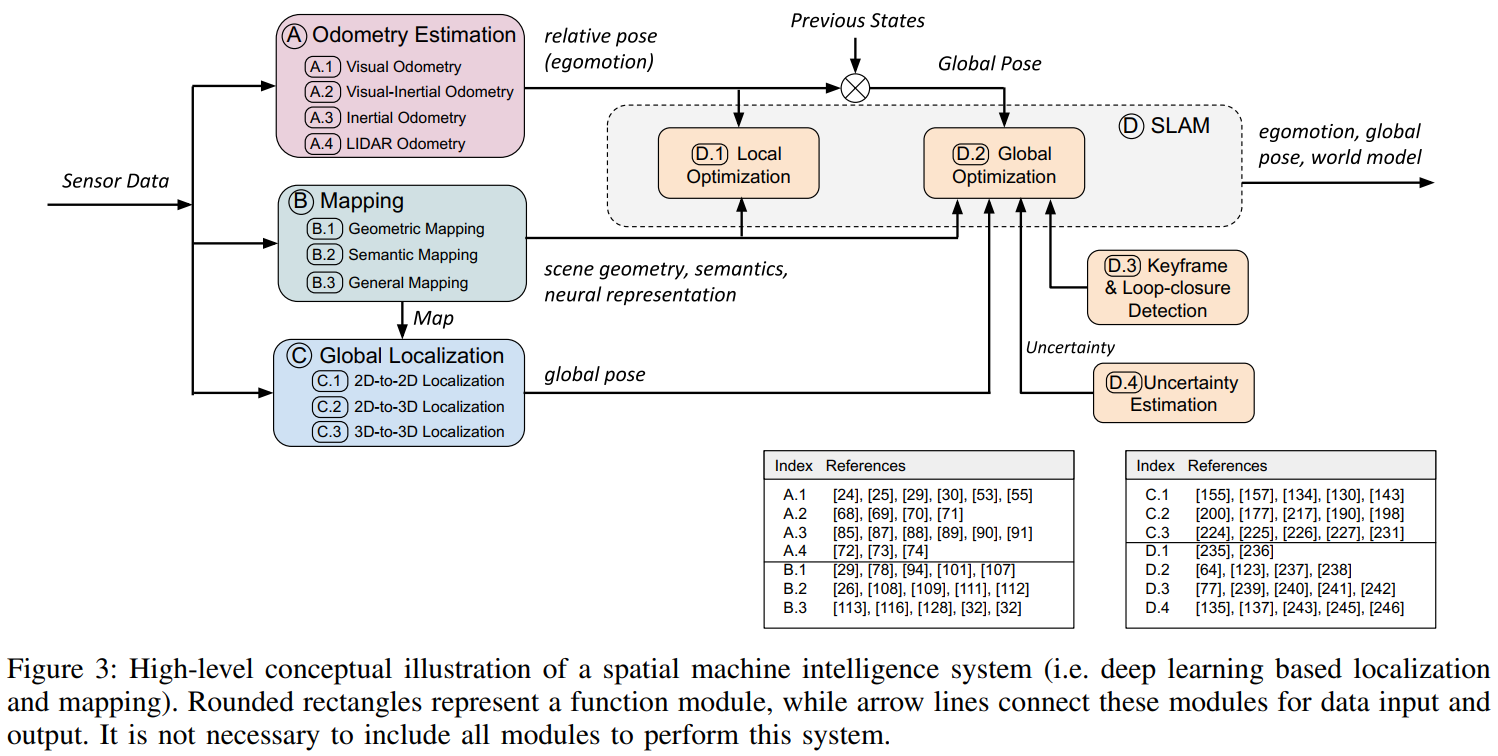
三、里程计估计
我们从里程计估计开始,它持续跟踪相机的自我运动并产生相对姿势。在给定初始状态的情况下,通过整合这些相对姿势来重建全局轨迹,因此保持运动变换估计足够准确以确保全局范围内的高精度定位至关重要。本节讨论从各种传感器数据中实现里程估计的深度学习方法,这些数据在数据属性和应用场景上存在根本差异。讨论主要集中在视觉、惯性和点云数据的里程计估计,因为它们是移动代理感知模式的常见选择。
3.1 视觉里程计
视觉里程计(VO)估计相机的自我运动,并将图像之间的相对运动整合到全局姿势中。深度学习方法能够从图像中提取高级特征表示,从而提供解决VO问题的替代方法,而不需要手工设计的特征提取器。现有的基于深度学习的VO模型可以分为端到端VO和混合VO,这取决于它们是纯基于神经网络的还是经典VO 算法和深度神经网络的组合。根据训练阶段真实标签的可用性,端到端的VO系统可以进一步分为有监督的VO和无监督的VO。
3.1.1 有监督VO学习(端到端VO)
我们首先引入有监督的VO,这是基于学习的里程计的最主要方法之一,通过在标记数据集上训练深度神经网络模型来直接构建从连续图像到运动变换的映射函数,而不是利用图像的几何结构,如传统的VO系统[41]。最基本的,深度神经网络的输入是一对连续的图像,输出是估计的两帧图像之间的平移和旋转。
该领域的首批作品之一是Konda等人[44]。这种方法将视觉里程计定义为一个分类问题,并使用卷积神经网络(ConvNet)从输入图像中预测离散的速度和方向。科斯坦特等人[45]使用ConvNet从密集光流中提取视觉特征,并基于这些视觉特征输出帧到帧运动估计。尽管如此,这两项工作都没有实现从图像到运动估计的端到端学习,它们的性能仍然有限。
DeepVO[24]利用卷积神经网络(ConvNet)和循环神经网络(RNN)的组合来实现视觉里程计的端到端学习。DeepVO框架由于其在端到端学习方面的专业化,成为实现VO监督学习的典型选择。图4(a)显示了这种基于RNN+ConvNet的VO系统的架构,该系统通过ConvNet从图像对中提取视觉特征,并通过RNN传递特征以对特征的时间相关性进行建模。其ConvNet编码器基于FlowNet结构来提取适用于光流和自运动估计的视觉特征。使用基于FlowNet的编码器可以被视为将光流的先验知识引入到学习过程中,并有可能防止DeepVO过度拟合到训练数据集。递归模型将历史信息汇总到其隐藏状态中,以便从过去的经验和来自传感器当前观测的ConvNet特征推断输出。它在以真实相机姿势作为标签的大规模数据集上进行训练。为了恢复框架的最优参数θ∗,优化目标是最小化估计平移p^∈R3和基于欧拉角的旋转φ^∈R3的均方误差(MSE):
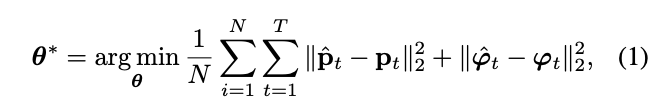
其中(p^t,φ^t)是时间步长t的相对位姿估计,(p,φ)是相应的真实值,θ是DNN框架的参数,N是样本数。

DeepVO展示了在估计驾驶车辆姿态方面的令人印象深刻的结果,即使在以前看不见的场景中也是如此。在KITTI里程计数据集[46]的实验中,这种数据驱动的解决方案优于传统的代表性单目VO,例如VISO2[47]和ORB-SLAM(没有闭环)[21]。另一个优点是监督VO自然地产生具有来自单目相机的绝对尺度的轨迹,而经典的VO算法仅使用单目信息是尺度模糊的。这是因为深度神经网络可以从大量图像中隐式地学习和维护全局尺度,这可以看作是从过去的经验中学习来预测当前的尺度度量。
基于这种典型的监督VO模型,许多工作进一步扩展了这种方法以提高模型性能。为了提高监督VO的泛化能力,[48]结合了课程学习(即通过增加数据复杂度来训练模型)和几何损失约束。知识蒸馏(即通过教授一个较小的模型来压缩一个大模型)被应用到有监督的VO框架中,以大大减少网络参数的数量,使其更适合在移动设备上进行实时操作[49]。此外,薛等人[50]引入了一个存储全局信息的内存模块,以及一个使用保留的上下文信息改进姿势估计的精炼模块。
[48] M. R. U. Saputra, P. P. de Gusmao, S. Wang, A. Markham, andN. Trigoni, “Learning monocular visual odometry through geometry aware curriculum learning,” in 2019 International Conference onRobotics and Automation (ICRA), pp. 3549–3555, IEEE, 2019.
[49] M. R. U. Saputra, P. P. de Gusmao, Y. Almalioglu, A. Markham,and N. Trigoni, “Distilling knowledge from a deep pose regressor network,” in Proceedings of the IEEE International Conference onComputer Vision (ICCV), pp. 263–272, 2019.
[50] F. Xue, X. Wang, S. Li, Q. Wang, J. Wang, and H. Zha, “Beyondtracking: Selecting memory and refining poses for deep visual odometry,” in Proceedings of the IEEE Conference on ComputerVision and Pattern Recognition (CVPR), pp. 8575–8583, 2019.
总之,这些端到端学习方法受益于机器学习技术和计算能力的最新进展,可以直接从原始图像中自动学习姿态变换,从而解决具有挑战性的现实世界里程计估计。
3.1.2 无监督的VO学习
人们对探索VO的无监督学习越来越感兴趣。无监督解决方案能够利用未标记的传感器数据,因此它可以节省标记数据的人力,并且在没有标记数据的新场景中具有更好的适应和泛化能力。这是在一个自监督框架中实现的,该框架通过利用视图合成作为监督信号,从视频序列中联合学习深度和相机自我运动【29】。
[29] T. Zhou, M. Brown, N. Snavely, and D. G. Lowe, “Unsupervised Learning of Depth and Ego-Motion from Video,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
如图4(b)所示,一个典型的无监督VO解决方案由一个用于预测深度图的深度网络和一个用于在图像之间产生运动变换的位姿网络组成。整个框架以连续图像为输入,监督信号基于新颖的视图合成——给定一个源图像Is,视图合成任务是生成合成的目标图像It。源图像Is(ps)的像素通过以下方式投影到目标视图It(pt)上:
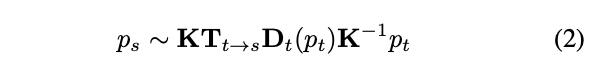
其中K是相机的固有矩阵,Tt→s表示从目标帧到源帧的相机运动矩阵,Dt(pt)表示目标帧中的每像素深度图。训练目标是通过优化真实目标图像和合成图像之间的光度重建损失来确保场景几何的一致性:
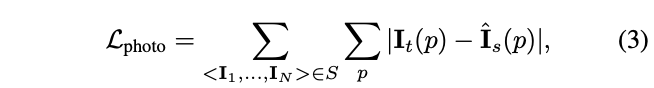
其中p表示像素坐标,It是目标图像,^Is是从源图像Is生成的合成目标图像。
然而,在原始工作[29]中基本上有两个主要问题仍未解决:1)这种基于单目图像的方法无法在一致的全局范围内提供姿势估计。由于尺度的模糊性,无法重建具有物理意义的全局轨迹,从而限制了它的实际使用。2)光度损失假设场景是静态的并且没有相机遮挡。尽管作者提出使用可解释性掩码来消除场景动态,但这些环境因素的影响仍未完全解决,这违反了假设。为了解决这些问题,越来越多的作品[53]、[55]、[56]、[58]、[59]、[61]、[64]、[76]、[77]将此无监督框架扩展到达到更好的性能。
[58] N. Yang, R. Wang, J. Stuckler, and D. Cremers, “Deep virtual stereo odometry: Leveraging deep depth prediction for monocular direct sparse odometry,” in Proceedings of the European Conference on Computer Vision (ECCV), pp. 817–833, 2018.
[64] Y. Li, Y. Ushiku, and T. Harada, “Pose graph optimization for unsupervised monocular visual odometry,” in 2019 International Conference on Robotics and Automation (ICRA), pp. 5439–5445, IEEE, 2019.
[76] S. Li, F. Xue, X. Wang, Z. Yan, and H. Zha, “Sequential adversarial learning for self-supervised deep visual odometry,” in Proceedings of the IEEE International Conference on Computer Vision (ICCV), pp. 2851–2860, 2019.
[77] L. Sheng, D. Xu, W. Ouyang, and X. Wang, “Unsupervised collaborative learning of keyframe detection and visual odometry towards monocular deep slam,” in Proceedings of the IEEE International Conference on Computer Vision (ICCV), pp. 4302–4311, 2019.
为了解决全局尺度问题,[53]、[56]提出利用立体图像对来恢复姿态估计的绝对尺度。他们在左右图像对之间引入了额外的空间光度损失,因为立体基线(即左右图像之间的运动变换)是固定的并且在整个数据集中都是已知的。训练完成后,网络仅使用单目图像生成姿势预测。因此,尽管它在无法访问地面实况的情况下是无监督的,但训练数据集(立体)与测试集(单声道)不同。【30】通过引入几何一致性损失来解决尺度问题,该损失强制预测深度图和重建深度图之间的一致性。该框架将预测的深度图转换为3D空间,并将它们投影回去以生成重建的深度图。这样做,深度预测能够在连续帧上保持尺度一致,同时使姿态估计保持尺度一致。
[53] R. Li, S. Wang, Z. Long, and D. Gu, “Undeepvo: Monocular visual odometry through unsupervised deep learning,” in 2018 IEEE international conference on robotics and automation (ICRA), pp. 7286– 7291, IEEE, 2018.
[56] H. Zhan, R. Garg, C. S. Weerasekera, K. Li, H. Agarwal, and I. Reid, “Unsupervised Learning of Monocular Depth Estimation and Visual Odometry with Deep Feature Reconstruction,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 340–349, 2018.
[30] J. Bian, Z. Li, N. Wang, H. Zhan, C. Shen, M.-M. Cheng, and I. Reid, “Unsupervised scale-consistent depth and ego-motion learning from monocular video,” in Advances in Neural Information Processing Systems, pp. 35–45, 2019.
光度一致性约束假设整个场景仅由刚性静态结构组成,例如建筑物和车道。然而,在实际应用中,环境动态(例如行人和车辆)会扭曲光度投影并降低姿态估计的准确性。为了解决这个问题,GeoNet[55]通过刚性结构重建器和非刚性运动定位器分别估计静态场景结构和运动动力学,将其学习过程分为两个子任务。此外,GeoNet强制几何一致性损失以减轻由相机遮挡和非朗伯曲面引起的问题。【59】添加了一个2D流生成器和一个深度网络来生成3D流。得益于对环境更好的3D理解,他们的框架能够生成更准确的相机姿势以及点云图。GANVO【61】采用生成对抗学习范式进行深度生成,并引入了用于姿势回归的时间循环模块。李等人【76】还利用生成对抗网络(GAN)来生成更逼真的深度图和姿势,并进一步鼓励目标帧中更准确的合成图像。代替手工制作的度量,采用鉴别器来评估合成图像生成的质量。这样做,生成对抗设置有助于生成的深度图更加丰富和清晰。通过这种方式,可以准确地捕获高级场景感知和表示,并隐含地容忍环境动态。
[55] Z. Yin and J. Shi, “GeoNet: Unsupervised Learning of Dense Depth, Optical Flow and Camera Pose,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
[59] C. Zhao, L. Sun, P. Purkait, T. Duckett, and R. Stolkin, “Learning monocular visual odometry with dense 3d mapping from dense 3d flow,” in 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 6864–6871, IEEE, 2018.
[61] Y. Almalioglu, M. R. U. Saputra, P. P. de Gusmao, A. Markham, and N. Trigoni, “Ganvo: Unsupervised deep monocular visual odometry and depth estimation with generative adversarial networks,” in 2019 International Conference on Robotics and Automation (ICRA), pp. 5474–5480, IEEE, 2019.
尽管无监督VO在性能上仍然无法与有监督VO竞争,如图5所示,但其对尺度度量和场景动态问题的担忧已在很大程度上得到解决。凭借自监督学习的优势和不断提高的性能,无监督VO将成为提供姿势信息的有前途的解决方案,并与空间机器智能系统中的其他模块紧密耦合。
3.1.3 混合模式VO
与仅依靠深度神经网络从数据中解释姿态的端到端VO不同,混合VO将经典几何模型与深度学习框架相结合。基于成熟的几何理论,他们使用深度神经网络来表达地替换几何模型的一部分。
一种直接的方法是将学习到的深度估计合并到传统的视觉里程计算法中,以恢复姿势的绝对尺度度量[52]。学习深度估计是计算机视觉社区中一个经过充分研究的领域。例如,[78]、[79]、[80]、[81]通过采用经过训练的深度神经模型,在全局范围内提供每像素深度。因此,传统VO的所谓规模问题得到了缓解。巴恩斯等人[54]在VO系统中利用预测的深度图和临时掩码(即移动物体的区域)来提高其对移动物体的鲁棒性。詹等人[67]将学习到的深度和光流预测集成到传统的视觉里程计模型中,实现了与其他基线相比具有竞争力的性能。其他作品将物理运动模型与深度神经网络相结合,例如通过可微卡尔曼滤波器[82]和粒子滤波器[83]。物理模型在学习过程中充当算法先验。此外,D3VO[25]将深度、姿势和不确定性的深度预测结合到直接视觉里程计中。
[25] N. Yang, L. von Stumberg, R. Wang, and D. Cremers, “D3vo: Deep depth, deep pose and deep uncertainty for monocular visual odometry,” CVPR, 2020.
[52] X. Yin, X. Wang, X. Du, and Q. Chen, “Scale recovery for monocular visual odometry using depth estimated with deep convolutional neural fields,” in Proceedings of the IEEE International Conference on Computer Vision, pp. 5870–5878, 2017.
[54] D. Barnes, W. Maddern, G. Pascoe, and I. Posner, “Driven to distraction: Self-supervised distractor learning for robust monocular visual odometry in urban environments,” in 2018 IEEE International Conference on Robotics and Automation (ICRA), pp. 1894–1900, IEEE, 2018.
[67] H. Zhan, C. S. Weerasekera, J. Bian, and I. Reid, “Visual odometry revisited: What should be learnt?,” The International Conference on Robotics and Automation (ICRA), 2020.
[78] D. Eigen, C. Puhrsch, and R. Fergus, “Depth map prediction from a single image using a multi-scale deep network,” in Advances in neural information processing systems, pp. 2366–2374, 2014.
[79] B. Ummenhofer, H. Zhou, J. Uhrig, N. Mayer, E. Ilg, A. Dosovitskiy, and T. Brox, “Demon: Depth and motion network for learning monocular stereo,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 5038–5047, 2017.
[80] R. Garg, V. K. BG, G. Carneiro, and I. Reid, “Unsupervised cnn for single view depth estimation: Geometry to the rescue,” in European Conference on Computer Vision, pp. 740–756, Springer, 2016.
[81] C. Godard, O. Mac Aodha, and G. J. Brostow, “Unsupervised monocular depth estimation with left-right consistency,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 270–279, 2017.
[82] T. Haarnoja, A. Ajay, S. Levine, and P. Abbeel, “Backprop KF: Learning Discriminative Deterministic State Estimators,” in Advances In Neural Information Processing Systems (NeurIPS), 2016.
[83] R. Jonschkowski, D. Rastogi, and O. Brock, “Differentiable Particle Filters: End-to-End Learning with Algorithmic Priors,” in Robotics: Science and Systems, 2018.
结合几何理论和深度学习的优势,混合模型在这个阶段通常比端到端VO更准确,如表1所示。值得注意的是,混合模型甚至优于最先进的模型常规单目VO或视觉惯性里程计(VIO)系统在常见基准上,例如D3VO【25】击败了几个流行的常规VO/VIO系统,例如DSO[84]、ORB-SLAM[21]、VINS-Mono[15]这表明该领域的进展速度很快。
[84] L. Von Stumberg, V. Usenko, and D. Cremers, “Direct sparse visual-inertial odometry using dynamic marginalization,” in 2018 IEEE International Conference on Robotics and Automation (ICRA), pp. 2510–2517, IEEE, 2018.
3.2 视觉-惯性里程计
将视觉和惯性数据集成为视觉惯性里程计(VIO)是移动机器人技术中一个明确定义的问题。相机和惯性传感器都相对低成本、高能效且部署广泛。这两个传感器是互补的:单目相机捕捉3D场景的外观和结构,但它们的尺度不明确,并且对具有挑战性的场景不鲁棒,例如:强烈的光照变化、缺乏质感和高速运动;相比之下,IMU完全以自我为中心,独立于场景,还可以提供绝对的度量尺度。然而,缺点是惯性测量,尤其是来自低成本设备的测量,受到过程噪声和偏差的困扰。来自这两个互补传感器的测量值的有效融合对于准确的姿态估计至关重要。因此,根据他们的信息融合方法,传统的基于模型的视觉惯性方法大致分为三个不同的类别:滤波方法[12]、固定滞后平滑器[13]和完全平滑方法[14]。
[12] M. Li and A. I. Mourikis, “High-precision, Consistent EKF-based Visual-Inertial Odometry,” The International Journal of Robotics Research, vol. 32, no. 6, pp. 690–711, 2013.
[13] S. Leutenegger, S. Lynen, M. Bosse, R. Siegwart, and P. Furgale, “Keyframe-Based VisualInertial Odometry Using Nonlinear Optimization,” The International Journal of Robotics Research, vol. 34, no. 3, pp. 314–334, 2015.
[14] C. Forster, L. Carlone, F. Dellaert, and D. Scaramuzza, “OnManifold Preintegration for Real-Time Visual-Inertial Odometry,” IEEE Transactions on Robotics, vol. 33, no. 1, pp. 1–21, 2017.
数据驱动的方法已经出现,可以考虑直接从视觉和惯性测量中学习6自由度姿势,而无需人工干预或校准。VINet[68]是第一个将视觉惯性里程计定义为顺序学习问题的工作,并提出了一种深度神经网络框架以端到端的方式实现VIO。VINet使用基于ConvNet的视觉编码器从两个连续的RGB图像中提取视觉特征,并使用惯性编码器从具有长短期记忆(LSTM)网络的IMU数据序列中提取惯性特征。在这里,LSTM旨在对惯性数据的时间状态演化进行建模。视觉和惯性特征连接在一起,并作为另一个LSTM模块的输入,以预测相对姿势,以系统状态的历史为条件。这种学习方法的优点是对校准和相对时序偏移误差更加稳健。然而,VINet并没有完全解决学习有意义的传感器融合策略的问题。
[68] R. Clark, S. Wang, H. Wen, A. Markham, and N. Trigoni, “VINet : Visual-Inertial Odometry as a Sequence-to-Sequence Learning Problem,” in The AAAI Conference on Artificial Intelligence (AAAI), pp. 3995–4001, 2017.
[69] E. J. Shamwell, K. Lindgren, S. Leung, and W. D. Nothwang, “Unsupervised deep visual-inertial odometry with online error correction for rgb-d imagery,” IEEE transactions on pattern analysis and machine intelligence, 2019.
[70] C. Chen, S. Rosa, Y. Miao, C. X. Lu, W. Wu, A. Markham, and N. Trigoni, “Selective sensor fusion for neural visual-inertial odometry,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 10542–10551, 2019.
[71] L. Han, Y. Lin, G. Du, and S. Lian, “Deepvio: Self-supervised deep learning of monocular visual inertial odometry using 3d geometric constraints,” arXiv preprint arXiv:1906.11435, 2019.
为了解决深度传感器融合问题,Chen等人[70]提出了选择性传感器融合,这是一个有选择地学习视觉惯性姿态估计的上下文相关表示的框架。他们的直觉是,通过充分利用两个传感器的互补行为,应根据外部(即环境)和内部(即设备/传感器)动力学来考虑不同模态特征的重要性。他们的方法优于那些没有融合策略的方法,例如VINet,避免灾难性故障。
与无监督VO类似,视觉惯性里程计也可以使用新颖的视图合成以自我监督的方式解决。VIOLearner[69]从原始惯性数据构造运动变换,并通过第3.1.2节中提到的公式2将源图像转换为具有相机矩阵和深度图的目标图像。此外,在线纠错模块纠正框架的中间错误。通过优化光度损失来恢复网络参数。类似地,DeepVIO[71]将惯性数据和立体图像合并到这个无监督学习框架中,并使用专用损失进行训练,以在全局范围内重建轨迹。
基于学习的VIO无法击败最先进的基于经典模型的VIO,但它们通常更能应对实际问题[68]、[70]、[71],例如测量噪声、时间同步不良,这要归功于DNN在特征提取和运动建模方面令人印象深刻的能力。
3.3 惯性里程计
除了视觉里程计和视觉惯性里程计,仅惯性解决方案,即惯性里程计提供了解决里程计估计问题的普遍替代方案。与视觉方法相比,惯性传感器成本相对较低、体积小、节能且保护隐私。它相对不受环境因素的影响,例如照明条件或移动物体。然而,广泛存在于机器人和移动设备上的低成本MEMS惯性测量单元(IMU)会因高传感器偏差和噪声而损坏,如果对惯性数据进行双重集成,则会导致捷联惯性导航系统(SINS)中的无界误差漂移。
陈等人[85]将惯性里程计公式化为一个顺序学习问题,其关键观察是极坐标(即极向量)中的二维运动位移可以从分段惯性数据的独立窗口中学习。关键观察结果是,在跟踪人类和轮式配置时,它们的振动频率与移动速度有关,这通过惯性测量得到反映。基于此,他们提出了IONet,这是一个基于LSTM的框架,用于从惯性测量序列中端到端学习相对姿势。轨迹是通过整合运动位移生成的。[86]利用深度生成模型和领域适应技术来提高深度惯性里程计在新领域的泛化能力。[87]通过改进的三通道LSTM网络扩展了该框架,以根据惯性数据和采样时间预测无人机定位的极坐标。RIDI[88]训练深度神经网络从惯性数据中回归线速度,校准收集的加速度以满足学习速度的约束,并使用传统物理模型将加速度双重整合到位置。类似地,[89]借助学习速度补偿了经典SINS模型的误差漂移。其他工作也探索了使用深度学习来检测导航行人[90]和车辆[91]的零速度阶段。这个零速度阶段通过卡尔曼滤波提供上下文信息来纠正系统误差漂移。
[85] C. Chen, X. Lu, A. Markham, and N. Trigoni, “Ionet: Learning to cure the curse of drift in inertial odometry,” in Thirty-Second AAAI Conference on Artificial Intelligence, 2018.
[86] C. Chen, Y. Miao, C. X. Lu, L. Xie, P. Blunsom, A. Markham, and N. Trigoni, “Motiontransformer: Transferring neural inertial tracking between domains,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 33, pp. 8009–8016, 2019.
[87] M. A. Esfahani, H. Wang, K. Wu, and S. Yuan, “Aboldeepio: A novel deep inertial odometry network for autonomous vehicles,” IEEE Transactions on Intelligent Transportation Systems, 2019.
[88] H. Yan, Q. Shan, and Y. Furukawa, “Ridi: Robust imu double integration,” in Proceedings of the European Conference on Computer Vision (ECCV), pp. 621–636, 2018. [89] S. Cortes, A. Solin, and J. Kannala, “Deep learning based speed ´ estimation for constraining strapdown inertial navigation on smartphones,” in 2018 IEEE 28th International Workshop on Machine Learning for Signal Processing (MLSP), pp. 1–6, IEEE, 2018.
[90] B. Wagstaff and J. Kelly, “Lstm-based zero-velocity detection for robust inertial navigation,” in 2018 International Conference on Indoor Positioning and Indoor Navigation (IPIN), pp. 1–8, IEEE, 2018.
[91] M. Brossard, A. Barrau, and S. Bonnabel, “Rins-w: Robust inertial navigation system on wheels,” 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2019.
仅惯性解决方案可以是在视觉信息不可用或高度失真的极端环境中提供姿势信息的备用计划。深度学习已经证明了它能够从嘈杂的IMU数据中学习有用的特征,并补偿传统算法难以解决的惯性航位推算的误差漂移。
3.4 激光里程计
激光雷达传感器提供高频范围测量,具有在复杂照明条件和光学无特征场景中始终如一地工作的优势。移动机器人和自动驾驶车辆通常配备LIDAR传感器以获得相对自运动(即LIDAR 里程计)和相对于3D地图的全局位姿(LIDAR重定位)。LIDAR里程计的性能对由于非平滑运动引起的点云配准误差很敏感。此外,激光雷达测量的数据质量还受到极端天气条件的影响,例如大雨或雾/薄雾。
传统上,LIDAR里程计依赖于点云配准来检测特征点,例如线段和曲面段,并使用匹配算法通过最小化两个连续点云扫描之间的距离来获得位姿变换。数据驱动的方法考虑以端到端的方式解决LIDAR里程计,通过利用深度神经网络构建从点云扫描序列到姿态估计的映射函数[72]、[73]、[74]。由于点云数据由于其稀疏和不规则的采样格式而难以直接被神经网络摄取,这些方法通常通过圆柱投影将点云转换为规则矩阵,并采用ConvNets从连续的点云扫描中提取特征。这些网络回归相对姿势,并通过真实标签进行训练。LO-Net[73]报告了与传统的最先进算法(即LIDAR里程计和建图(LOAM)算法[16])相比具有竞争力的性能。
[72] M. Velas, M. Spanel, M. Hradis, and A. Herout, “Cnn for imu assisted odometry estimation using velodyne lidar,” in 2018 IEEE International Conference on Autonomous Robot Systems and Competitions (ICARSC), pp. 71–77, IEEE, 2018.
[73] Q. Li, S. Chen, C. Wang, X. Li, C. Wen, M. Cheng, and J. Li, “Lonet: Deep real-time lidar odometry,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 8473–8482, 2019.
[74] W. Wang, M. R. U. Saputra, P. Zhao, P. Gusmao, B. Yang, C. Chen, A. Markham, and N. Trigoni, “Deeppco: End-to-end point cloud odometry through deep parallel neural network,” The 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2019), 2019.
3.5 里程计估计对比

表1比较了现有的里程计估计工作,包括传感器类型、模型、是否产生具有绝对比例的轨迹,以及它们在KITTI数据集上的性能评估(如果可用)。由于尚未在KITTI数据集上评估深度惯性里程计,因此我们在此表中不包括惯性里程计。KITTI数据集【46】是里程估计的通用基准,由来自汽车驾驶场景的传感器数据集合组成。由于大多数数据驱动方法采用KITTI数据集的轨迹09和10来评估模型性能,我们根据所有长度子序列(100、200、. ., 800)米,由官方KITTI VO/SLAM评估指标提供。
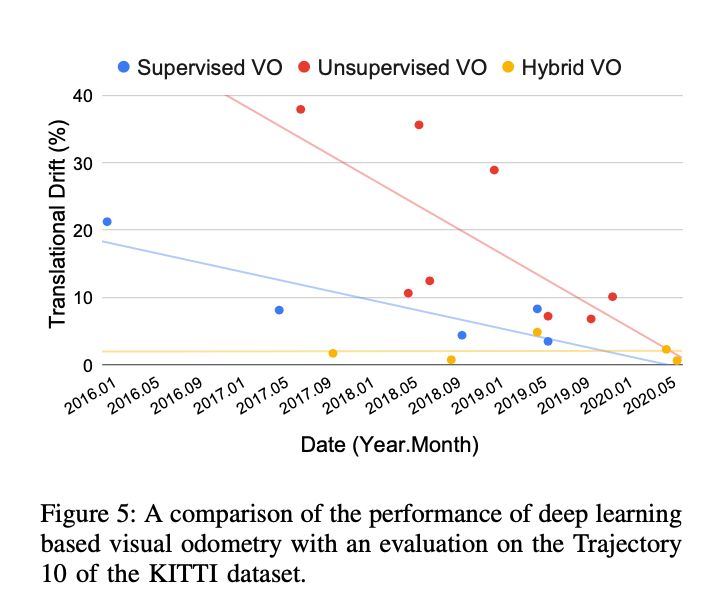
我们以视觉里程计为例。图5报告了深度视觉里程计模型在KITTI数据集的第10条轨迹上随时间推移的平移漂移。显然,混合VO表现出优于有监督VO和无监督 VO 的性能,因为混合模型受益于传统VO算法成熟的几何模型和深度学习的强大特征提取能力。尽管有监督的VO仍然优于无监督的VO,但随着无监督VO的局限性逐渐得到解决,它们之间的性能差距正在缩小。例如,已经发现无监督VO现在可以从单目图像中恢复全局尺度[30]。总体而言,数据驱动的视觉里程计显示模型性能显着提高,表明深度学习方法在未来实现更准确的里程计估计方面的潜力。
四、建图
建图是指移动代理建立一致的环境模型来描述周围场景的能力。深度学习培育了一套用于场景感知和理解的工具,其应用范围从深度预测到语义标注,再到3D几何重建。本节概述了与基于深度学习的建图方法相关的现有工作。我们将它们分为几何建图、语义建图和一般建图。表2总结了基于深度学习的建图的现有方法。

4.1 几何建图
广义地说,几何建图捕捉场景的形状和结构描述。几何建图中使用的场景表示的典型选择包括深度、体素、点和网格。我们遵循这种代表性分类法,并将用于几何建图的深度学习分类为上述四类。图6在Stanford Bunny 基准上展示了这些几何表示。

4.1.1 深度表示
深度图在理解场景几何和结构方面起着关键作用。通过融合深度和RGB图像[119]、[120]实现了密集场景重建。传统的SLAM系统表示具有密集深度图(即2.5D)的场景几何,例如DTAM[121]。此外,准确的深度估计有助于视觉SLAM的绝对尺度恢复。
[119] C. Kerl, J. Sturm, and D. Cremers, “Dense visual slam for rgb-d cameras,” in 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems, pp. 2100–2106, IEEE, 2013.
[120] T. Whelan, M. Kaess, H. Johannsson, M. Fallon, J. J. Leonard, and J. McDonald, “Real-time large-scale dense rgb-d slam with volumetric fusion,” The International Journal of Robotics Research, vol. 34, no. 4-5, pp. 598–626, 2015.
[121] R. A. Newcombe, S. J. Lovegrove, and A. J. Davison, “DTAM : Dense Tracking and Mapping in Real-Time,” in IEEE International Conference on Computer Vision (ICCV), pp. 2320–2327, 2011.
从原始图像中学习深度是计算机视觉社区中一个快速发展的领域。最早的工作将深度估计公式化为输入单个图像的映射函数,由多尺度深度神经网络[78]构建,以输出单个图像的每像素深度图。通过联合优化深度和自运动估计来实现更准确的深度预测[79]。这些监督学习方法[78]、[79]、[92]可以通过在具有相应深度标签的大型图像数据集合上训练深度神经网络来预测每像素深度。尽管发现它们的性能优于传统的基于结构的方法,例如[122],但它们的有效性在很大程度上依赖于模型训练,并且在没有标记数据的情况下难以推广到新场景。
另一方面,该领域的最新进展集中在无监督解决方案上,将深度预测重新定义为一个新的视图合成问题。[80]、[81]利用光度一致性损失作为训练神经模型的自我监督信号。使用立体图像和已知的相机基线,[80]、[81]从右图像合成左视图,以及左视图的预测深度图。通过最小化合成图像和真实图像之间的距离,即空间一致性,可以通过这种端到端的自我监督来恢复网络的参数。除了空间一致性之外,[29]还提出通过从源时间帧合成目标时间帧中的图像,将时间一致性用作自监督信号。同时,自我运动与深度估计一起被恢复。这个框架只需要单目图像来学习深度图和自我运动。以下许多作品[53]、[55]、[56]、[58]、[59]、[61]、[64]、[76]、[77]、[93]扩展了这个框架并取得了更好的效果深度估计和自我运动估计的性能。我们请读者参考第3.1.2节,其中讨论了各种附加约束。
[80] R. Garg, V. K. BG, G. Carneiro, and I. Reid, “Unsupervised cnn for single view depth estimation: Geometry to the rescue,” in European Conference on Computer Vision, pp. 740–756, Springer, 2016.
[81] C. Godard, O. Mac Aodha, and G. J. Brostow, “Unsupervised monocular depth estimation with left-right consistency,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 270–279, 2017.
借助ConvNets预测的深度图,基于学习的SLAM系统可以整合深度信息来解决经典单目解决方案的一些局限性。例如,CNN-SLAM[123]利用从单个图像中学习到的深度进入单目SLAM框架(即LSD-SLAM[124])。他们的实验展示了学习的深度图如何有助于缓解姿态估计和场景重建中的绝对尺度恢复问题。CNN-SLAM即使在无纹理区域也能实现密集场景预测,这对于传统的SLAM系统来说通常是困难的。
4.1.2 体素表示
基于体素的公式是表示3D几何的自然方式。类似于图像中像素(即二维元素)的使用,体素是三维空间中的体积元素。以前的工作已经探索了使用多个输入视图来重建场景[94]、[95]和对象[96]的体积表示。例如,SurfaceNet[94]学习预测体素的置信度以确定它是否在表面上,并重建场景的2D表面。RayNet[95]通过在施加几何约束的同时提取视图不变特征来重构场景几何。最近的工作重点是生成高分辨率3D体积模型[97]、[98]。例如,塔塔尔琴科等人[97]设计了一个基于八叉树公式的卷积解码器,以实现更高分辨率的场景重建。可以从RGB-D数据[99]、[100]中找到关于场景完成的其他工作。体素表示的一个限制是高计算要求,尤其是在尝试以高分辨率重建场景时。
[97] M. Tatarchenko, A. Dosovitskiy, and T. Brox, “Octree generating networks: Efficient convolutional architectures for high-resolution 3d outputs,” in Proceedings of the IEEE International Conference on Computer Vision, pp. 2088–2096, 2017.
[98] C. Hane, S. Tulsiani, and J. Malik, “Hierarchical surface prediction ¨ for 3d object reconstruction,” in 2017 International Conference on 3D Vision (3DV), pp. 412–420, IEEE, 2017.
4.1.3 点云表示
基于点的公式由3D空间中点的3维坐标(x,y,z)组成。点表示易于理解和操作,但存在歧义问题,这意味着不同形式的点云可以表示相同的几何图形。开创性的工作,PointNet[125],使用单个对称函数-最大池化处理无序点数据,以聚合点特征以进行分类和分割。范等人[101]开发了一种深度生成模型,可以从单个图像以基于点的公式生成3D几何。在他们的工作中,引入了基于Earth Mover距离的损失函数来解决数据模糊问题。然而,他们的方法仅在单个对象的重建任务上得到验证。尚未发现用于场景重建的点生成工作。
4.1.4 网格表示
基于网格的公式对3D模型的底层结构进行编码,例如边、顶点和面。它是自然捕捉3D形状表面的强大表示。一些工作考虑了从图像[102]、[103]或点云数据[104]、[105]中学习网格生成的问题。然而,这些方法只能重建单个对象,并且仅限于生成具有简单结构或熟悉类的模型。为了解决网格表示中的场景重建问题,[106]将来自单目SLAM的稀疏特征与来自ConvNet的密集深度图相结合,用于更新3D网格表示。将深度预测融合到单目SLAM系统中,以恢复姿态和场景特征估计的绝对尺度。为了实现高效的计算和灵活的信息融合,[107]利用2.5D网格来表示场景几何。在他们的方法中,网格顶点的图像平面坐标由深度神经网络学习,而深度图作为自由变量优化。
[106] T. Mukasa, J. Xu, and B. Stenger, “3d scene mesh from cnn depth predictions and sparse monocular slam,” in Proceedings of the IEEE International Conference on Computer Vision Workshops, pp. 921– 928, 2017.
[107] M. Bloesch, T. Laidlow, R. Clark, S. Leutenegger, and A. J. Davison, “Learning meshes for dense visual slam,” in Proceedings of the IEEE International Conference on Computer Vision, pp. 5855–5864, 2019.
4.2 语义建图
语义映射将语义概念(即对象分类、材料组成等)与环境几何联系起来。这被视为数据关联问题。深度学习的进步极大地促进了对象识别和语义分割的发展。具有语义含义的地图使移动代理能够对其环境进行高级别的理解,超越纯几何,并允许更大范围的功能和自主性。
语义融合[26]是早期的作品之一,它将来自深度卷积网络的语义分割标签与来自SLAM系统的密集场景几何相结合。它通过将2D帧与3D地图概率关联,将每帧语义分割预测逐步集成到密集的3D地图中。这种组合不仅生成了具有有用语义信息的地图,而且还表明与SLAM系统的集成有助于增强单帧分割。这两个模块在SemanticFusion中松散耦合。[27]提出了一种自我监督网络,通过对多个视图中语义预测的一致性施加约束来预测地图的一致语义标签。DA-RNN[108]将循环模型引入语义分割框架中,以学习多个视图帧上的时间连接,从而为来自KinectFusion[127]的体积图生成更准确和一致的语义标记。然而,这些方法没有提供有关对象实例的信息,这意味着它们无法区分来自同一类别的不同对象。
随着实例分割的进步,语义映射演变为实例级别。一个很好的例子是[109],它通过边界框检测模块和无监督几何分割模块识别单个对象来提供对象级语义映射。与其他密集语义映射方法不同,Fusion++[110]构建了一个基于语义图的映射,它仅预测对象实例并通过闭环检测、位姿图优化和进一步细化来保持一致的映射。[111]提出了一个框架,该框架实现了实例感知语义映射,并实现了新的对象发现。最近,全景分割[126]引起了很多关注。PanopticFusion[112]高级语义映射到对静态对象进行分类的事物和事物级别,例如墙壁、门、车道作为东西类,以及其他负责的对象作为东西类,例如。移动车辆、人员和桌子。图7比较了语义分割、实例分割和全景分割。
[108] Y. Xiang and D. Fox, “Da-rnn: Semantic mapping with data associated recurrent neural networks,” Robotics: Science and Systems, 2017.
[109] N. Sunderhauf, T. T. Pham, Y. Latif, M. Milford, and I. Reid, ¨ “Meaningful maps with object-oriented semantic mapping,” in 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 5079–5085, IEEE, 2017.
[110] J. McCormac, R. Clark, M. Bloesch, A. Davison, and S. Leutenegger, “Fusion++: Volumetric object-level slam,” in 2018 international conference on 3D vision (3DV), pp. 32–41, IEEE, 2018.
[111] M. Grinvald, F. Furrer, T. Novkovic, J. J. Chung, C. Cadena, R. Siegwart, and J. Nieto, “Volumetric instance-aware semantic mapping and 3d object discovery,” IEEE Robotics and Automation Letters, vol. 4, no. 3, pp. 3037–3044, 2019.
[112] G. Narita, T. Seno, T. Ishikawa, and Y. Kaji, “Panopticfusion: Online volumetric semantic mapping at the level of stuff and things,” IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2019.
[126] A. Kirillov, K. He, R. Girshick, C. Rother, and P. Dollar, “Panoptic ´ segmentation,” in Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 9404–9413, 2019.

4.3 通用地图
除了显式的几何和语义地图表示之外,深度学习模型还能够将整个场景编码为隐式表示,即捕捉底层场景几何和外观的通用地图表示。
利用深度自动编码器可以自动发现高维数据的高级紧凑表示。一个值得注意的例子是CodeSLAM[113],它将观察到的图像编码为紧凑且可优化的表示,以包含密集场景的基本信息。这种通用表示进一步用于基于关键帧的SLAM系统,以推断姿势估计和关键帧深度图。由于学习表示的大小减小,CodeSLAM允许有效优化跟踪相机运动和场景几何以实现全局一致性。
[113] M. Bloesch, J. Czarnowski, R. Clark, S. Leutenegger, and A. J. Davison, “CodeSLAM Learning a Compact, Optimisable Representation for Dense Visual SLAM,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
神经元渲染模型是另一个通过利用视图合成作为自我监督信号来学习对3D场景结构进行隐式建模的作品。神经元渲染任务的目标是从未知视点重建新场景。研讨会工作,生成查询网络(GQN)[128]学习捕获表示并渲染新场景。GQN由表示网络和生成网络组成:表示网络将来自参考视图的观察编码为场景表示;基于循环模型的生成网络根据场景表示和随机潜变量从新视图重建场景。GQN将输入作为从多个视点观察到的图像,以及新视图的相机姿态,预测这个新视图的物理场景。直观地说,通过端到端训练,表示网络可以通过生成网络捕获场景重建任务所需的3D环境的必要和重要因素。GQN通过结合几何感知注意机制进行扩展,以允许更复杂的环境建模[114],以及包括用于场景推理的多模态数据[115]。场景表示网络(SRN)[116]通过学习的连续场景表示来解决场景渲染问题,该表示连接相机姿势及其相应的观察。SRN中集成了一个可微的Ray Marching算法,以强制网络始终如一地对3D结构进行建模。然而,由于现实世界环境的复杂性,这些框架只能应用于合成数据集。
[114] J. Tobin, W. Zaremba, and P. Abbeel, “Geometry-aware neural rendering,” in Advances in Neural Information Processing Systems, pp. 11555–11565, 2019.
[115] J. H. Lim, P. O. Pinheiro, N. Rostamzadeh, C. Pal, and S. Ahn, “Neural multisensory scene inference,” in Advances in Neural Information Processing Systems, pp. 8994–9004, 2019.
[116] V. Sitzmann, M. Zollhofer, and G. Wetzstein, “Scene representation networks: Continuous 3d-structure-aware neural scene representations,” in Advances in Neural Information Processing Systems, pp. 1119–1130, 2019.
[128] S. A. Eslami, D. J. Rezende, F. Besse, F. Viola, A. S. Morcos, M. Garnelo, A. Ruderman, A. A. Rusu, I. Danihelka, K. Gregor, et al., “Neural scene representation and rendering,” Science, vol. 360, no. 6394, pp. 1204–1210, 2018.
最后但并非最不重要的一点是,在寻求“无地图”导航的过程中,任务驱动的地图作为一种新颖的地图表示形式出现。这种表示是由深度神经网络针对手头的任务联合建模的。通常,这些任务利用位置信息,例如导航或路径规划,要求移动代理了解环境的几何和语义。在这些工作[31]、[32]、[117]、[118]中,非结构化环境(甚至在城市规模)中的导航被表述为一个策略学习问题,并通过深度强化学习来解决。与遵循构建显式地图、规划路径和做出决策的过程的传统解决方案不同,这些基于学习的技术以端到端的方式直接从传感器观察中预测控制信号,而无需对环境进行显式建模。模型参数通过稀疏的奖励信号进行优化,例如,每当代理到达目的地时,都会给予正奖励来调整神经网络。训练模型后,可以根据当前对环境(即图像)的观察来确定代理的动作。在这种情况下,所有环境因素,例如场景的几何、外观和语义,都嵌入到深度神经网络的神经元中,适合解决手头的任务。有趣的是,通过强化学习对导航任务进行训练的神经模型中神经元的可视化与人脑内的网格和位置细胞具有相似的模式。这提供了认知线索来支持神经图表示的有效性。
5 全局定位
全局定位涉及在已知场景中检索移动代理的绝对姿势。与依赖于估计内部动态模型并且可以在看不见的场景中执行的里程计估计不同,在全局定位中,通过2D或3D场景模型提供和利用关于场景的先验知识。从广义上讲,它通过将查询图像或视图与预先构建的模型进行匹配,并返回对全局姿势的估计,来描述传感器观察结果和地图之间的关系。
根据查询数据和地图的类型,我们将基于深度学习的全局定位分为三类:
- 2D到2D定位根据地理参考图像的显式数据库或隐式神经图查询2D图像;
- 2D到3D定位在图像的2D像素和场景模型的3D点之间建立对应关系;
- 3D到3D定位将3D扫描与预先构建的3D地图相匹配。
表3、4和5分别总结了基于深度学习的2D到2D定位、2D到3D定位和3D到3D定位的现有方法。
5.1 2D到2D定位
2D到2D定位将图像的相机位姿回归到2D地图。这种2D地图由地理参考数据库显式构建或隐式编码在神经网络中。
(2D到2D的匹配)
5.1.1 基于显式地图定位
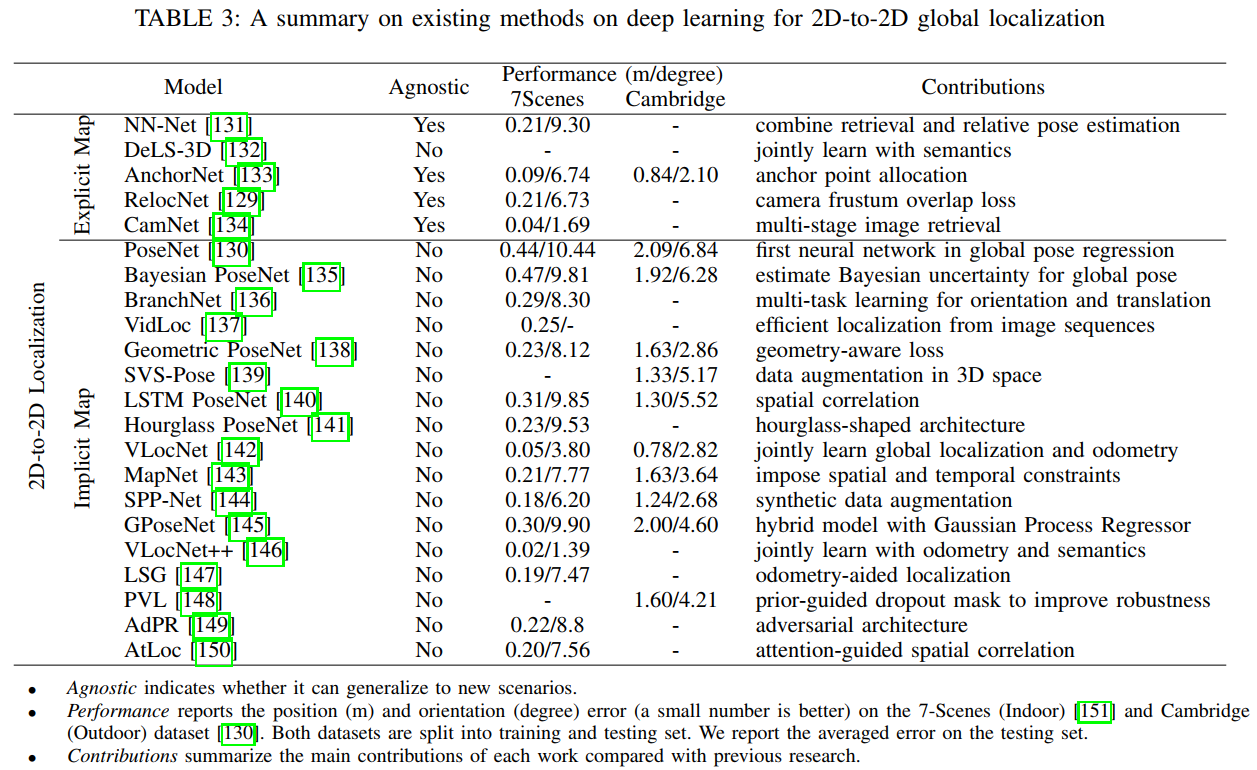
基于显式地图的2D到2D定位通常通过地理标记图像(参考)[152]、[153]、[154]的数据库来表示场景。图8(a)说明了使用2D参考进行定位的两个阶段:图像检索确定由参考图像表示的场景中与视觉查询最相关的部分;位姿回归获得查询图像相对于参考图像的相对位姿。

这里的一个问题是如何为图像检索找到合适的图像描述符。基于深度学习的方法[155]、[156]基于预训练的ConvNet模型来提取图像级特征,然后使用这些特征来评估与其他图像的相似性。在具有挑战性的情况下,首先提取局部描述符,然后聚合以获得鲁棒的全局描述符。一个很好的例子是NetVLAD[157],它设计了一个可训练的广义VLAD(局部聚合描述符的向量)层。这个VLAD层可以插入现成的ConvNet架构,以鼓励更好的描述符学习用于图像检索。
[157] R. Arandjelovic, P. Gronat, A. Torii, T. Pajdla, and J. Sivic, “Netvlad: Cnn architecture for weakly supervised place recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 5297–5307, 2016.
为了获得更精确的查询姿势,需要对检索到的图像进行额外的相对姿势估计。传统上,相对姿态估计是通过对极几何来解决的,依赖于由局部描述符[158]、[159]确定的2D-2D对应关系。相比之下,深度学习方法直接从成对图像中回归相对姿势。例如,NN-Net[131]利用神经网络来估计查询和排名前N的参考之间的成对相对姿势。基于三角测量的融合算法将预测的N个相对位姿与3D几何位姿的ground truth结合起来,可以自然地计算出绝对查询位姿。此外,Relocnet[129]引入了平截头体重叠损失来帮助适合相机定位的全局描述符学习。受此启发,CamNet[134]应用两阶段检索,基于图像的粗略检索和基于姿势的精细检索,以选择最相似的参考帧进行最终精确的姿势估计。无需针对特定场景进行培训,基于参考的方法自然具有可扩展性和灵活性,可以在新场景中使用。由于基于参考的方法需要维护地理标记图像的数据库,因此与基于结构的对应方法相比,它们更容易扩展到大规模场景。总的来说,这些基于图像检索的方法实现了准确性和可扩展性之间的权衡。
[158] Q. Zhou, T. Sattler, M. Pollefeys, and L. Leal-Taixe, “To learn or not to learn: Visual localization from essential matrices,” arXiv preprint arXiv:1908.01293, 2019.
[159] I. Melekhov, A. Tiulpin, T. Sattler, M. Pollefeys, E. Rahtu, and J. Kannala, “Dgc-net: Dense geometric correspondence network,” in 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), pp. 1034–1042, IEEE, 2019.
[131] Z. Laskar, I. Melekhov, S. Kalia, and J. Kannala, “Camera relocalization by computing pairwise relative poses using convolutional neural network,” in Proceedings of the IEEE International Conference on Computer Vision Workshops, pp. 929–938, 2017.
[134] M. Ding, Z. Wang, J. Sun, J. Shi, and P. Luo, “Camnet: Coarse-tofine retrieval for camera re-localization,” in Proceedings of the IEEE International Conference on Computer Vision (ICCV), pp. 2871– 2880, 2019.
5.1.2 基于隐式地图的定位
基于隐式地图的定位通过在深度神经网络中隐式表示整个场景的结构,直接从单个图像中回归相机位姿。常见的管道如图8(b)所示——神经网络的输入是单个图像,而输出是查询图像的全局位置和方向。
PoseNet[130]是第一个通过训练ConvNet以端到端方式从单个RGB图像预测相机姿态来解决相机重新定位问题的工作。PoseNet基于GoogleNet[160]的主要结构来提取视觉特征,但去除了最后的softmax层。相反,引入了一个全连接层来输出一个7维的全局姿态,分别由3维和4维的位置和方向向量组成。然而,PoseNet的设计采用了一个简单的回归损失函数,没有考虑几何,其中内部的超参数需要昂贵的手工工程来调整。此外,由于特征嵌入的高维和有限的训练数据,它还存在过拟合问题。因此,各种扩展通过利用LSTM单元来降低维数[140],应用合成生成来增强训练数据[136]、[139]、[144],用ResNet34[141]替换主干,建模姿势来增强原始管道不确定性[135],[145]并引入几何感知损失函数[138]。或者,Atloc[150]将空间域中的特征与注意力机制相关联,这鼓励网络关注图像中时间一致且鲁棒的部分。同样,在RVL[148]中额外采用了先验引导的dropout掩码,以进一步消除动态对象引起的不确定性。与仅考虑空间连接的此类方法不同,VidLoc[137]结合了图像序列的时间约束来模拟输入图像的时间连接以进行视觉定位。此外,在MapNet[143]中利用了额外的运动约束,包括来自GPS或SLAM系统的空间约束和其他传感器约束,以强制预测姿势之间的运动一致性。通过联合优化重定位网络和视觉里程计网络[142]、[147],也添加了类似的运动约束。然而,由于是特定于应用的,从定位任务中学习的场景表示可能会忽略一些它们并非设计用于的有用特征。除此之外,VLocNet++[146]和FGSN[161]还利用了学习语义和回归姿势之间的任务间关系,取得了令人印象深刻的结果。
[130] A. Kendall, M. Grimes, and R. Cipolla, “Posenet: A convolutional network for real-time 6-dof camera relocalization,” in Proceedings of the IEEE international Conference on Computer Vision (ICCV), pp. 2938–2946, 2015.
[138] A. Kendall and R. Cipolla, “Geometric loss functions for camera pose regression with deep learning,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 5974–5983, 2017.
[143] S. Brahmbhatt, J. Gu, K. Kim, J. Hays, and J. Kautz, “Geometry Aware Learning of Maps for Camera Localization,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 2616–2625, 2018.
[146] N. Radwan, A. Valada, and W. Burgard, “Vlocnet++: Deep multitask learning for semantic visual localization and odometry,” IEEE Robotics and Automation Letters, vol. 3, no. 4, pp. 4407–4414, 2018.
[150] B. Wang, C. Chen, C. X. Lu, P. Zhao, N. Trigoni, and A. Markham, “Atloc: Attention guided camera localization,” arXiv preprint arXiv:1909.03557, 2019.
[161] M. Larsson, E. Stenborg, C. Toft, L. Hammarstrand, T. Sattler, and F. Kahl, “Fine-grained segmentation networks: Self-supervised segmentation for improved long-term visual localization,” in Proceedings of the IEEE International Conference on Computer Vision, pp. 31–41, 2019.
基于隐式地图的定位方法在自动提取特征方面利用了深度学习的优势,这在传统方法容易失败的无特征环境中的全局定位中起着至关重要的作用。然而,场景特定训练的要求禁止它在不重新训练的情况下泛化到看不见的场景。此外,当前基于隐式地图的方法没有显示出与其他基于显式地图的方法相当的性能[162]。
[162] T. Sattler, Q. Zhou, M. Pollefeys, and L. Leal-Taixe, “Understanding the limitations of cnn-based absolute camera pose regression,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 3302–3312, 2019.
5.2 2D到3D的定位
2D到3D定位是指相对于3D场景模型恢复2D图像的相机位姿的方法。该3D地图是在执行全局定位之前通过诸如运动结构(SfM)[43]等方法预先构建的。如图9所示,2D到3D方法通过局部描述符匹配[163]、[164]、[165]或回归3D,在查询图像的2D像素和场景模型的3D点之间建立2D-3D对应关系来自像素块[151]、[166]、[167]、[168]的坐标。然后,通过在RANSAC循环[171]内应用Perspective-n-Point (PnP)求解器[169]、[170],使用这种2D-3D匹配来计算相机位姿。()
(先有3D地图,然后用2D匹配)

5.2.1 基于描述符匹配的定位
描述符匹配方法主要依靠特征检测器和描述符,建立2D输入和3D模型的特征之间的对应关系。根据检测器和描述符在学习过程中的作用,它们可以进一步分为三种类型:检测-然后-描述、检测-和-描述和描述-到-检测。(detect-then-describe, detect-and-describe, and describe-to-detect
)
先检测然后描述方法首先执行特征检测,然后从以每个关键点为中心的patch中提取特征描述符[200],[201]。关键点检测器通常负责通过相应地对patch进行归一化来提供针对可能的实际问题(例如尺度变换、旋转或视点变化)的鲁棒性或不变性。然而,其中一些职责也可能被委托给描述符。常见的管道不同于使用手工制作的检测器[202]、[203]和描述符[204]、[205],取代了描述符[179]、[206]、[207]、[208]、[209]、[210]或检测器[211]、[212]、[213]具有学习的替代方案,或同时学习检测器和描述符[214]、[215]。为了提高效率,特征检测器通常只考虑小的图像区域,并且通常关注低级结构,例如角落或斑点[216]。然后描述符在关键点周围更大的补丁中捕获更高级别的信息。
相比之下,检测和描述方法(detect-and-describe)推进了描述阶段。通过共享来自深度神经网络的表示,SuperPoint[177]、UnSuperPoint[181]和R2D2[188]尝试学习密集特征描述符和特征检测器。然而,它们依赖于不同的解码器分支,这些分支是独立训练的,具有特定的损失。相反,D2-net[182]和ASLFeat[189]在检测和描述之间共享所有参数,并使用同时优化两个任务的联合公式。
类似地,describe-to-detect方法,例如D2D[217]也将检测推迟到稍后阶段,但将这种检测器应用于预先学习的密集描述符以提取一组稀疏的关键点和相应的描述符。密集特征提取先于检测阶段,并在整个图像上密集地执行描述阶段[176]、[218]、[219]、[220]。在实践中,这种方法已显示出比稀疏特征匹配更好的匹配结果,特别是在光照强变化的条件下。区别于这些工作,仅依赖于图像的特征,2D3D匹配网络提出一种学习局部特征的方法,它可以在2D和3D点云上直接进行关键点匹配。类似地,LCD[223]引入了双自动编码器架构,以提取跨域本地描述符。然而,他们仍然分别需要预定义的2D和3D关键点,这会导致关键点选择规则不一致导致匹配结果不佳。
5.2.3 基于场景坐标回归的定位
与在计算姿势之前建立2D-3D对应关系的基于匹配的方法不同,场景坐标回归方法从世界坐标系中的查询图像估计每个像素的3D坐标,即场景坐标。它可以被视为学习从查询图像到场景全局坐标的转换。DSAC[190]利用ConvNet模型回归场景坐标,然后使用新颖的可微分RANSAC来允许对整个管道进行端到端训练。然后通过引入重投影损失[191]、[192]、[232]或多视图几何约束[197]来改进这种通用管道,以实现无监督学习,联合学习观察置信度[173]、[195]为了提高采样效率和准确性,利用专家混合(MoE)策略[194]或分层粗到细[198]来消除环境歧义。与这些不同,KFNet[199]将场景坐标回归问题扩展到时域,从而弥补了时间和一次性重定位方法之间现有的性能差距。但是,它们仍然针对特定场景进行训练,并且如果不重新训练就无法推广到看不见的场景。为了构建与场景无关的方法,SANet[196]通过插值与检索到的场景图像相关联的3D点来回归查询的场景坐标图。与上述以基于补丁的方式训练的方法不同,Dense SCR[193]建议以全帧方式执行场景坐标回归,以提高测试时的计算效率,更重要的是,为回归添加更多全局上下文提高鲁棒性的过程。
[190] E. Brachmann, A. Krull, S. Nowozin, J. Shotton, F. Michel, S. Gumhold, and C. Rother, “Dsac-differentiable ransac for camera localization,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 6684–6692, 2017.
[191] E. Brachmann and C. Rother, “Learning less is more-6d camera localization via 3d surface regression,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4654– 4662, 2018.
[192] X. Li, J. Ylioinas, J. Verbeek, and J. Kannala, “Scene coordinate regression with angle-based reprojection loss for camera relocalization,” in Proceedings of the European Conference on Computer Vision (ECCV), pp. 0–0, 2018.
[193] X. Li, J. Ylioinas, and J. Kannala, “Full-frame scene coordinate regression for image-based localization,” arXiv preprint arXiv:1802.03237, 2018.
[194] E. Brachmann and C. Rother, “Expert sample consensus applied to camera re-localization,” in Proceedings of the IEEE International Conference on Computer Vision, pp. 7525–7534, 2019.
[195] E. Brachmann and C. Rother, “Neural-guided ransac: Learning where to sample model hypotheses,” in Proceedings of the IEEE International Conference on Computer Vision, pp. 4322–4331, 2019.
[196] L. Yang, Z. Bai, C. Tang, H. Li, Y. Furukawa, and P. Tan, “Sanet: Scene agnostic network for camera localization,” in Proceedings of the IEEE International Conference on Computer Vision (ICCV), pp. 42–51, 2019.
[197] M. Cai, H. Zhan, C. Saroj Weerasekera, K. Li, and I. Reid, “Camera relocalization by exploiting multi-view constraints for scene coordinates regression,” in Proceedings of the IEEE International Conference on Computer Vision Workshops, pp. 0–0, 2019.
[198] X. Li, S. Wang, Y. Zhao, J. Verbeek, and J. Kannala, “Hierarchical scene coordinate classification and regression for visual localization,” in CVPR, 2020.
[199] L. Zhou, Z. Luo, T. Shen, J. Zhang, M. Zhen, Y. Yao, T. Fang, and L. Quan, “Kfnet: Learning temporal camera relocalization using kalman filtering,” arXiv preprint arXiv:2003.10629, 2020.
[232] E. Brachmann and C. Rother, “Visual camera re-localization from rgb and rgb-d images using dsac,” arXiv preprint arXiv:2002.12324, 2020.
场景坐标回归方法通常在小型室内场景下表现出更好的鲁棒性和更高的准确性,优于传统算法,如[18]。但他们还没有在大规模场景中证明自己的能力。
5.3 3D到3D定位
3D到3D定位(或LIDAR定位)是指通过建立3D到3D对应匹配来针对预先构建的3D地图恢复3D点的全局位姿(即LIDAR点云扫描)的方法。图10显示了3D到3D定位的流程:在线扫描或预测粗略姿态用于查询最相似的3D地图数据,通过计算预测姿态与地面实况之间的偏移量或估计在线扫描和查询场景之间的相对位姿。

通过将LIDAR定位公式化为递归贝叶斯推理问题,[227]将LIDAR强度图和在线点云扫描嵌入到共享空间中,以实现完全可微分的姿态估计。LocNet[225]不是直接对3D数据进行操作,而是将点云扫描转换为2D旋转不变表示以在全局先验图中搜索相似帧,然后执行迭代最近点(ICP)方法来计算全局位姿。为了提出一个直接处理点云的基于学习的LIDAR定位框架,L3-Net【224】使用PointNet[125]处理点云数据,以提取编码某些有用属性的特征描述符,并通过循环模型对运动动力学的时间连接进行建模神经网络。它通过最小化点云输入和3D地图之间的匹配距离来优化预测姿势和地面真实值之间的损失。一些技术,如Point-NetVLAD[226]、PCAN[228]和D3Feat[231]探索在开始时检索参考场景,而其他技术如DeepICP【229】和DCP【230】允许估计相对运动3D扫描的转换。与包括2D到3D和2D到2D定位在内的基于图像的重定位相比,3D到3D定位的探索相对较少。

6 SLAM
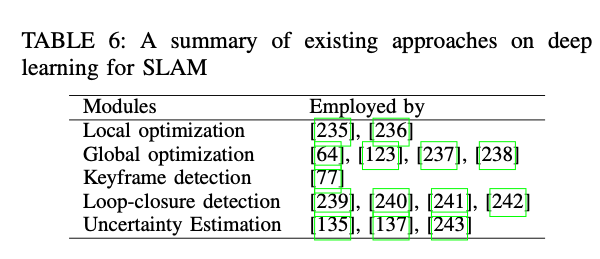
同时跟踪自身运动并估计周围环境的结构,构建了一个同时定位和建图(SLAM)系统。上述部分中讨论的定位和建图的各个模块可以看作是完整的SLAM系统的模块。本节概述了使用深度学习的SLAM系统,主要关注有助于集成SLAM系统的模块,包括局部/全局优化、关键帧/回环检测和不确定性估计。表6总结了使用本节讨论的基于深度学习的SLAM模块的现有方法。
6.1 局部优化
当联合优化估计的相机运动和场景几何时,SLAM系统强制它们满足一定的约束。这是通过最小化几何或光度损失来完成的,以确保它们在局部区域的一致性-相机姿势的周围环境,这可以被视为捆绑调整(BA)问题[233]。基于学习的方法通过在大型数据集上训练的两个单独的网络[29]预测深度图和自我运动。在在线部署的测试过程中,需要强制执行预测以满足局部约束。为了实现局部优化,传统上,二阶求解器,例如Gauss-Newton(GN)方法或Levenberg-Marquadt(LM)算法[234],用于优化运动变换和每像素深度图。
为此,LS-Net[235]通过将分析求解器集成到其学习过程中,通过基于学习的优化器解决了这个问题。它学习数据驱动的先验,然后使用分析优化器改进DNN预测以确保光度一致性。BA-Net[236]将可微二阶优化器(LM算法)集成到深度神经网络中,以实现端到端学习。BA-Net不是最小化几何或光度误差,而是在特征空间上执行以优化ConvNets提取的多视图图像中特征的一致性损失。这种特征级优化器可以缓解几何或光度解决方案的基本问题,即几何优化中可能会丢失一些信息,而环境动态和光照变化可能会影响光度优化。这些基于学习的优化器提供了解决捆绑调整问题的替代方案。
[235] R. Clark, M. Bloesch, J. Czarnowski, S. Leutenegger, and A. J. Davison, “Learning to solve nonlinear least squares for monocular stereo,” in Proceedings of the European Conference on Computer Vision (ECCV), pp. 284–299, 2018.
[236] C. Tang and P. Tan, “Ba-net: Dense bundle adjustment network,” International Conference on Learning Representations (ICLR), 2019.
6.2 全局优化
由于路径整合(path integration)的基本问题,即系统误差在没有有效限制的情况下累积,里程计估计在长期运行过程中受到累积误差漂移的影响。为了解决这个问题,Graph-SLAM[42]构建了一个拓扑图,将相机姿势或场景特征表示为图节点,这些节点通过边(由传感器测量)连接以约束姿势。这种基于图的公式可以进行优化,以确保图节点和边缘的全局一致性,减轻姿势估计的可能误差和固有的传感器测量噪声。一种流行的全局优化求解器是通过Levenberg-Marquardt(LM)算法。
[42] G. Grisetti, R. Kummerle, C. Stachniss, and W. Burgard, “A tutorial on graph-based slam,” IEEE Intelligent Transportation Systems Magazine, vol. 2, no. 4, pp. 31–43, 2010.
在深度学习时代,深度神经网络擅长提取特征,构建从观察到姿势和场景表示的函数。DNN预测的全局优化对于减少全局轨迹的漂移和支持大规模建图是必要的。与经典SLAM中各种经过充分研究的解决方案相比,全局优化深度预测的探索不足。
现有的工作探索将学习模块组合到不同级别的经典SLAM系统中——在前端,DNN产生预测作为先验,然后将这些深度预测合并到后端以进行下一步优化和细化。一个很好的例子是CNN-SLAM【123】,它将学习到的每像素深度用于LSD-SLAM[124],这是一个完整的SLAM系统,以支持闭环和图优化。相机姿势和场景表示与深度图联合优化,以产生一致的尺度指标。在DeepTAM【237】中,来自深度神经网络的深度和姿态预测都被引入经典的DTAM系统[121],由后端进行全局优化,以实现更准确的场景重建和相机运动跟踪。在将无监督VO与图优化后端集成方面可以找到类似的工作[64]。DeepFactors[238]反之亦然,将学习到的可优化场景表示(它们所谓的代码表示)集成到不同风格的后端-用于全局优化的概率因子图。基于因子图的公式的优点是它可以灵活地包括传感器测量、状态估计和约束。在因子图后端中,将新的传感器模态、成对约束和系统状态添加到图中以进行优化是非常容易和方便的。但是,这些后端优化器不可微分的。
[123] K. Tateno, F. Tombari, I. Laina, and N. Navab, “Cnn-slam: Realtime dense monocular slam with learned depth prediction,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 6243–6252, 2017.
[124] J. Engel, T. Schops, and D. Cremers, “Lsd-slam: Large-scale direct monocular slam,” in European conference on computer vision, pp. 834–849, Springer, 2014.
[237] H. Zhou, B. Ummenhofer, and T. Brox, “Deeptam: Deep tracking and mapping with convolutional neural networks,” International Journal of Computer Vision, vol. 128, no. 3, pp. 756–769, 2020.
[238] J. Czarnowski, T. Laidlow, R. Clark, and A. J. Davison, “Deepfactors: Real-time probabilistic dense monocular slam,” IEEE Robotics and Automation Letters, 2020.
6.3 关键帧与回环检测
检测关键帧和闭环对于SLAM系统的后端优化至关重要。
关键帧选择有助于SLAM系统更高效。在基于关键帧的SLAM系统中,姿势和场景估计仅在检测到关键帧时才会被细化。[77]提供了一种学习解决方案来检测关键帧以及自我运动跟踪和深度估计的无监督学习[29]。一个图像是否是关键帧是通过比较它与现有关键帧的特征相似度来确定的(即如果相似度低于一个阈值,这个图像将被视为一个新的关键帧)。
闭环检测或位置识别也是SLAM后端减少开环错误的重要模块。传统作品基于词袋(BoW)来存储和使用来自手工检测器的视觉特征。然而,现实世界场景中光照、天气、视点和移动物体的变化使这个问题变得复杂。为了解决这个问题,以前的研究人员(例如[239])建议改用ConvNet特征,这些特征来自通用大规模图像处理数据集上的预训练模型。由于深度神经网络提取的高级表示,这些方法对视点和条件的变化更加稳健。其他代表性作品[240]、[241]、[242]建立在深度自动编码器结构上,以提取紧凑的表示,以无监督的方式压缩场景。基于深度学习的闭环有助于更强大和有效的视觉特征,并实现最先进的位置识别性能,适合集成到SLAM系统中。
6.4 不确定性估计
安全性和可解释性是对移动代理的在日常生活中的实际部署的关键步骤:前者可让客户的生活和人的动作可靠,而后者则可以让用户有更好的理解在模型的行为。虽然深学习模式实现了广泛的回归和分类任务的最先进的性能,一些角落情况下,应给予足够的重视,以及。在这些失败的案例,从一个组件的错误会传播到其他下游模块,从而导致灾难性的后果。为此,有一个新兴的需要来估算深层神经网络的不确确定性,以确保安全和提供解释性。
深学习模型通常只产生预测的平均值,例如,一个基于DNN-视觉里程计模型的输出是一个6维相对姿势向量,即,平移和旋转。为了捕捉深模型的不确定性,学习模型可以扩充到贝叶斯模型[244],[245]。从贝叶斯模型的不确定性大致分为肆意的不确定性和主观因素:肆意的不确定性反映观测噪声,例如传感器或运动噪声;主观因素捕获的模型不确定性[245]。在本次调查的背景下,我们专注于定位和建图的具体任务估计的不确定性,关于他们的用途,即他们是否捕捉运动跟踪或场景理解的目的,不确定性的工作。
[243]、[246]探索了基于DNN的里程计估计的不确定性。他们采用一种通用策略将目标预测转换为高斯分布,以姿态估计的平均值及其协方差为条件。框架内的参数通过结合均值和协方差的损失函数进行优化。通过最小化误差函数以找到最佳组合,以无监督方式自动学习不确定性。这样就恢复了运动变换的不确定性。运动不确定性在概率传感器融合或SLAM系统的后端优化中起着至关重要的作用。为了验证SLAM系统中不确定性估计的有效性,[243]将学习到的不确定性集成到图SLAM中,作为里程计边的协方差。然后基于这些协方差执行全局优化以减少系统漂移。它还证实了不确定性估计在具有固定预定义协方差值的基线上提高了SLAM系统的性能。类似的贝叶斯模型应用于全局重定位问题。如[135]、[137]中所示,来自深度模型的不确定性能够反映全局位置误差,其中通过这种置信度度量避免了不可靠的姿态估计。
除了运动/重定位的不确定性之外,估计场景理解的不确定性也有助于SLAM系统。这种不确定性提供了一个置信度量,即环境感知和场景结构应该在多大程度上被信任。例如,在语义分割和深度估计任务中,不确定性估计为DNN预测提供了每像素的不确定性[245]、[247]、[248]、[249]。此外,场景不确定性适用于构建混合SLAM系统。例如,可以学习光度不确定性来捕获每个图像像素上的强度变化,从而增强SLAM系统对观测噪声的鲁棒性[25]。
7 开放问题
尽管深度学习在定位和建图研究方面取得了巨大成功,但如前所述,现有模型还不够成熟,无法完全解决手头的问题。当前的深度解决方案形式仍处于起步阶段。为了在恶劣条件下实现高度自治,未来的研究人员面临着许多挑战。这些技术的实际应用应被视为一个系统的研究问题。我们讨论了几个可能导致该领域进一步发展的开放性问题。
1) 端到端模型与混合模型。端到端学习模型能够直接从原始数据预测自我运动和场景,无需任何手工工程。受益于深度学习的进步,端到端模型正在快速发展,以在准确性、效率和鲁棒性方面实现更高的性能。同时,这些模型已被证明更容易与其他高级学习任务集成,例如路径规划和导航[31]。从根本上说,存在底层物理或几何模型来管理定位和建图系统。我们是否应该仅依靠数据驱动方法的力量开发端到端模型,或者将深度学习模块作为混合模型集成到预先构建的物理/几何模型中,是未来研究的关键问题。正如我们所看到的,混合模型已经在许多任务中取得了最先进的结果,例如视觉里程计[25]和全局定位[191]。因此,研究如何更好地利用来自深度学习的先验经验知识用于混合模型是合理的。另一方面,纯粹的端到端模型是数据饥渴。当前模型的性能可能会受到训练数据集大小的限制,因此必须创建大而多样的数据集以扩大数据驱动模型的容量。
2)统一评估基准和指标。查找合适的评估基准和度量始终是SLAM系统的担忧。尤其是基于DNN的系统的情况。来自DNN的预测受培训和测试数据的特征的影响,包括数据集大小,超参数(批量大小和学习率等),以及测试方案的差异。因此,在每个工作中采用的数据集差异,培训/测试配置或评估度量时,难以将它们进行比较。例如,Kitti DataSet是评估视觉测量仪的常见选择,但以前的工作分开培训和测试数据以不同的方式(例如[24],[48],[50]使用的序列00,02,08,09作为训练设置和序列03,04,05,06,07,10作为测试集,而[25],[30]使用序列00 - 08作为训练,左09和10作为测试集)。其中一些甚至基于不同的评估度量(例如[24],[48],[50]应用Kitti官方评估度量,而[29],[56]应用绝对轨迹误差(ATE)作为其评估度量)。所有这些因素都会带来直接和公平比较的困难。此外,KITTI数据集相对简单(车辆仅在2D翻译中移动)和小尺寸。如果没有在长期现实世界实验中没有得到基准基准的结果,则不得令人信服。实际上,在为各种环境,自我运动和动态覆盖各种环境评估的虽然系统评估,但越来越需要越来越需要。
3)现实世界部署。在现实世界环境中部署深度学习模型是一个系统的研究问题。在现有的研究中,预测精度始终是它们的“黄金法则”,而其他至关重要的问题被忽视,例如模型结构和框架的参数次数是最佳的。必须在资源受限的系统上进行计算和能耗,例如低成本机器人或VR可穿戴设备。应利用不妥的机会,例如卷积滤波器或其他并行神经网络模块,以便更好地使用GPU。考虑的示例包括哪种情况应该返回到微调系统,如何将自我监督模型纳入系统以及系统是否允许实时在线学习。
4)终身学习。我们讨论了到目前为止只得到验证的简单多数以前的作品封闭形式的数据集,如视觉里程和深度的预测是在KITTI数据集进行。然而,在一个开放的世界,移动代理将面临变幻无穷的环境因素和移动动态。这将要求DNN模型不断连贯地学习和适应世界的变化。此外,新的概念和对象会出现意外,需要对机器人对象发现和新知识的推广阶段。
5)新的传感器:除了板载传感器,例如摄像机,IMU和LIDAR的共同选择,正在出现的新的传感器提供替代的构造更加精确和鲁棒多模态系统。新的传感器包括事件相机[250],热照相机[251],毫米波装置[252],无线电信号[253],磁传感器[254],具有不同的属性和数据格式相比主要SLAM传感器,例如摄像机,IMU和LIDAR。尽管如此,有效的学习方法来处理这些不寻常的传感器仍然勘探不足。
6)可扩展性。无论是基于学习的定位和建图模型现在已经实现了较好的评估基准测试结果。然而,他们被限制在某些情况下。例如,测距估计总是在城市区域或道路上。是否这些技术可以被应用到其它环境中,例如农村地区或森林面积仍然是一个悬而未决的问题。此外,场景重建局限在单个目标,合成的数据或房间类似的。这是值得探讨这些学习方法是否能够缩放到更复杂和大型重建的问题上。
7)安全性,可靠性和可解释性。安全性和可靠性对实际应用至关重要,例如,自驾驶车辆。在这些场景中,即使是姿势或场景估计的小错误也会导致整个系统造成灾难。深度神经网络已经长期以来为“黑匣子”,加剧了关键任务的安全问题。一些初步努力探讨了深度模型的可解释性[255]。例如,不确定性估计[244],[245]可以提供置信度量,代表我们信任模型的程度。以这种方式,避免了不可靠的预测(以低不确定性)以确保系统保持安全可靠。
8 结论
这项工作全面概述基于深度学习的定位与建图领域,并提供了一个新的分类覆盖机器人技术,计算机视觉和机器学习。学习模型被结合到定位和建图系统连接的输入的传感器数据值和目标值,通过自动提取的原始数据有用的特征。基于深学习技术迄今已取得了最先进的性能在各种不同的任务,从视觉里程计,全局定位到稠密场景重建。由于深层神经网络的高度表现能力,这些模型能够模拟隐含的因素,如环境的动态或传感器的噪声,是很难用手工进行建模,从而在现实世界的应用相对更稳健。此外,高层次理解和互动很容易被以学习为基础的框架移动代理执行。深度学习的快速发展,以数据驱动的方式解决传统的定位和建图问题的替代,同时铺平了基于新一代AI空间感知解决方案的道路。
9 some thing to say




图如侵权,删之~~
参考文献
- Google翻译-图库
- Chen, C.; Wang, B.; Lu, C.X.; Trigoni, N.; Markham, A. A Survey on Deep Learning for Localization and Mapping: Towards the Age of Spatial Machine Intelligence. arXiv 2020, arXiv:2006.12567
[1] C. R. Fetsch, A. H. Turner, G. C. DeAngelis, and D. E. Angelaki, “Dynamic Reweighting of Visual and Vestibular Cues during Self-Motion Perception,” Journal of Neuroscience, vol. 29, no. 49, pp. 15601–15612, 2009.
[2] K. E. Cullen, “The Vestibular System: Multimodal Integration and Encoding of Self-motion for Motor Control,” Trends in Neurosciences, vol. 35, no. 3, pp. 185–196, 2012.
[3] N. Sunderhauf, O. Brock, W. Scheirer, R. Hadsell, D. Fox, J. Leitner, ¨ B. Upcroft, P. Abbeel, W. Burgard, M. Milford, and P. Corke, “The Limits and Potentials of Deep Learning for Robotics,” International Journal of Robotics Research, vol. 37, no. 4-5, pp. 405–420, 2018.
[4] R. Harle, “A Survey of Indoor Inertial Positioning Systems for Pedestrians,” IEEE Communications Surveys and Tutorials, vol. 15, no. 3, pp. 1281–1293, 2013.
[5] M. Gowda, A. Dhekne, S. Shen, R. R. Choudhury, X. Yang, L. Yang, S. Golwalkar, and A. Essanian, “Bringing IoT to Sports Analytics,” in USENIX Symposium on Networked Systems Design and Implementation (NSDI), 2017.
[6] M. Wijers, A. Loveridge, D. W. Macdonald, and A. Markham, “Caracal: a versatile passive acoustic monitoring tool for wildlife research and conservation,” Bioacoustics, pp. 1–17, 2019.
[7] A. Dhekne, A. Chakraborty, K. Sundaresan, and S. Rangarajan, “TrackIO : Tracking First Responders Inside-Out,” in USENIX Symposium on Networked Systems Design and Implementation (NSDI), 2019.
[8] A. J. Davison, “FutureMapping: The Computational Structure of Spatial AI Systems,” arXiv, 2018.
[9] D. Nister, O. Naroditsky, and J. Bergen, “Visual odometry,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), vol. 1, pp. I–652–I–659 Vol.1, 2004.
[10] J. Engel, J. Sturm, and D. Cremers, “Semi-Dense Visual Odometry for a Monocular Camera,” in IEEE International Conference on Computer Vision (ICCV), pp. 1449–1456, 2013.
[11] C. Forster, M. Pizzoli, and D. Scaramuzza, “SVO: Fast Semi-Direct Monocular Visual Odometry,” in IEEE International Conference on Robotics and Automation (ICRA), pp. 15–22, 2014.
[12] M. Li and A. I. Mourikis, “High-precision, Consistent EKF-based Visual-Inertial Odometry,” The International Journal of Robotics Research, vol. 32, no. 6, pp. 690–711, 2013.
[13] S. Leutenegger, S. Lynen, M. Bosse, R. Siegwart, and P. Furgale, “Keyframe-Based VisualInertial Odometry Using Nonlinear Optimization,” The International Journal of Robotics Research, vol. 34, no. 3, pp. 314–334, 2015.
[14] C. Forster, L. Carlone, F. Dellaert, and D. Scaramuzza, “OnManifold Preintegration for Real-Time Visual-Inertial Odometry,” IEEE Transactions on Robotics, vol. 33, no. 1, pp. 1–21, 2017.
[15] T. Qin, P. Li, and S. Shen, “VINS-Mono: A Robust and Versatile Monocular Visual-Inertial State Estimator,” IEEE Transactions on Robotics, vol. 34, no. 4, pp. 1004–1020, 2018.
[16] J. Zhang and S. Singh, “LOAM: Lidar Odometry and Mapping in Real-time,” in Robotics: Science and Systems, 2010.
[17] W. Zhang and J. Kosecka, “Image based localization in urban environments.,” in International Symposium on 3D Data Processing Visualization and Transmission (3DPVT), vol. 6, pp. 33–40, Citeseer, 2006.
[18] T. Sattler, B. Leibe, and L. Kobbelt, “Fast image-based localization using direct 2d-to-3d matching,” in International Conference on Computer Vision (ICCV), pp. 667–674, IEEE, 2011.
[19] S. Lowry, N. Sunderhauf, P. Newman, J. J. Leonard, D. Cox, ¨ P. Corke, and M. J. Milford, “Visual place recognition: A survey,” IEEE Transactions on Robotics, vol. 32, no. 1, pp. 1–19, 2015.
[20] A. J. Davison, I. D. Reid, N. D. Molton, and O. Stasse, “MonoSLAM: Real-Time Single Camera SLAM,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 29, no. 6, pp. 1052–1067, 2007.
[21] R. Mur-Artal, J. Montiel, and J. D. Tardos, “ORB-SLAM : A Versatile and Accurate Monocular SLAM System,” IEEE Transactions on Robotics, vol. 31, no. 5, pp. 1147–1163, 2015.
[22] H. C. Longuet-Higgins, “A computer algorithm for reconstructing a scene from two projections,” Nature, vol. 293, no. 5828, pp. 133– 135, 1981.
[23] C. Wu, “Towards linear-time incremental structure from motion,” in 2013 International Conference on 3D Vision-3DV 2013, pp. 127– 134, IEEE, 2013.
[24] S. Wang, R. Clark, H. Wen, and N. Trigoni, “DeepVO : Towards End-to-End Visual Odometry with Deep Recurrent Convolutional Neural Networks,” in International Conference on Robotics and Automation (ICRA), 2017.
[25] N. Yang, L. von Stumberg, R. Wang, and D. Cremers, “D3vo: Deep depth, deep pose and deep uncertainty for monocular visual odometry,” CVPR, 2020.
[26] J. McCormac, A. Handa, A. Davison, and S. Leutenegger, “Semanticfusion: Dense 3d semantic mapping with convolutional neural networks,” in 2017 IEEE International Conference on Robotics and automation (ICRA), pp. 4628–4635, IEEE, 2017.
[27] L. Ma, J. Stuckler, C. Kerl, and D. Cremers, “Multi-view deep ¨ learning for consistent semantic mapping with rgb-d cameras,” in 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 598–605, IEEE, 2017.
[28] I. Goodfellow, Y. Bengio, and A. Courville, Deep learning. MIT press, 2016.
[29] T. Zhou, M. Brown, N. Snavely, and D. G. Lowe, “Unsupervised Learning of Depth and Ego-Motion from Video,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
[30] J. Bian, Z. Li, N. Wang, H. Zhan, C. Shen, M.-M. Cheng, and I. Reid, “Unsupervised scale-consistent depth and ego-motion learning from monocular video,” in Advances in Neural Information Processing Systems, pp. 35–45, 2019.
[31] Y. Zhu, R. Mottaghi, E. Kolve, J. J. Lim, A. Gupta, L. Fei-Fei, and A. Farhadi, “Target-driven visual navigation in indoor scenes using deep reinforcement learning,” in 2017 IEEE international conference on robotics and automation (ICRA), pp. 3357–3364, IEEE, 2017.
[32] P. Mirowski, M. Grimes, M. Malinowski, K. M. Hermann, K. Anderson, D. Teplyashin, K. Simonyan, A. Zisserman, R. Hadsell, et al., “Learning to navigate in cities without a map,” in Advances in Neural Information Processing Systems, pp. 2419–2430, 2018.
[33] T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, et al., “Language models are few-shot learners,” arXiv preprint arXiv:2005.14165, 2020.
[34] W. Maddern, G. Pascoe, C. Linegar, and P. Newman, “1 Year, 1000km: The Oxford RobotCar Dataset,” The International Journal of Robotics Research, vol. 36, no. 1, pp. 3–15, 2016.
[35] P. Wang, X. Huang, X. Cheng, D. Zhou, Q. Geng, and R. Yang, “The apolloscape open dataset for autonomous driving and its application,” IEEE transactions on pattern analysis and machine intelligence, 2019.
[36] P. Sun, H. Kretzschmar, X. Dotiwalla, A. Chouard, V. Patnaik, P. Tsui, J. Guo, Y. Zhou, Y. Chai, B. Caine, V. Vasudevan, W. Han, J. Ngiam, H. Zhao, A. Timofeev, S. Ettinger, M. Krivokon, A. Gao, A. Joshi, Y. Zhang, J. Shlens, Z. Chen, and D. Anguelov, “Scalability in perception for autonomous driving: Waymo open dataset,” 2019.
[37] H. Durrant-Whyte and T. Bailey, “Simultaneous localization and mapping: part i,” IEEE robotics & automation magazine, vol. 13, no. 2, pp. 99–110, 2006.
[38] T. Bailey and H. Durrant-Whyte, “Simultaneous localization and mapping (slam): Part ii,” IEEE robotics & automation magazine, vol. 13, no. 3, pp. 108–117, 2006.
[39] C. Cadena, L. Carlone, H. Carrillo, Y. Latif, D. Scaramuzza, J. Neira, I. Reid, and J. J. Leonard, “Past, present, and future of simultaneous localization and mapping: Toward the robust-perception age,” IEEE Transactions on robotics, vol. 32, no. 6, pp. 1309–1332, 2016.
[40] S. Thrun, W. Burgard, and D. Fox, Probabilistic robotics. MIT press, 2005.
[41] D. Scaramuzza and F. Fraundorfer, “Visual odometry
[tutorial],” IEEE robotics & automation magazine, vol. 18, no. 4, pp. 80–92, 2011.
[42] G. Grisetti, R. Kummerle, C. Stachniss, and W. Burgard, “A tutorial on graph-based slam,” IEEE Intelligent Transportation Systems Magazine, vol. 2, no. 4, pp. 31–43, 2010.
[43] M. R. U. Saputra, A. Markham, and N. Trigoni, “Visual slam and structure from motion in dynamic environments: A survey,” ACM Computing Surveys (CSUR), vol. 51, no. 2, pp. 1–36, 2018.
[44] K. Konda and R. Memisevic, “Learning Visual Odometry with a Convolutional Network,” in International Conference on Computer Vision Theory and Applications, pp. 486–490, 2015.
[45] G. Costante, M. Mancini, P. Valigi, and T. A. Ciarfuglia, “Exploring representation learning with cnns for frame-to-frame ego-motion estimation,” IEEE robotics and automation letters, vol. 1, no. 1, pp. 18–25, 2015.
[46] A. Geiger, P. Lenz, C. Stiller, and R. Urtasun, “Vision meets robotics: The KITTI dataset,” The International Journal of Robotics Research, vol. 32, no. 11, pp. 1231–1237, 2013.
[47] A. Geiger, J. Ziegler, and C. Stiller, “Stereoscan: Dense 3d reconstruction in real-time,” in 2011 IEEE Intelligent Vehicles Symposium (IV), pp. 963–968, Ieee, 2011.
[48] M. R. U. Saputra, P. P. de Gusmao, S. Wang, A. Markham, and N. Trigoni, “Learning monocular visual odometry through geometryaware curriculum learning,” in 2019 International Conference on Robotics and Automation (ICRA), pp. 3549–3555, IEEE, 2019.
[49] M. R. U. Saputra, P. P. de Gusmao, Y. Almalioglu, A. Markham, and N. Trigoni, “Distilling knowledge from a deep pose regressor network,” in Proceedings of the IEEE International Conference on Computer Vision (ICCV), pp. 263–272, 2019.
[50] F. Xue, X. Wang, S. Li, Q. Wang, J. Wang, and H. Zha, “Beyond tracking: Selecting memory and refining poses for deep visual odometry,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 8575–8583, 2019.
[51] T. Haarnoja, A. Ajay, S. Levine, and P. Abbeel, “Backprop kf: Learning discriminative deterministic state estimators,” in Advances in Neural Information Processing Systems, pp. 4376–4384, 2016.
[52] X. Yin, X. Wang, X. Du, and Q. Chen, “Scale recovery for monocular visual odometry using depth estimated with deep convolutional neural fields,” in Proceedings of the IEEE International Conference on Computer Vision, pp. 5870–5878, 2017.
[53] R. Li, S. Wang, Z. Long, and D. Gu, “Undeepvo: Monocular visual odometry through unsupervised deep learning,” in 2018 IEEE international conference on robotics and automation (ICRA), pp. 7286– 7291, IEEE, 2018.
[54] D. Barnes, W. Maddern, G. Pascoe, and I. Posner, “Driven to distraction: Self-supervised distractor learning for robust monocular visual odometry in urban environments,” in 2018 IEEE International Conference on Robotics and Automation (ICRA), pp. 1894–1900, IEEE, 2018.
[55] Z. Yin and J. Shi, “GeoNet: Unsupervised Learning of Dense Depth, Optical Flow and Camera Pose,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
[56] H. Zhan, R. Garg, C. S. Weerasekera, K. Li, H. Agarwal, and I. Reid, “Unsupervised Learning of Monocular Depth Estimation and Visual Odometry with Deep Feature Reconstruction,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 340–349, 2018.
[57] R. Jonschkowski, D. Rastogi, and O. Brock, “Differentiable particle filters: End-to-end learning with algorithmic priors,” Robotics: Science and Systems, 2018.
[58] N. Yang, R. Wang, J. Stuckler, and D. Cremers, “Deep virtual stereo odometry: Leveraging deep depth prediction for monocular direct sparse odometry,” in Proceedings of the European Conference on Computer Vision (ECCV), pp. 817–833, 2018.
[59] C. Zhao, L. Sun, P. Purkait, T. Duckett, and R. Stolkin, “Learning monocular visual odometry with dense 3d mapping from dense 3d flow,” in 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 6864–6871, IEEE, 2018.
[60] V. Casser, S. Pirk, R. Mahjourian, and A. Angelova, “Depth prediction without the sensors: Leveraging structure for unsupervised learning from monocular videos,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 33, pp. 8001–8008, 2019.
[61] Y. Almalioglu, M. R. U. Saputra, P. P. de Gusmao, A. Markham, and N. Trigoni, “Ganvo: Unsupervised deep monocular visual odometry and depth estimation with generative adversarial networks,” in 2019 International Conference on Robotics and Automation (ICRA), pp. 5474–5480, IEEE, 2019.
[62] S. Y. Loo, A. J. Amiri, S. Mashohor, S. H. Tang, and H. Zhang, “Cnn-svo: Improving the mapping in semi-direct visual odometry using single-image depth prediction,” in 2019 International Conference on Robotics and Automation (ICRA), pp. 5218–5223, IEEE, 2019.
[63] R. Wang, S. M. Pizer, and J.-M. Frahm, “Recurrent neural network for (un-) supervised learning of monocular video visual odometry and depth,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 5555–5564, 2019.
[64] Y. Li, Y. Ushiku, and T. Harada, “Pose graph optimization for unsupervised monocular visual odometry,” in 2019 International Conference on Robotics and Automation (ICRA), pp. 5439–5445, IEEE, 2019.
[65] A. Gordon, H. Li, R. Jonschkowski, and A. Angelova, “Depth from videos in the wild: Unsupervised monocular depth learning from unknown cameras,” in Proceedings of the IEEE International Conference on Computer Vision, pp. 8977–8986, 2019.
[66] A. S. Koumis, J. A. Preiss, and G. S. Sukhatme, “Estimating metric scale visual odometry from videos using 3d convolutional networks,” in 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 265–272, IEEE, 2019.
[67] H. Zhan, C. S. Weerasekera, J. Bian, and I. Reid, “Visual odometry revisited: What should be learnt?,” The International Conference on Robotics and Automation (ICRA), 2020.
[68] R. Clark, S. Wang, H. Wen, A. Markham, and N. Trigoni, “VINet : Visual-Inertial Odometry as a Sequence-to-Sequence Learning Problem,” in The AAAI Conference on Artificial Intelligence (AAAI), pp. 3995–4001, 2017.
[69] E. J. Shamwell, K. Lindgren, S. Leung, and W. D. Nothwang, “Unsupervised deep visual-inertial odometry with online error correction for rgb-d imagery,” IEEE transactions on pattern analysis and machine intelligence, 2019.
[70] C. Chen, S. Rosa, Y. Miao, C. X. Lu, W. Wu, A. Markham, and N. Trigoni, “Selective sensor fusion for neural visual-inertial odometry,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 10542–10551, 2019.
[71] L. Han, Y. Lin, G. Du, and S. Lian, “Deepvio: Self-supervised deep learning of monocular visual inertial odometry using 3d geometric constraints,” arXiv preprint arXiv:1906.11435, 2019.
[72] M. Velas, M. Spanel, M. Hradis, and A. Herout, “Cnn for imu assisted odometry estimation using velodyne lidar,” in 2018 IEEE International Conference on Autonomous Robot Systems and Competitions (ICARSC), pp. 71–77, IEEE, 2018.
[73] Q. Li, S. Chen, C. Wang, X. Li, C. Wen, M. Cheng, and J. Li, “Lonet: Deep real-time lidar odometry,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 8473–8482, 2019.
[74] W. Wang, M. R. U. Saputra, P. Zhao, P. Gusmao, B. Yang, C. Chen, A. Markham, and N. Trigoni, “Deeppco: End-to-end point cloud odometry through deep parallel neural network,” The 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2019), 2019.
[75] M. Valente, C. Joly, and A. de La Fortelle, “Deep sensor fusion for real-time odometry estimation,” 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2019.
[76] S. Li, F. Xue, X. Wang, Z. Yan, and H. Zha, “Sequential adversarial learning for self-supervised deep visual odometry,” in Proceedings of the IEEE International Conference on Computer Vision (ICCV), pp. 2851–2860, 2019.
[77] L. Sheng, D. Xu, W. Ouyang, and X. Wang, “Unsupervised collaborative learning of keyframe detection and visual odometry towards monocular deep slam,” in Proceedings of the IEEE International Conference on Computer Vision (ICCV), pp. 4302–4311, 2019.
[78] D. Eigen, C. Puhrsch, and R. Fergus, “Depth map prediction from a single image using a multi-scale deep network,” in Advances in neural information processing systems, pp. 2366–2374, 2014.
[79] B. Ummenhofer, H. Zhou, J. Uhrig, N. Mayer, E. Ilg, A. Dosovitskiy, and T. Brox, “Demon: Depth and motion network for learning monocular stereo,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 5038–5047, 2017.
[80] R. Garg, V. K. BG, G. Carneiro, and I. Reid, “Unsupervised cnn for single view depth estimation: Geometry to the rescue,” in European Conference on Computer Vision, pp. 740–756, Springer, 2016.
[81] C. Godard, O. Mac Aodha, and G. J. Brostow, “Unsupervised monocular depth estimation with left-right consistency,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 270–279, 2017.
[82] T. Haarnoja, A. Ajay, S. Levine, and P. Abbeel, “Backprop KF: Learning Discriminative Deterministic State Estimators,” in Advances In Neural Information Processing Systems (NeurIPS), 2016.
[83] R. Jonschkowski, D. Rastogi, and O. Brock, “Differentiable Particle Filters: End-to-End Learning with Algorithmic Priors,” in Robotics: Science and Systems, 2018.
[84] L. Von Stumberg, V. Usenko, and D. Cremers, “Direct sparse visual-inertial odometry using dynamic marginalization,” in 2018 IEEE International Conference on Robotics and Automation (ICRA), pp. 2510–2517, IEEE, 2018.
[85] C. Chen, X. Lu, A. Markham, and N. Trigoni, “Ionet: Learning to cure the curse of drift in inertial odometry,” in Thirty-Second AAAI Conference on Artificial Intelligence, 2018.
[86] C. Chen, Y. Miao, C. X. Lu, L. Xie, P. Blunsom, A. Markham, and N. Trigoni, “Motiontransformer: Transferring neural inertial tracking between domains,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 33, pp. 8009–8016, 2019.
[87] M. A. Esfahani, H. Wang, K. Wu, and S. Yuan, “Aboldeepio: A novel deep inertial odometry network for autonomous vehicles,” IEEE Transactions on Intelligent Transportation Systems, 2019.
[88] H. Yan, Q. Shan, and Y. Furukawa, “Ridi: Robust imu double integration,” in Proceedings of the European Conference on Computer Vision (ECCV), pp. 621–636, 2018.
[89] S. Cortes, A. Solin, and J. Kannala, “Deep learning based speed ´ estimation for constraining strapdown inertial navigation on smartphones,” in 2018 IEEE 28th International Workshop on Machine Learning for Signal Processing (MLSP), pp. 1–6, IEEE, 2018.
[90] B. Wagstaff and J. Kelly, “Lstm-based zero-velocity detection for robust inertial navigation,” in 2018 International Conference on Indoor Positioning and Indoor Navigation (IPIN), pp. 1–8, IEEE, 2018.
[91] M. Brossard, A. Barrau, and S. Bonnabel, “Rins-w: Robust inertial navigation system on wheels,” 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2019.
[92] F. Liu, C. Shen, G. Lin, and I. Reid, “Learning depth from single monocular images using deep convolutional neural fields,” IEEE transactions on pattern analysis and machine intelligence, vol. 38, no. 10, pp. 2024–2039, 2015.
[93] C. Wang, J. Miguel Buenaposada, R. Zhu, and S. Lucey, “Learning depth from monocular videos using direct methods,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2022–2030, 2018.
[94] M. Ji, J. Gall, H. Zheng, Y. Liu, and L. Fang, “Surfacenet: An end-toend 3d neural network for multiview stereopsis,” in Proceedings of the IEEE International Conference on Computer Vision, pp. 2307– 2315, 2017.
[95] D. Paschalidou, O. Ulusoy, C. Schmitt, L. Van Gool, and A. Geiger, “Raynet: Learning volumetric 3d reconstruction with ray potentials,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 3897–3906, 2018.
[96] A. Kar, C. Hane, and J. Malik, “Learning a multi-view stereo ¨ machine,” in Advances in neural information processing systems, pp. 365–376, 2017.
[97] M. Tatarchenko, A. Dosovitskiy, and T. Brox, “Octree generating networks: Efficient convolutional architectures for high-resolution 3d outputs,” in Proceedings of the IEEE International Conference on Computer Vision, pp. 2088–2096, 2017.
[98] C. Hane, S. Tulsiani, and J. Malik, “Hierarchical surface prediction ¨ for 3d object reconstruction,” in 2017 International Conference on 3D Vision (3DV), pp. 412–420, IEEE, 2017.
[99] A. Dai, C. Ruizhongtai Qi, and M. Nießner, “Shape completion using 3d-encoder-predictor cnns and shape synthesis,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 5868–5877, 2017.
[100] G. Riegler, A. O. Ulusoy, H. Bischof, and A. Geiger, “Octnetfusion: Learning depth fusion from data,” in 2017 International Conference on 3D Vision (3DV), pp. 57–66, IEEE, 2017.
[101] H. Fan, H. Su, and L. J. Guibas, “A point set generation network for 3d object reconstruction from a single image,” in Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 605–613, 2017.
[102] T. Groueix, M. Fisher, V. G. Kim, B. C. Russell, and M. Aubry, “A papier-mach ˆ e approach to learning 3d surface generation,” in ´ Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 216–224, 2018.
[103] N. Wang, Y. Zhang, Z. Li, Y. Fu, W. Liu, and Y.-G. Jiang, “Pixel2mesh: Generating 3d mesh models from single rgb images,” in Proceedings of the European Conference on Computer Vision (ECCV), pp. 52–67, 2018.
[104] L. Ladicky, O. Saurer, S. Jeong, F. Maninchedda, and M. Pollefeys, “From point clouds to mesh using regression,” in Proceedings of the IEEE International Conference on Computer Vision, pp. 3893–3902, 2017.
[105] A. Dai and M. Nießner, “Scan2mesh: From unstructured range scans to 3d meshes,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 5574–5583, 2019.
[106] T. Mukasa, J. Xu, and B. Stenger, “3d scene mesh from cnn depth predictions and sparse monocular slam,” in Proceedings of the IEEE International Conference on Computer Vision Workshops, pp. 921– 928, 2017.
[107] M. Bloesch, T. Laidlow, R. Clark, S. Leutenegger, and A. J. Davison, “Learning meshes for dense visual slam,” in Proceedings of the IEEE International Conference on Computer Vision, pp. 5855–5864, 2019.
[108] Y. Xiang and D. Fox, “Da-rnn: Semantic mapping with data associated recurrent neural networks,” Robotics: Science and Systems, 2017.
[109] N. Sunderhauf, T. T. Pham, Y. Latif, M. Milford, and I. Reid, ¨ “Meaningful maps with object-oriented semantic mapping,” in 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 5079–5085, IEEE, 2017.
[110] J. McCormac, R. Clark, M. Bloesch, A. Davison, and S. Leutenegger, “Fusion++: Volumetric object-level slam,” in 2018 international conference on 3D vision (3DV), pp. 32–41, IEEE, 2018.
[111] M. Grinvald, F. Furrer, T. Novkovic, J. J. Chung, C. Cadena, R. Siegwart, and J. Nieto, “Volumetric instance-aware semantic mapping and 3d object discovery,” IEEE Robotics and Automation Letters, vol. 4, no. 3, pp. 3037–3044, 2019.
[112] G. Narita, T. Seno, T. Ishikawa, and Y. Kaji, “Panopticfusion: Online volumetric semantic mapping at the level of stuff and things,” IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2019.
[113] M. Bloesch, J. Czarnowski, R. Clark, S. Leutenegger, and A. J. Davison, “CodeSLAM Learning a Compact, Optimisable Representation for Dense Visual SLAM,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
[114] J. Tobin, W. Zaremba, and P. Abbeel, “Geometry-aware neural rendering,” in Advances in Neural Information Processing Systems, pp. 11555–11565, 2019.
[115] J. H. Lim, P. O. Pinheiro, N. Rostamzadeh, C. Pal, and S. Ahn, “Neural multisensory scene inference,” in Advances in Neural Information Processing Systems, pp. 8994–9004, 2019.
[116] V. Sitzmann, M. Zollhofer, and G. Wetzstein, “Scene representa- ¨ tion networks: Continuous 3d-structure-aware neural scene representations,” in Advances in Neural Information Processing Systems, pp. 1119–1130, 2019.
[117] M. Jaderberg, V. Mnih, W. M. Czarnecki, T. Schaul, J. Z. Leibo, D. Silver, and K. Kavukcuoglu, “Reinforcement learning with unsupervised auxiliary tasks,” ICLR, 2017.
[118] P. Mirowski, R. Pascanu, F. Viola, H. Soyer, A. J. Ballard, A. Banino, M. Denil, R. Goroshin, L. Sifre, K. Kavukcuoglu, et al., “Learning to navigate in complex environments,” ICLR, 2017.
[119] C. Kerl, J. Sturm, and D. Cremers, “Dense visual slam for rgb-d cameras,” in 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems, pp. 2100–2106, IEEE, 2013.
[120] T. Whelan, M. Kaess, H. Johannsson, M. Fallon, J. J. Leonard, and J. McDonald, “Real-time large-scale dense rgb-d slam with volumetric fusion,” The International Journal of Robotics Research, vol. 34, no. 4-5, pp. 598–626, 2015.
[121] R. A. Newcombe, S. J. Lovegrove, and A. J. Davison, “DTAM : Dense Tracking and Mapping in Real-Time,” in IEEE International Conference on Computer Vision (ICCV), pp. 2320–2327, 2011.
[122] K. Karsch, C. Liu, and S. B. Kang, “Depth transfer: Depth extraction from video using non-parametric sampling,” IEEE transactions on pattern analysis and machine intelligence, vol. 36, no. 11, pp. 2144– 2158, 2014.
[123] K. Tateno, F. Tombari, I. Laina, and N. Navab, “Cnn-slam: Realtime dense monocular slam with learned depth prediction,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 6243–6252, 2017.
[124] J. Engel, T. Schops, and D. Cremers, “Lsd-slam: Large-scale di- ¨ rect monocular slam,” in European conference on computer vision, pp. 834–849, Springer, 2014.
[125] C. R. Qi, H. Su, K. Mo, and L. J. Guibas, “Pointnet: Deep learning on point sets for 3d classification and segmentation,” in Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 652–660, 2017.
[126] A. Kirillov, K. He, R. Girshick, C. Rother, and P. Dollar, “Panoptic ´ segmentation,” in Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 9404–9413, 2019.
[127] R. A. Newcombe, S. Izadi, O. Hilliges, D. Molyneaux, D. Kim, A. J. Davison, P. Kohi, J. Shotton, S. Hodges, and A. Fitzgibbon, “Kinectfusion: Real-time dense surface mapping and tracking,” in 2011 10th IEEE International Symposium on Mixed and Augmented Reality, pp. 127–136, IEEE, 2011.
[128] S. A. Eslami, D. J. Rezende, F. Besse, F. Viola, A. S. Morcos, M. Garnelo, A. Ruderman, A. A. Rusu, I. Danihelka, K. Gregor, et al., “Neural scene representation and rendering,” Science, vol. 360, no. 6394, pp. 1204–1210, 2018.
[129] V. Balntas, S. Li, and V. Prisacariu, “Relocnet: Continuous metric learning relocalisation using neural nets,” in Proceedings of the European Conference on Computer Vision (ECCV), pp. 751–767, 2018.
[130] A. Kendall, M. Grimes, and R. Cipolla, “Posenet: A convolutional network for real-time 6-dof camera relocalization,” in Proceedings of the IEEE international Conference on Computer Vision (ICCV), pp. 2938–2946, 2015.
[131] Z. Laskar, I. Melekhov, S. Kalia, and J. Kannala, “Camera relocalization by computing pairwise relative poses using convolutional neural network,” in Proceedings of the IEEE International Conference on Computer Vision Workshops, pp. 929–938, 2017.
[132] P. Wang, R. Yang, B. Cao, W. Xu, and Y. Lin, “Dels-3d: Deep localization and segmentation with a 3d semantic map,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 5860–5869, 2018.
[133] S. Saha, G. Varma, and C. Jawahar, “Improved visual relocalization by discovering anchor points,” arXiv preprint arXiv:1811.04370, 2018.
[134] M. Ding, Z. Wang, J. Sun, J. Shi, and P. Luo, “Camnet: Coarse-tofine retrieval for camera re-localization,” in Proceedings of the IEEE International Conference on Computer Vision (ICCV), pp. 2871– 2880, 2019.
[135] A. Kendall and R. Cipolla, “Modelling uncertainty in deep learning for camera relocalization,” in 2016 IEEE international conference on Robotics and Automation (ICRA), pp. 4762–4769, IEEE, 2016.
[136] J. Wu, L. Ma, and X. Hu, “Delving deeper into convolutional neural networks for camera relocalization,” in 2017 IEEE International Conference on Robotics and Automation (ICRA), pp. 5644–5651, IEEE, 2017.
[137] R. Clark, S. Wang, A. Markham, N. Trigoni, and H. Wen, “VidLoc: A Deep Spatio-Temporal Model for 6-DoF Video-Clip Relocalization,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
[138] A. Kendall and R. Cipolla, “Geometric loss functions for camera pose regression with deep learning,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 5974–5983, 2017.
[139] T. Naseer and W. Burgard, “Deep regression for monocular camerabased 6-dof global localization in outdoor environments,” in 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 1525–1530, IEEE, 2017.
[140] F. Walch, C. Hazirbas, L. Leal-Taixe, T. Sattler, S. Hilsenbeck, and D. Cremers, “Image-based localization using lstms for structured feature correlation,” in Proceedings of the IEEE International Conference on Computer Vision (ICCV), pp. 627–637, 2017.
[141] I. Melekhov, J. Ylioinas, J. Kannala, and E. Rahtu, “Image-based localization using hourglass networks,” in Proceedings of the IEEE International Conference on Computer Vision Workshops, pp. 879– 886, 2017.
[142] A. Valada, N. Radwan, and W. Burgard, “Deep auxiliary learning for visual localization and odometry,” in 2018 IEEE international conference on robotics and automation (ICRA), pp. 6939–6946, IEEE, 2018.
[143] S. Brahmbhatt, J. Gu, K. Kim, J. Hays, and J. Kautz, “GeometryAware Learning of Maps for Camera Localization,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 2616–2625, 2018.
[144] P. Purkait, C. Zhao, and C. Zach, “Synthetic view generation for absolute pose regression and image synthesis.,” in BMVC, p. 69, 2018.
[145] M. Cai, C. Shen, and I. D. Reid, “A hybrid probabilistic model for camera relocalization.,” in BMVC, vol. 1, p. 8, 2018.
[146] N. Radwan, A. Valada, and W. Burgard, “Vlocnet++: Deep multitask learning for semantic visual localization and odometry,” IEEE Robotics and Automation Letters, vol. 3, no. 4, pp. 4407–4414, 2018.
[147] F. Xue, X. Wang, Z. Yan, Q. Wang, J. Wang, and H. Zha, “Local supports global: Deep camera relocalization with sequence enhancement,” in Proceedings of the IEEE International Conference on Computer Vision (ICCV), pp. 2841–2850, 2019.
[148] Z. Huang, Y. Xu, J. Shi, X. Zhou, H. Bao, and G. Zhang, “Prior guided dropout for robust visual localization in dynamic environments,” in Proceedings of the IEEE International Conference on Computer Vision (ICCV), pp. 2791–2800, 2019.
[149] M. Bui, C. Baur, N. Navab, S. Ilic, and S. Albarqouni, “Adversarial networks for camera pose regression and refinement,” in Proceedings of the IEEE International Conference on Computer Vision Workshops, pp. 0–0, 2019.
[150] B. Wang, C. Chen, C. X. Lu, P. Zhao, N. Trigoni, and A. Markham, “Atloc: Attention guided camera localization,” arXiv preprint arXiv:1909.03557, 2019.
[151] J. Shotton, B. Glocker, C. Zach, S. Izadi, A. Criminisi, and A. Fitzgibbon, “Scene coordinate regression forests for camera relocalization in rgb-d images,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2930–2937, 2013.
[152] R. Arandjelovic and A. Zisserman, “Dislocation: Scalable descriptor ´ distinctiveness for location recognition,” in Asian Conference on Computer Vision, pp. 188–204, Springer, 2014.
[153] D. M. Chen, G. Baatz, K. Koser, S. S. Tsai, R. Vedantham, ¨ T. Pylvan ¨ ainen, K. Roimela, X. Chen, J. Bach, M. Pollefeys, ¨ et al., “City-scale landmark identification on mobile devices,” in CVPR 2011, pp. 737–744, IEEE, 2011.
[154] A. Torii, R. Arandjelovic, J. Sivic, M. Okutomi, and T. Pajdla, “24/7 place recognition by view synthesis,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1808– 1817, 2015.
[155] Z. Chen, O. Lam, A. Jacobson, and M. Milford, “Convolutional neural network-based place recognition,” arXiv preprint arXiv:1411.1509, 2014.
[156] N. Sunderhauf, S. Shirazi, F. Dayoub, B. Upcroft, and M. Milford, ¨ “On the performance of convnet features for place recognition,” in 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 4297–4304, IEEE, 2015.
[157] R. Arandjelovic, P. Gronat, A. Torii, T. Pajdla, and J. Sivic, “Netvlad: Cnn architecture for weakly supervised place recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 5297–5307, 2016.
[158] Q. Zhou, T. Sattler, M. Pollefeys, and L. Leal-Taixe, “To learn or not to learn: Visual localization from essential matrices,” arXiv preprint arXiv:1908.01293, 2019.
[159] I. Melekhov, A. Tiulpin, T. Sattler, M. Pollefeys, E. Rahtu, and J. Kannala, “Dgc-net: Dense geometric correspondence network,” in 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), pp. 1034–1042, IEEE, 2019.
[160] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich, “Going deeper with convolutions,” in CVPR, 2015.
[161] M. Larsson, E. Stenborg, C. Toft, L. Hammarstrand, T. Sattler, and F. Kahl, “Fine-grained segmentation networks: Self-supervised segmentation for improved long-term visual localization,” in Proceedings of the IEEE International Conference on Computer Vision, pp. 31–41, 2019.
[162] T. Sattler, Q. Zhou, M. Pollefeys, and L. Leal-Taixe, “Understanding the limitations of cnn-based absolute camera pose regression,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 3302–3312, 2019.
[163] Y. Li, N. Snavely, and D. P. Huttenlocher, “Location recognition using prioritized feature matching,” in European conference on computer vision, pp. 791–804, Springer, 2010.
[164] Y. Li, N. Snavely, D. Huttenlocher, and P. Fua, “Worldwide pose estimation using 3d point clouds,” in European conference on computer vision, pp. 15–29, Springer, 2012.
[165] B. Zeisl, T. Sattler, and M. Pollefeys, “Camera pose voting for large-scale image-based localization,” in Proceedings of the IEEE International Conference on Computer Vision, pp. 2704–2712, 2015.
[166] T. Cavallari, S. Golodetz, N. A. Lord, J. Valentin, L. Di Stefano, and P. H. Torr, “On-the-fly adaptation of regression forests for online camera relocalisation,” in Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 4457–4466, 2017.
[167] A. Guzman-Rivera, P. Kohli, B. Glocker, J. Shotton, T. Sharp, A. Fitzgibbon, and S. Izadi, “Multi-output learning for camera relocalization,” in Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 1114–1121, 2014.
[168] D. Massiceti, A. Krull, E. Brachmann, C. Rother, and P. H. Torr, “Random forests versus neural networkswhat’s best for camera localization?,” in 2017 IEEE International Conference on Robotics and Automation (ICRA), pp. 5118–5125, IEEE, 2017.
[169] X.-S. Gao, X.-R. Hou, J. Tang, and H.-F. Cheng, “Complete solution classification for the perspective-three-point problem,” IEEE transactions on pattern analysis and machine intelligence, vol. 25, no. 8, pp. 930–943, 2003.
[170] V. Lepetit, F. Moreno-Noguer, and P. Fua, “Epnp: An accurate o (n) solution to the pnp problem,” International journal of computer vision, vol. 81, no. 2, p. 155, 2009.
[171] M. A. Fischler and R. C. Bolles, “Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography,” Communications of the ACM, vol. 24, no. 6, pp. 381–395, 1981.
[172] P.-E. Sarlin, C. Cadena, R. Siegwart, and M. Dymczyk, “From coarse to fine: Robust hierarchical localization at large scale,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 12716–12725, 2019.
[173] M. Bui, S. Albarqouni, S. Ilic, and N. Navab, “Scene coordinate and correspondence learning for image-based localization,” arXiv preprint arXiv:1805.08443, 2018.
[174] H. Noh, A. Araujo, J. Sim, T. Weyand, and B. Han, “Large-scale image retrieval with attentive deep local features,” in Proceedings of the IEEE international conference on computer vision, pp. 3456– 3465, 2017.
[175] H. Taira, M. Okutomi, T. Sattler, M. Cimpoi, M. Pollefeys, J. Sivic, T. Pajdla, and A. Torii, “Inloc: Indoor visual localization with dense matching and view synthesis,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 7199– 7209, 2018.
[176] J. L. Schonberger, M. Pollefeys, A. Geiger, and T. Sattler, “Semantic ¨ visual localization,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 6896–6906, 2018.
[177] D. DeTone, T. Malisiewicz, and A. Rabinovich, “Superpoint: Selfsupervised interest point detection and description,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, pp. 224–236, 2018.
[178] P.-E. Sarlin, F. Debraine, M. Dymczyk, R. Siegwart, and C. Cadena, “Leveraging deep visual descriptors for hierarchical efficient localization,” arXiv preprint arXiv:1809.01019, 2018.
[179] I. Rocco, M. Cimpoi, R. Arandjelovic, A. Torii, T. Pajdla, and ´ J. Sivic, “Neighbourhood consensus networks,” in Advances in Neural Information Processing Systems, pp. 1651–1662, 2018.
[180] M. Feng, S. Hu, M. H. Ang, and G. H. Lee, “2d3d-matchnet: learning to match keypoints across 2d image and 3d point cloud,” in 2019 International Conference on Robotics and Automation (ICRA), pp. 4790–4796, IEEE, 2019.
[181] P. H. Christiansen, M. F. Kragh, Y. Brodskiy, and H. Karstoft, “Unsuperpoint: End-to-end unsupervised interest point detector and descriptor,” arXiv preprint arXiv:1907.04011, 2019.
[182] M. Dusmanu, I. Rocco, T. Pajdla, M. Pollefeys, J. Sivic, A. Torii, and T. Sattler, “D2-net: A trainable cnn for joint description and detection of local features,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 8092–8101, 2019.
[183] P. Speciale, J. L. Schonberger, S. B. Kang, S. N. Sinha, and M. Pollefeys, “Privacy preserving image-based localization,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 5493–5503, 2019.
[184] P. Weinzaepfel, G. Csurka, Y. Cabon, and M. Humenberger, “Visual localization by learning objects-of-interest dense match regression,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 5634–5643, 2019.
[185] F. Camposeco, A. Cohen, M. Pollefeys, and T. Sattler, “Hybrid scene compression for visual localization,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 7653– 7662, 2019.
[186] W. Cheng, W. Lin, K. Chen, and X. Zhang, “Cascaded parallel filtering for memory-efficient image-based localization,” in Proceedings of the IEEE International Conference on Computer Vision, pp. 1032– 1041, 2019.
[187] H. Taira, I. Rocco, J. Sedlar, M. Okutomi, J. Sivic, T. Pajdla, T. Sattler, and A. Torii, “Is this the right place? geometric-semantic pose verification for indoor visual localization,” in Proceedings of the IEEE International Conference on Computer Vision, pp. 4373– 4383, 2019.
[188] J. Revaud, P. Weinzaepfel, C. De Souza, N. Pion, G. Csurka, Y. Cabon, and M. Humenberger, “R2d2: Repeatable and reliable detector and descriptor,” arXiv preprint arXiv:1906.06195, 2019.
[189] Z. Luo, L. Zhou, X. Bai, H. Chen, J. Zhang, Y. Yao, S. Li, T. Fang, and L. Quan, “Aslfeat: Learning local features of accurate shape and localization,” arXiv preprint arXiv:2003.10071, 2020.
[190] E. Brachmann, A. Krull, S. Nowozin, J. Shotton, F. Michel, S. Gumhold, and C. Rother, “Dsac-differentiable ransac for camera localization,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 6684–6692, 2017.
[191] E. Brachmann and C. Rother, “Learning less is more-6d camera localization via 3d surface regression,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4654– 4662, 2018.
[192] X. Li, J. Ylioinas, J. Verbeek, and J. Kannala, “Scene coordinate regression with angle-based reprojection loss for camera relocalization,” in Proceedings of the European Conference on Computer Vision (ECCV), pp. 0–0, 2018.
[193] X. Li, J. Ylioinas, and J. Kannala, “Full-frame scene coordinate regression for image-based localization,” arXiv preprint arXiv:1802.03237, 2018.
[194] E. Brachmann and C. Rother, “Expert sample consensus applied to camera re-localization,” in Proceedings of the IEEE International Conference on Computer Vision, pp. 7525–7534, 2019.
[195] E. Brachmann and C. Rother, “Neural-guided ransac: Learning where to sample model hypotheses,” in Proceedings of the IEEE International Conference on Computer Vision, pp. 4322–4331, 2019.
[196] L. Yang, Z. Bai, C. Tang, H. Li, Y. Furukawa, and P. Tan, “Sanet: Scene agnostic network for camera localization,” in Proceedings of the IEEE International Conference on Computer Vision (ICCV), pp. 42–51, 2019.
[197] M. Cai, H. Zhan, C. Saroj Weerasekera, K. Li, and I. Reid, “Camera relocalization by exploiting multi-view constraints for scene coordinates regression,” in Proceedings of the IEEE International Conference on Computer Vision Workshops, pp. 0–0, 2019.
[198] X. Li, S. Wang, Y. Zhao, J. Verbeek, and J. Kannala, “Hierarchical scene coordinate classification and regression for visual localization,” in CVPR, 2020.
[199] L. Zhou, Z. Luo, T. Shen, J. Zhang, M. Zhen, Y. Yao, T. Fang, and L. Quan, “Kfnet: Learning temporal camera relocalization using kalman filtering,” arXiv preprint arXiv:2003.10629, 2020.
[200] K. Mikolajczyk and C. Schmid, “Scale & affine invariant interest point detectors,” International journal of computer vision, vol. 60, no. 1, pp. 63–86, 2004.
[201] S. Leutenegger, M. Chli, and R. Y. Siegwart, “Brisk: Binary robust invariant scalable keypoints,” in 2011 International conference on computer vision, pp. 2548–2555, Ieee, 2011.
[202] H. Bay, T. Tuytelaars, and L. Van Gool, “Surf: Speeded up robust features,” in European conference on computer vision, pp. 404–417, Springer, 2006.
[203] D. G. Lowe, “Distinctive image features from scale-invariant keypoints,” International journal of computer vision, vol. 60, no. 2, pp. 91–110, 2004.
[204] M. Calonder, V. Lepetit, C. Strecha, and P. Fua, “Brief: Binary robust independent elementary features,” in European conference on computer vision, pp. 778–792, Springer, 2010.
[205] E. Rublee, V. Rabaud, K. Konolige, and G. Bradski, “Orb: An efficient alternative to sift or surf,” in 2011 International conference on computer vision, pp. 2564–2571, Ieee, 2011.
[206] V. Balntas, E. Riba, D. Ponsa, and K. Mikolajczyk, “Learning local feature descriptors with triplets and shallow convolutional neural networks.,” in Bmvc, vol. 1, p. 3, 2016.
[207] E. Simo-Serra, E. Trulls, L. Ferraz, I. Kokkinos, P. Fua, and F. Moreno-Noguer, “Discriminative learning of deep convolutional feature point descriptors,” in Proceedings of the IEEE International Conference on Computer Vision, pp. 118–126, 2015.
[208] K. Simonyan, A. Vedaldi, and A. Zisserman, “Learning local feature descriptors using convex optimisation,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 36, no. 8, pp. 1573– 1585, 2014.
[209] K. Moo Yi, E. Trulls, Y. Ono, V. Lepetit, M. Salzmann, and P. Fua, “Learning to find good correspondences,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2666–2674, 2018.
[210] P. Ebel, A. Mishchuk, K. M. Yi, P. Fua, and E. Trulls, “Beyond cartesian representations for local descriptors,” in Proceedings of the IEEE International Conference on Computer Vision, pp. 253–262, 2019.
[211] N. Savinov, A. Seki, L. Ladicky, T. Sattler, and M. Pollefeys, “Quadnetworks: unsupervised learning to rank for interest point detection,” in Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 1822–1830, 2017.
[212] L. Zhang and S. Rusinkiewicz, “Learning to detect features in texture images,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 6325–6333, 2018.
[213] A. B. Laguna, E. Riba, D. Ponsa, and K. Mikolajczyk, “Key. net: Keypoint detection by handcrafted and learned cnn filters,” arXiv preprint arXiv:1904.00889, 2019.
[214] Y. Ono, E. Trulls, P. Fua, and K. M. Yi, “Lf-net: learning local features from images,” in Advances in neural information processing systems, pp. 6234–6244, 2018.
[215] K. M. Yi, E. Trulls, V. Lepetit, and P. Fua, “Lift: Learned invariant feature transform,” in European Conference on Computer Vision, pp. 467–483, Springer, 2016.
[216] C. G. Harris, M. Stephens, et al., “A combined corner and edge detector.,” in Alvey vision conference, vol. 15, pp. 10–5244, Citeseer, 1988.
[217] Y. Tian, V. Balntas, T. Ng, A. Barroso-Laguna, Y. Demiris, and K. Mikolajczyk, “D2d: Keypoint extraction with describe to detect approach,” arXiv preprint arXiv:2005.13605, 2020.
[218] C. B. Choy, J. Gwak, S. Savarese, and M. Chandraker, “Universal correspondence network,” in Advances in Neural Information Processing Systems, pp. 2414–2422, 2016.
[219] M. E. Fathy, Q.-H. Tran, M. Zeeshan Zia, P. Vernaza, and M. Chandraker, “Hierarchical metric learning and matching for 2d and 3d geometric correspondences,” in Proceedings of the European Conference on Computer Vision (ECCV), pp. 803–819, 2018.
[220] N. Savinov, L. Ladicky, and M. Pollefeys, “Matching neural paths: transfer from recognition to correspondence search,” in Advances in Neural Information Processing Systems, pp. 1205–1214, 2017.
[221] T. Sattler, W. Maddern, C. Toft, A. Torii, L. Hammarstrand, E. Stenborg, D. Safari, M. Okutomi, M. Pollefeys, J. Sivic, et al., “Benchmarking 6dof outdoor visual localization in changing conditions,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 8601–8610, 2018.
[222] H. Zhou, T. Sattler, and D. W. Jacobs, “Evaluating local features for day-night matching,” in European Conference on Computer Vision, pp. 724–736, Springer, 2016.
[223] Q.-H. Pham, M. A. Uy, B.-S. Hua, D. T. Nguyen, G. Roig, and S.-K. Yeung, “Lcd: Learned cross-domain descriptors for 2d-3d matching,” arXiv preprint arXiv:1911.09326, 2019.
[224] W. Lu, Y. Zhou, G. Wan, S. Hou, and S. Song, “L3-net: Towards learning based lidar localization for autonomous driving,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 6389–6398, 2019.
[225] H. Yin, L. Tang, X. Ding, Y. Wang, and R. Xiong, “Locnet: Global localization in 3d point clouds for mobile vehicles,” in 2018 IEEE Intelligent Vehicles Symposium (IV), pp. 728–733, IEEE, 2018.
[226] M. Angelina Uy and G. Hee Lee, “Pointnetvlad: Deep point cloud based retrieval for large-scale place recognition,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4470–4479, 2018.
[227] I. A. Barsan, S. Wang, A. Pokrovsky, and R. Urtasun, “Learning to localize using a lidar intensity map.,” in CoRL, pp. 605–616, 2018.
[228] W. Zhang and C. Xiao, “Pcan: 3d attention map learning using contextual information for point cloud based retrieval,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 12436–12445, 2019.
[229] W. Lu, G. Wan, Y. Zhou, X. Fu, P. Yuan, and S. Song, “Deepicp: An end-to-end deep neural network for 3d point cloud registration,” arXiv preprint arXiv:1905.04153, 2019.
[230] Y. Wang and J. M. Solomon, “Deep closest point: Learning representations for point cloud registration,” in Proceedings of the IEEE International Conference on Computer Vision, pp. 3523–3532, 2019.
[231] X. Bai, Z. Luo, L. Zhou, H. Fu, L. Quan, and C.-L. Tai, “D3feat: Joint learning of dense detection and description of 3d local features,” arXiv preprint arXiv:2003.03164, 2020.
[232] E. Brachmann and C. Rother, “Visual camera re-localization from rgb and rgb-d images using dsac,” arXiv preprint arXiv:2002.12324, 2020.
[233] B. Triggs, P. F. McLauchlan, R. I. Hartley, and A. W. Fitzgibbon, “Bundle adjustmenta modern synthesis,” in International workshop on vision algorithms, pp. 298–372, Springer, 1999.
[234] J. Nocedal and S. Wright, Numerical optimization. Springer Science & Business Media, 2006.
[235] R. Clark, M. Bloesch, J. Czarnowski, S. Leutenegger, and A. J. Davison, “Learning to solve nonlinear least squares for monocular stereo,” in Proceedings of the European Conference on Computer Vision (ECCV), pp. 284–299, 2018.
[236] C. Tang and P. Tan, “Ba-net: Dense bundle adjustment network,” International Conference on Learning Representations (ICLR), 2019.
[237] H. Zhou, B. Ummenhofer, and T. Brox, “Deeptam: Deep tracking and mapping with convolutional neural networks,” International Journal of Computer Vision, vol. 128, no. 3, pp. 756–769, 2020.
[238] J. Czarnowski, T. Laidlow, R. Clark, and A. J. Davison, “Deepfactors: Real-time probabilistic dense monocular slam,” IEEE Robotics and Automation Letters, 2020.
[239] N. Sunderhauf, S. Shirazi, A. Jacobson, F. Dayoub, E. Pepperell, ¨ B. Upcroft, and M. Milford, “Place recognition with convnet landmarks: Viewpoint-robust, condition-robust, training-free,” Proceedings of Robotics: Science and Systems XII, 2015.
[240] X. Gao and T. Zhang, “Unsupervised learning to detect loops using deep neural networks for visual slam system,” Autonomous robots, vol. 41, no. 1, pp. 1–18, 2017.
[241] N. Merrill and G. Huang, “Lightweight unsupervised deep loop closure,” Robotics: Science and Systems, 2018.
[242] A. R. Memon, H. Wang, and A. Hussain, “Loop closure detection using supervised and unsupervised deep neural networks for monocular slam systems,” Robotics and Autonomous Systems, vol. 126, p. 103470, 2020.
[243] S. Wang, R. Clark, H. Wen, and N. Trigoni, “End-to-end, sequenceto-sequence probabilistic visual odometry through deep neural networks,” The International Journal of Robotics Research, vol. 37, no. 4-5, pp. 513–542, 2018.
[244] Y. Gal and Z. Ghahramani, “Dropout as a bayesian approximation: Representing model uncertainty in deep learning,” in international conference on machine learning, pp. 1050–1059, 2016.
[245] A. Kendall and Y. Gal, “What uncertainties do we need in bayesian deep learning for computer vision?,” in Advances in neural information processing systems, pp. 5574–5584, 2017.
[246] C. Chen, X. Lu, J. Wahlstrom, A. Markham, and N. Trigoni, “Deep neural network based inertial odometry using low-cost inertial measurement units,” IEEE Transactions on Mobile Computing, 2019.
[247] A. Kendall, V. Badrinarayanan, and R. Cipolla, “Bayesian segnet: Model uncertainty in deep convolutional encoder-decoder architectures for scene understanding,” in British Machine Vision Conference 2017, BMVC 2017, 2017.
[248] R. McAllister, Y. Gal, A. Kendall, M. Van Der Wilk, A. Shah, R. Cipolla, and A. Weller, “Concrete problems for autonomous vehicle safety: advantages of bayesian deep learning,” in Proceedings of the 26th International Joint Conference on Artificial Intelligence, pp. 4745–4753, AAAI Press, 2017.
[249] M. Klodt and A. Vedaldi, “Supervising the new with the old: learning sfm from sfm,” in Proceedings of the European Conference on Computer Vision (ECCV), pp. 698–713, 2018.
[250] H. Rebecq, T. Horstschafer, G. Gallego, and D. Scaramuzza, “Evo: ¨ A geometric approach to event-based 6-dof parallel tracking and mapping in real time,” IEEE Robotics and Automation Letters, vol. 2, no. 2, pp. 593–600, 2016.
[251] M. R. U. Saputra, P. P. de Gusmao, C. X. Lu, Y. Almalioglu, S. Rosa, C. Chen, J. Wahlstrom, W. Wang, A. Markham, and ¨ N. Trigoni, “Deeptio: A deep thermal-inertial odometry with visual hallucination,” IEEE Robotics and Automation Letters, vol. 5, no. 2, pp. 1672–1679, 2020.
[252] C. X. Lu, S. Rosa, P. Zhao, B. Wang, C. Chen, J. A. Stankovic, N. Trigoni, and A. Markham, “See through smoke: Robust indoor mapping with low-cost mmwave radar,” in Proceedings of the 18th International Conference on Mobile Systems, Applications, and Services, MobiSys 20, (New York, NY, USA), p. 1427, Association for Computing Machinery, 2020.
[253] B. Ferris, D. Fox, and N. D. Lawrence, “Wifi-slam using gaussian process latent variable models.,” in IJCAI, vol. 7, pp. 2480–2485, 2007.
[254] C. X. Lu, Y. Li, P. Zhao, C. Chen, L. Xie, H. Wen, R. Tan, and N. Trigoni, “Simultaneous localization and mapping with power network electromagnetic field,” in Proceedings of the 24th annual international conference on mobile computing and networking (MobiCom), pp. 607–622, 2018.
[255] Q.-s. Zhang and S.-C. Zhu, “Visual interpretability for deep learning: a survey,” Frontiers of Information Technology & Electronic Engineering, vol. 19, no. 1, pp. 27–39, 201