---------------------------------------------------------------------------------------------
背景:
进来很多3D的应用在兴起,3D传感器在进步,随着虚拟网络的发展转到物理实际中的应用,比如自动驾驶中需要理解 汽车行人交通标识,同时也需要理解三维物体的状态静至,移动

AR深度传感器,也需要做三维场景的理解。需要一种数据驱动的方式,3D deep learning。
三维数据本身有一定的复杂性,2D图像可以轻易的表示成矩阵,3D表达形式:
point cloud ,深度传感器扫描得到的深度数据点云
Mesh,三角面片在计算机图形学中渲染和建模话会很有用。
Volumetric,将空间划分成三维网格,栅格。
Multi-View,用多个角度的图片表示物体
Point c'loud 是一种非常适合于3D场景理解的数据,原因是:
点云是非常接近传感器的数据集,激光雷达扫描之后的,深度传感器(深度图像)只不过是一个局部的点云
原始的数据可以做端到端的深度学习,挖掘原始数据中的模式
Mesh需要选择面片类型和连接
网格需要选择多大的网格,分辨率。
图像的选择,需要选择拍摄的角度,但是表达是不全面的。
之前的大部分工作都是集中在手工设计点云数据的:

特征都是针对特定任务,有不同的假设,新的任务很难优化特征。 希望用深度学习特征学习去解 决数据的问题。
但是点云数据是一种不规则的数据,之前的研究者在点云上会先把它转化成一个规则的数据,比如栅格让其均匀分布,然后再用3D-cnn 来处理栅格数据:

缺点:3D cnn 复杂度相当的高,所以分辨率不高30*30*30 ,量化的噪声错误,限制识别的错误
1、但是如果考虑不计复杂度的栅格,会导致大量的栅格都是空白,智能扫描到表面,内部都是空白的。所以栅格并不是对3D点云很好的一种表达方式
2、有人考虑过,用3D点云数据投影到2D平面上用2Dcnn 进行训练,这样会损失3D的信息。 还要决定的投影的角度
3、点云中提取手工的特征,再接FC,这么做有很大的局限性

我们能否直接用一种在点云上学习的方法:


网络设计有两种点云的特点决定的:
点云是点的集合,对点的顺序不敏感,

最简单的D=3,还可以有其他颜色,法向
点集是无须的,可以做变化,置换不变性。 模型需要对N!需要做到置换的不变性。
系统化的解决方案,对称函数,具有置换不变性。


如何用神经网络构建对称函数:最简单的例子:
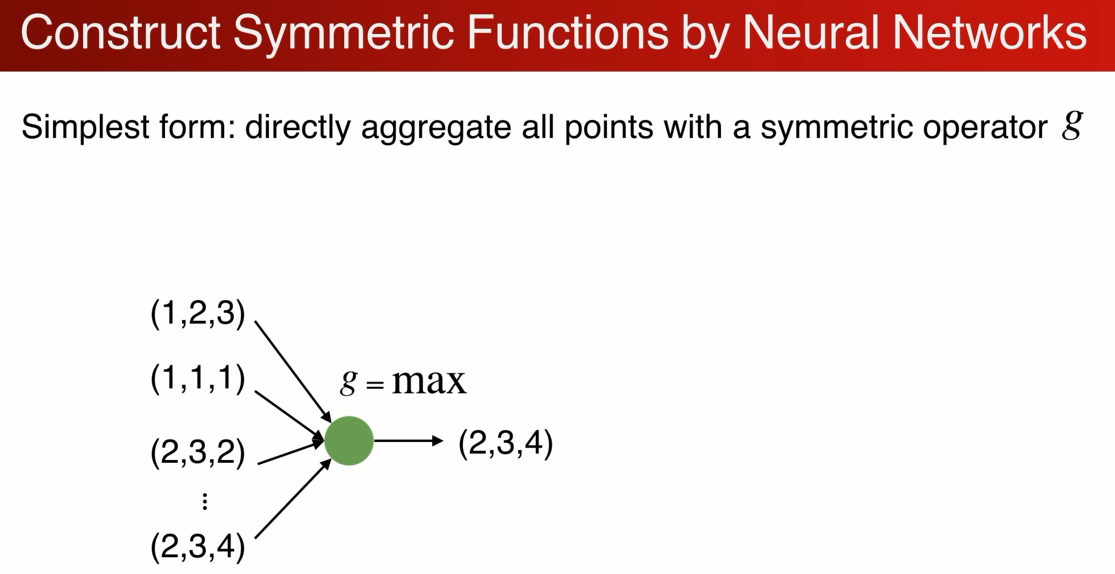

但是这种方式只计算了点的边界,损失了很多有意义的几何信息,如何解决呢?
与其说直接做对称性可以先把每个点映射到高维空间,在高维空间中做对称性的操作,高维空间可以是一个冗余的,在max操作中通过冗余可以避免信息的丢失,可以保留足够的点云信息,再通过一个网络r来进一步消化点云的信息。这就是函数hgγ的组合。G是对称的那么整个结构就都是对称的。下图就是原始的pointnet结构。
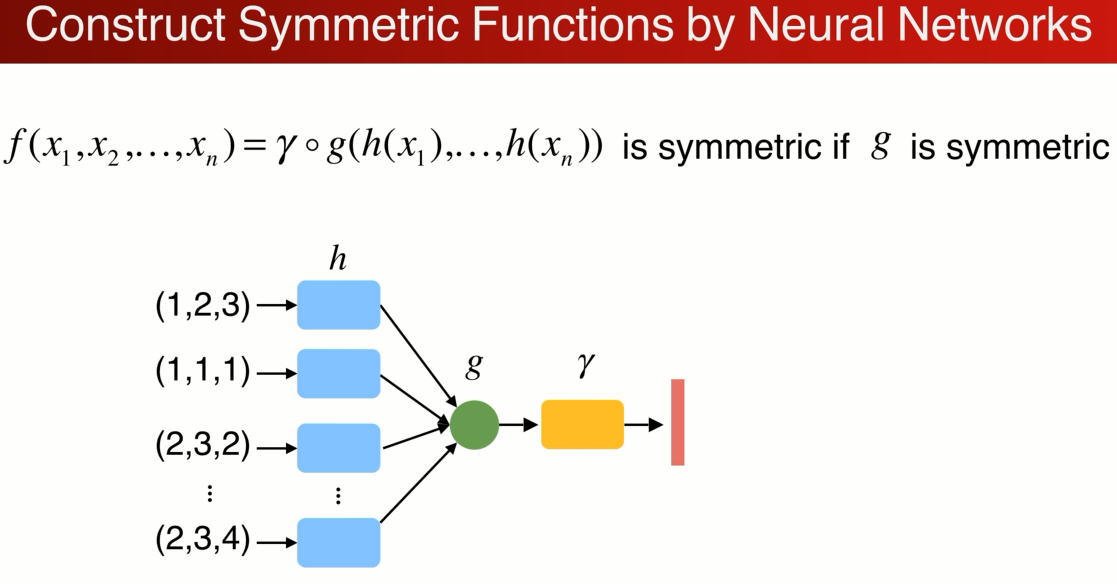
实际操作过程中:
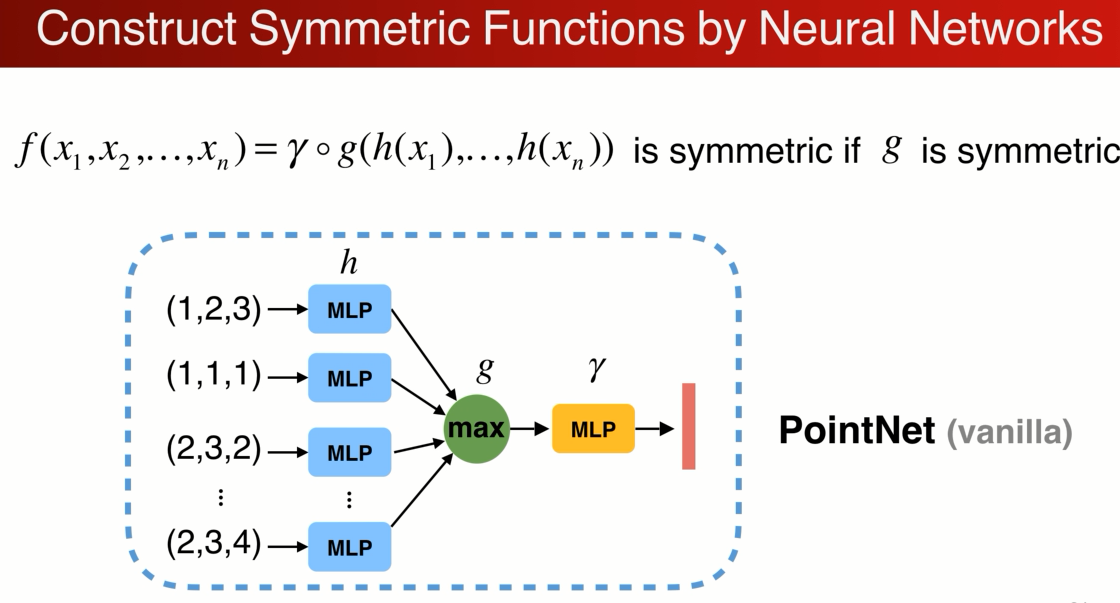
在实际执行过程中
可以用MLP(Multilayer perceptron) 来描述h和γ,g max polling 效果最好。
接下来有个很有意思的理论问题,用神经网络构建的pointnet中,保证了对称
那么在所有的对称函数中,point(vanilla)是什么样的位置呢?什么样的函数pointnet 能代表,什么函数不能代表
理论:

pointnet 可以任意的逼近堆成函数,只要是对称函数是在hausdorff空间是连续的,那么就可以通过任意的增加神经网络的宽度深度,来逼近这个函数

上面解释了如果通过对称函数,来让点云输入顺序的不变
2、如何来应对输入点云的几何变换,比如一辆车在不同的角度点云的xyz都是不同的 但代表的都是扯,我们希望网络也能应对视角的变换

增加了一个基于数据本身的变换函数模块,n个点 t-net 生成变换参数,目的是对其输入
实际中点云的变化很简单,不像图片做变换需要做插值,做矩阵乘法就可以。比如对于一个3*3的矩阵仅仅是一个正交变换
我们可以推广这个操作,不仅仅在输入作此变换,还可以在中间做 N个点 K维特征,用另外网络生成k*k 来做特征空间的变化,生成另一组特征
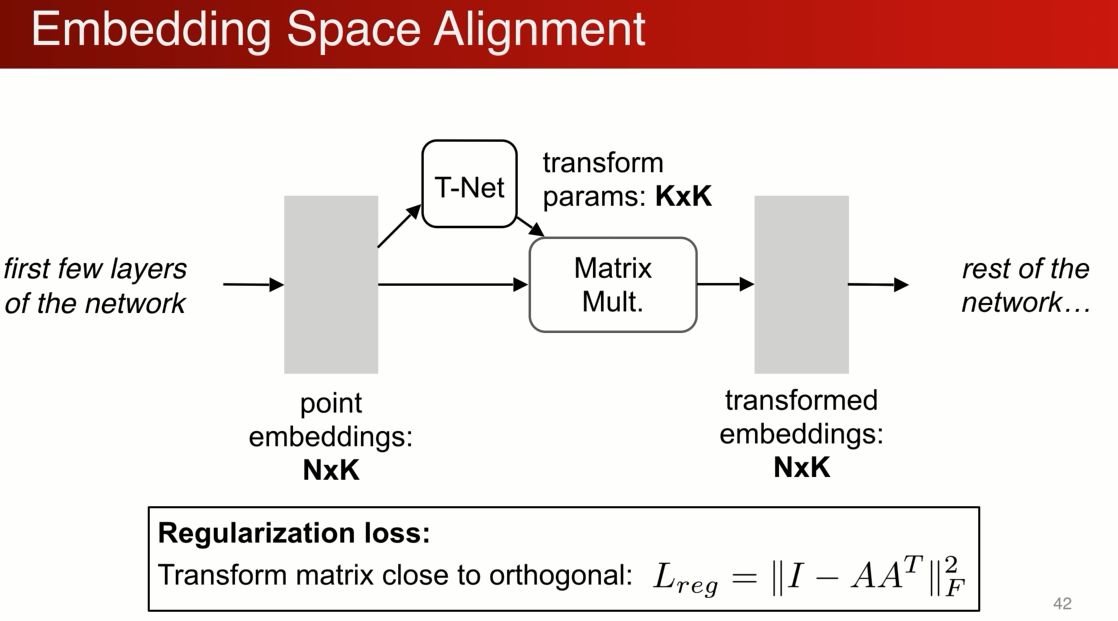
高维优化过程中,难度高,需要加正则化,比如希望矩阵更加接近正交矩阵
那么这些变换的网络如何和pointnet结合起来:得到分类和分割网络
首先输入一个n*3的矩阵,先做一个输入的矩阵变换,变成一个3*3的矩阵,然后通过mlp投射到高维空间,形成一个更加归一化的64维矩阵,继续做MLP将64维映射到1024维,在1024中可以做对称性的操作,就是maxpooling,得到globle fearue ,通过级联的全连接网络生成k (分类)

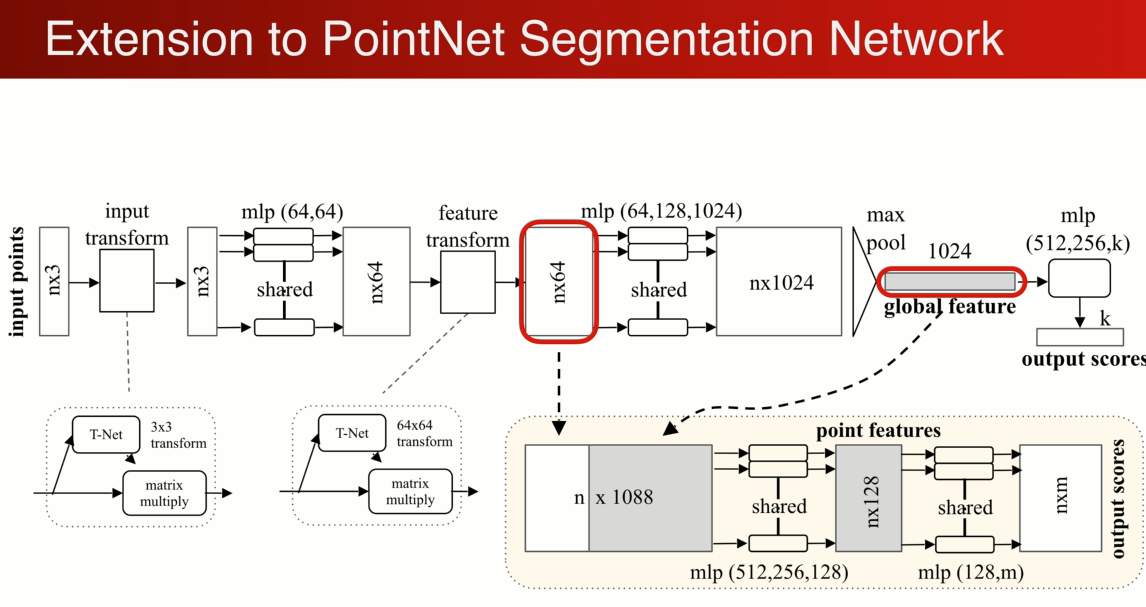
如果是分割呢? 可以定以成对每个点的分类问题,通过全局坐标是没法对每个点进行分割的,简单有效的做法是,将局部单个点的特征和全局的坐标结合起来,实现分割的功能
最简单的做法是将全局特征重复N遍,每一个个原来单个点的特征连接在一起,相当于单个点在全局特征中进行了一次检索,对连接起来的特征进行MLP的变换,最后输出m类相当于m个score:
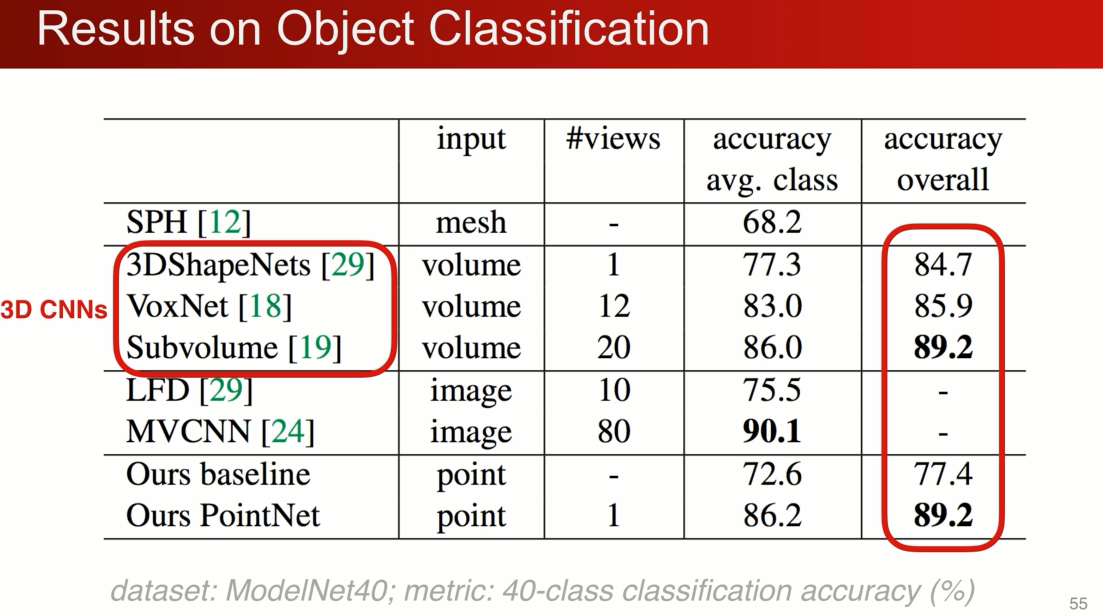
结果:

部件分割和完整的分割。


还是个非常轻量级的网络:


对数据的丢失也是非常的鲁棒,对比于voxelnet 的对比
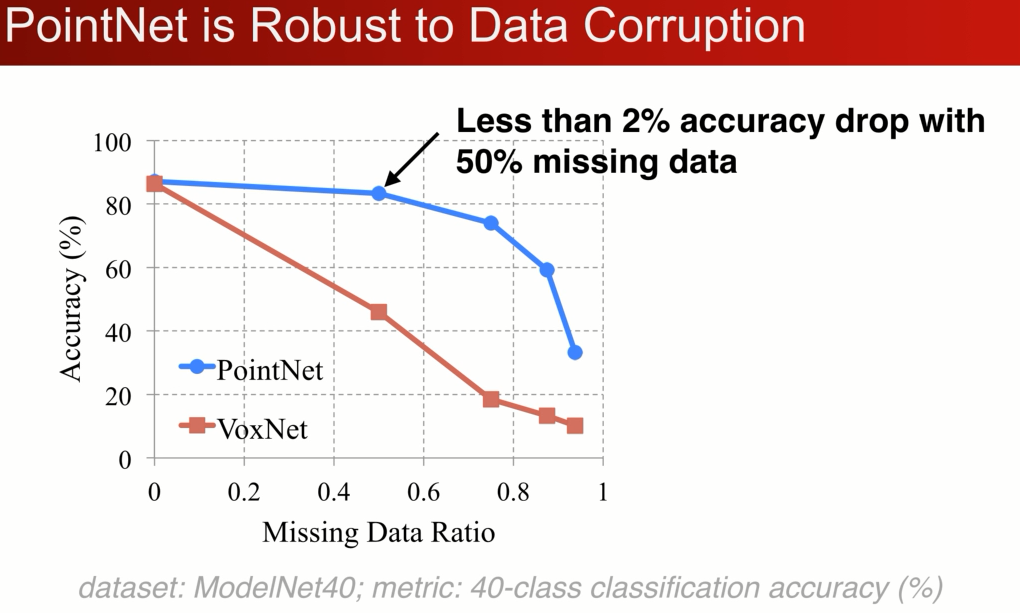
在modelnet 40 的分类问题上,在丢失50%的点的情况下,pointnet仅仅收到2%的影响,与之想想比Voxnet精度相差了20%
为什么呢?
第一行是原始的,我们想知道哪些点对全局特征做出了贡献,maxpooling ,有些店embedded的特征非常小,在经过maxpooling之后对全局特征没有任何的贡献,哪些点是剩下来的胜利者
Critial points (Maxpooling 之后存活下来的大特征点)

只要轮廓和骨骼得到保存,就能把形状分类正确。
--------------------------------------------------------------------------------------------------------------------
PointNet++
pointnet 缺陷:对比3Dcnn
3D和2D很像,只是变成了3D卷积,多级学习 不断抽象,平移不变性。

本质上来说,要么对一个点做操作,要么对所有点做操作,实际上没有局部的概念(loal context)
比较难对精细的特征做学习,在分割上有局限性
2、没有local context 在平移不变性上也有局限性。(xyz)对点云数据做平移 所有的数据都不一样了,导致所有的特征,全局特征都不一样了,分类也不一样
对于单个的物体还好,可以将其平移到坐标系的中心,把他的大小归一化到一个球中,在一个场景中有多个物体不好办,对哪个物体做归一化呢?

pointnet ++ 核心的想法在局部区域重复性的迭代使用pointnet ,在小区域使用pointnet 生成新的点,新的点定义新的小区域,
多级的特征学习,应为是在区域中,我们可以用局部坐标系,可以实现平移的不变性,同时在小区域中还是使用的PN,对点的顺序是无关的,保证置换不变性。
具体的例子: 多级的点云学习:
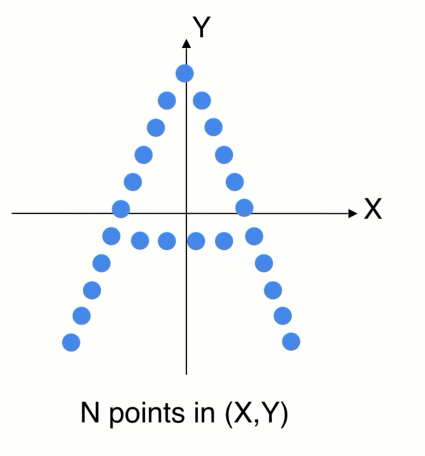
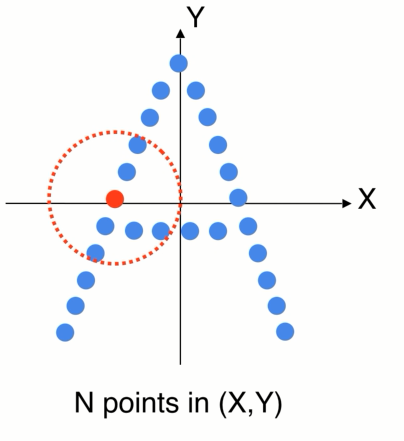
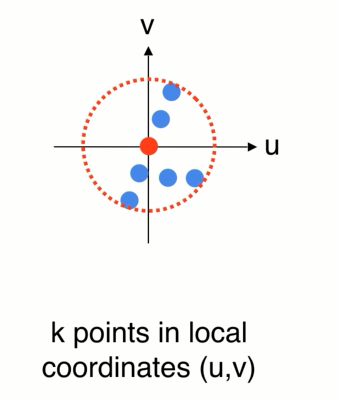

2D卡通的例子,世界坐标系,先找到一个局部的区域,因为不想受整体平移的影响,可以先把局部的点转换到一个局部坐标系中,在局部中使用pointnet 来提取特征 ,提取完特征以后会得到一个新的点,F (x,y )在整个点云中的位置,还有个向量特征F(高纬的特征空间),代表小区域的几何形状,
如果重复这个操作就会得到一组新的点,在数量上少于原先的点,但是新的每个点代表了它周围一个区域的几何特点
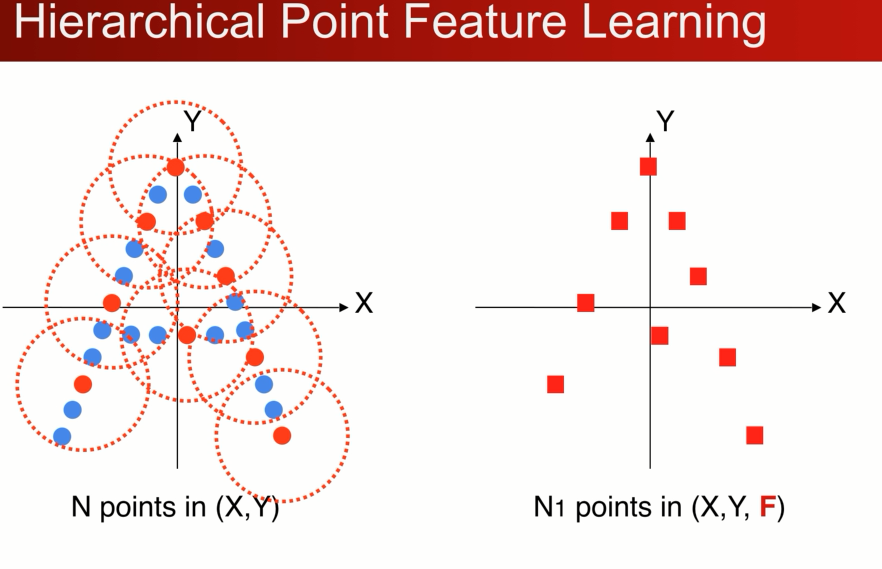

点集的简化, layer:选择小区域,提取小区域提取局部坐标系,应用point 联合而成。
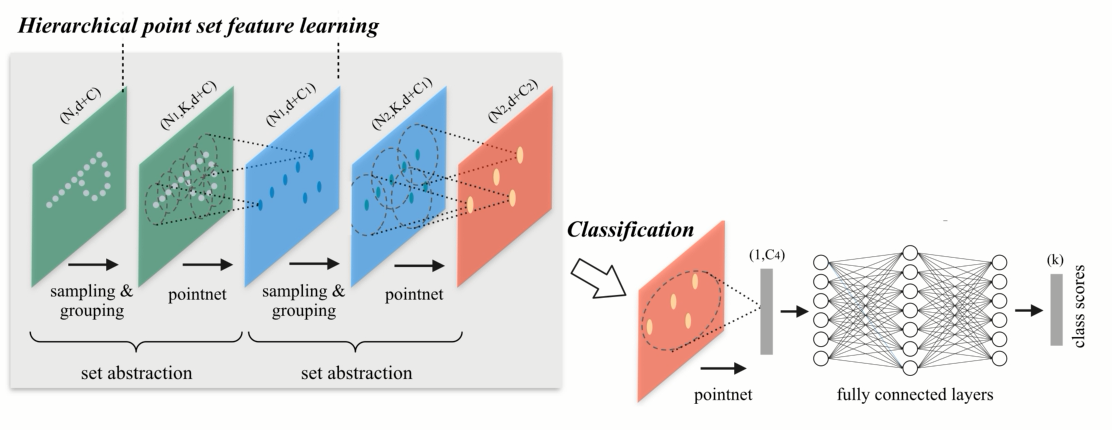
我们可以重复set abstraction的过程,实现一个多级的网络,下图展示两级
使得点的数量越来越少,但是每个点代表的区域以及感受野,越来越大,这个cnn的概念很类似,,最后把点做一个pooling 得到globle feature,用来做分类。
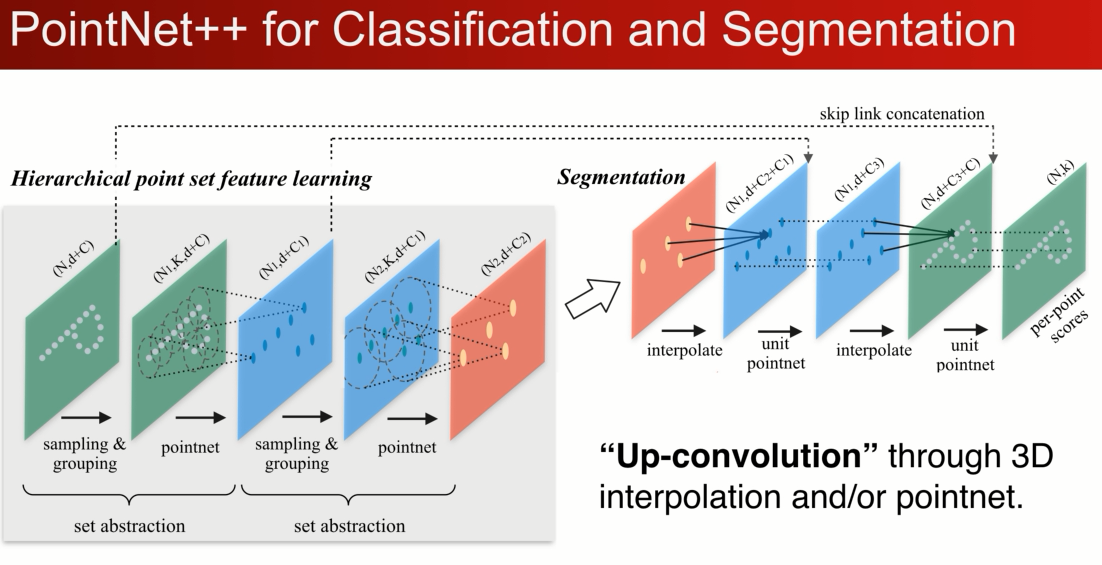
我们可以将最后的点重新上卷积的方式传回原来的点上,既可以通过3D的插值,可以通过另一种通过pn的方式回传。
在多级网络中有一个很有意思的问题,如何选择局部区域的大小,相较而言就是怎么选择卷积核的大小宽度,如果选择pointnet 作用区域的球的半径。
在卷积神经网络中大量应用小的kernal,在pointcloud中是否一样呢?不一定。
应为pointnet 常见的采样率的不均匀,比如有个depth camera 采到的图像,近的点非常密集,远的点非常稀疏,在密的地方没有问题,在稀疏的会有问题,比如极端的情况,只有一个点,这样学到的特征会非常的不稳定,我们因该避免。
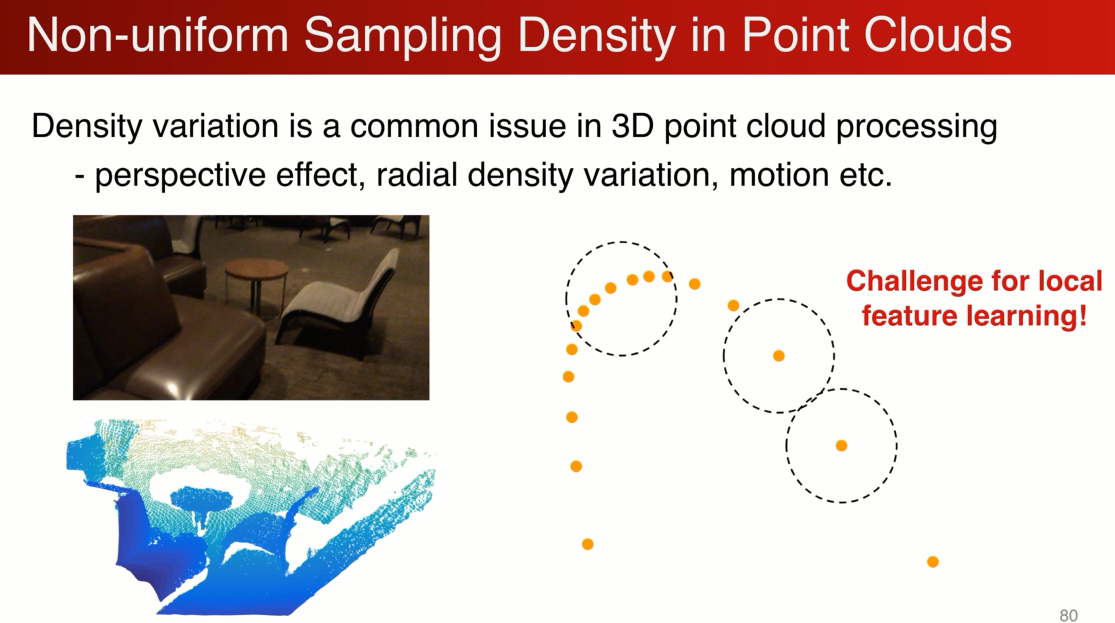
为了量化这个问题,有个控制变量的实验,在1024上训练,减少点的数量相当于减少点的密度,不均匀的减少,
在刚开始1024点的时候point net ++ 更加强大,得到更高的精确度,应为它是在小区域上,随着密度的下降,性能收到了极大的影响,在小于500个点以后性能低于pointnet
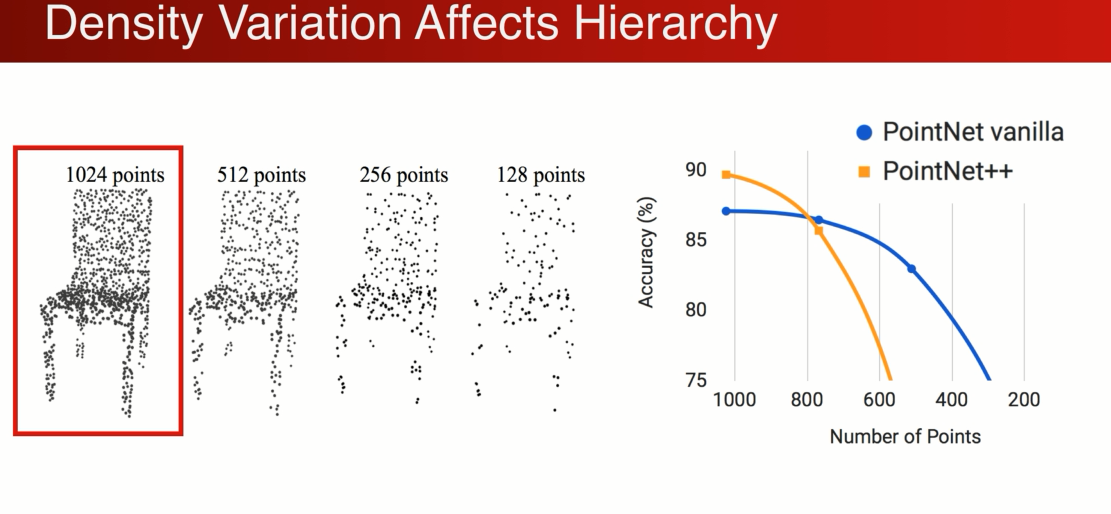

结论:在pointcloud 中 如果局部的kernel 操作太小的话,会影响性能被采样率不均匀。
针对于这个问题,我们希望设计一个神经网络来智能学习,如何综合不同区域大小的特征,得到一个鲁棒的学习层,
希望在密集的地方相信这个特征,稀疏的地方不相信这个特征,而去看更大的区域
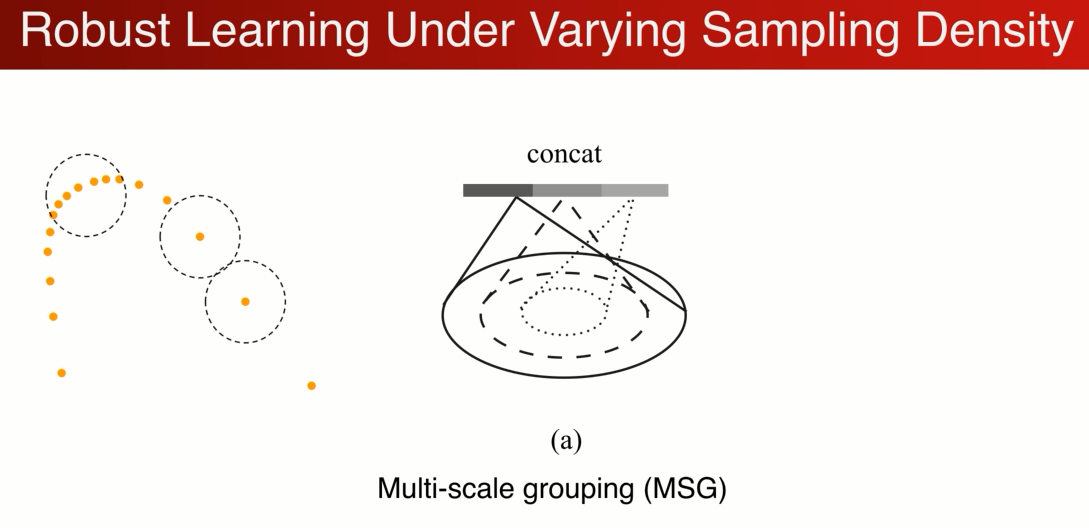

比较简单的做法是设计一个Multi-scale : 在这个2D的例子中 将不同半径的区域 ,联合在一起。有点像inception 中的结构,
但不一样的是,在训练过程中随机的对输入的dropout, 迫使网络学习若何结合不同的尺度应对损失的数据的特征。
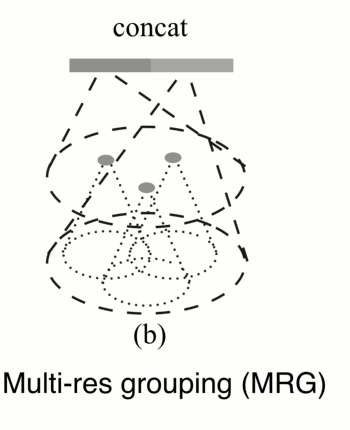
另外一种方式不是在同一级中,而是在不同网络集中综合,有个好处,可以节省计算,下一级的特征已经计算好了,只需要把它池化拿来用就行了。 而在mutile scale中需要对不同尺度分别计算。
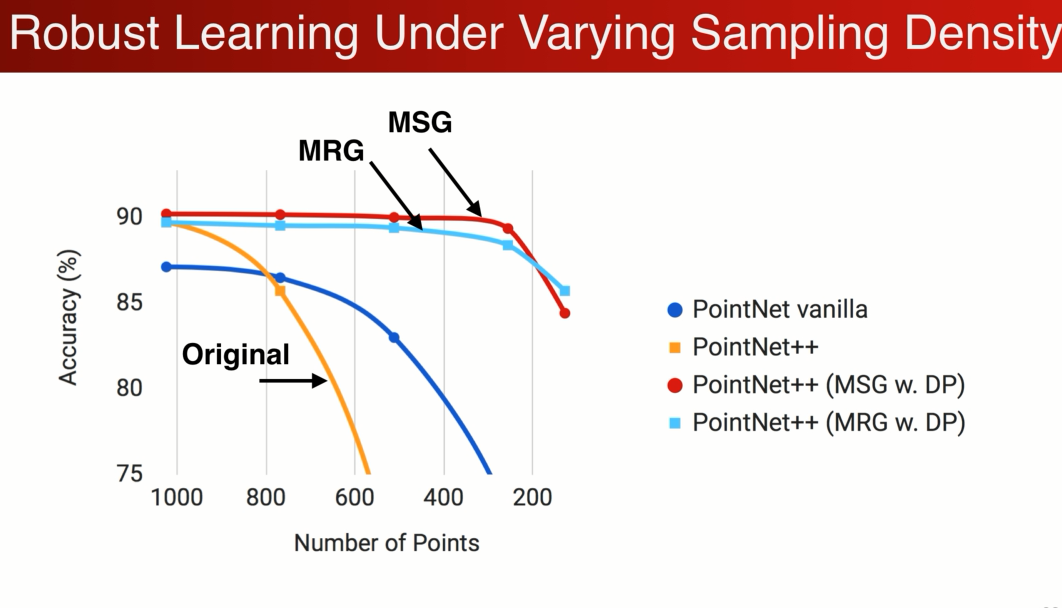
发现加了MRG和MSG中,丢失数据后鲁棒性能好很多。丢失75%的点 分类都不会受到影响。
下图是在scanenet 上对场景分割做评估:
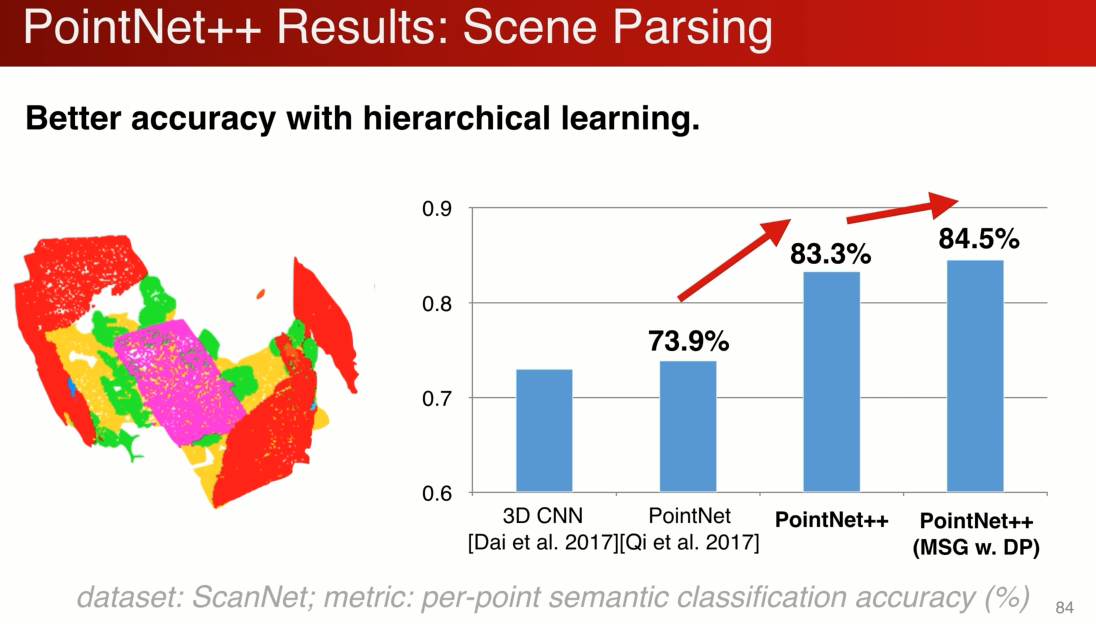
pointnet ++ 大幅提高了性能,因为多级的结构,使得他对局部的特征更好的学习,同时还有平移不变性的特点。同时多级分割稍稍提升了性能。
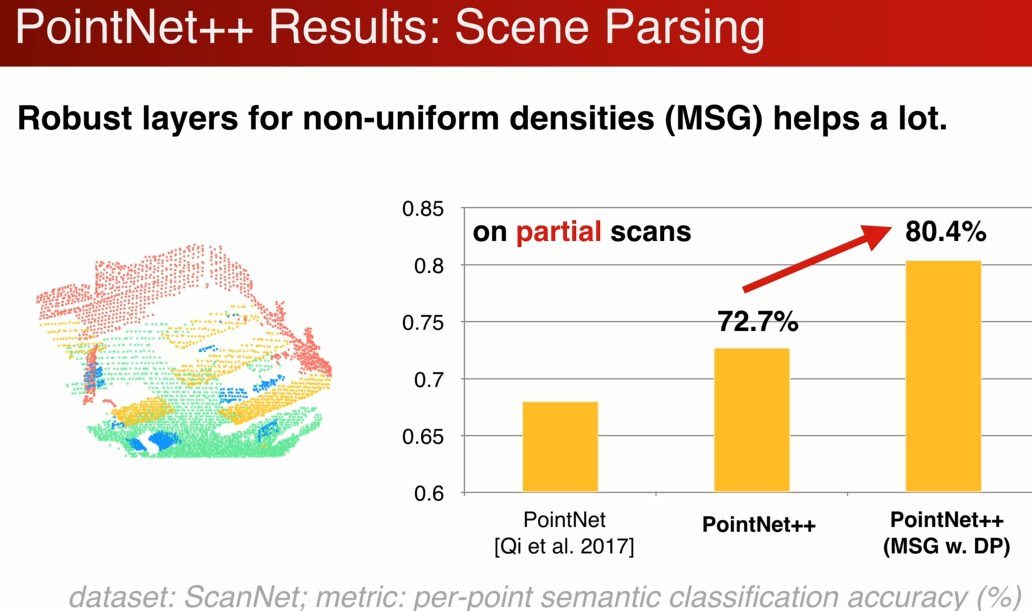
全点云的分割:但个角度,局部点云,多级结构对采样率更鲁棒的MSG大幅提升了partial scan的性能。
另一个POINT ++非常好的性能是 不局限于2D或者3D,可以拓展到任意的测度空间,只要有个定义好的距离函数,下面展示对可变性物体,有机物提分割的数据集
比如分类:AB 属于几何外形相似,但是属于不同的类别,AC反之。
不是想依靠XYZ,想依靠物体表面形状的变化。

上面网络结构、设计原理
----------------------------------------------------------------------------------------------------------------------------------------------
PN在三维场景理解中的应用:
点云支持我们探索全新的解决方案,基于3D数据的解决方案,

侧重前者,3D场流估计可以跳过,

下面是在图片中的表达:再点云中可视化的例子
之前的工作是怎么处理三维物体的呢?
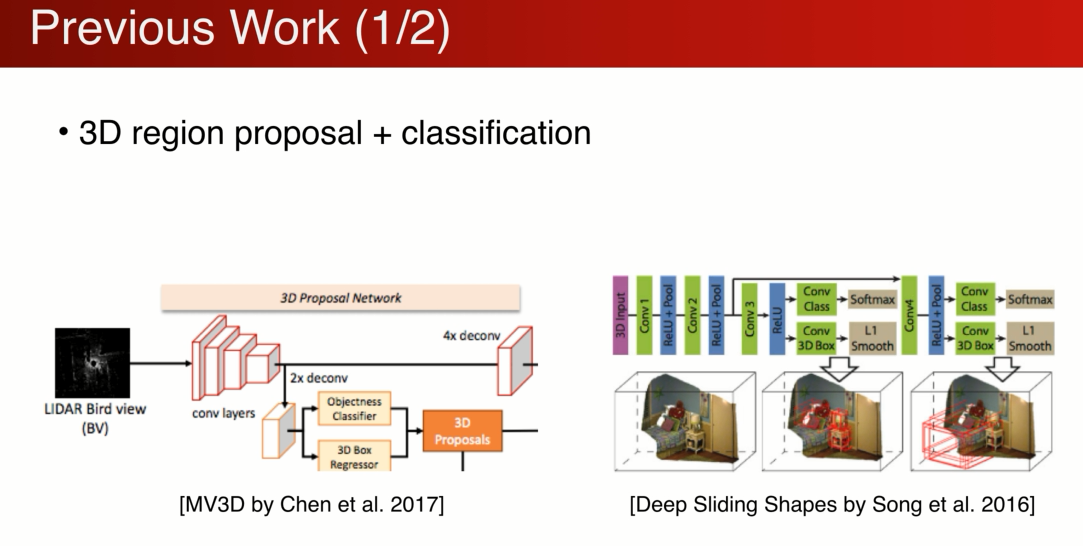

很大一套工作是基于,
先在三维空间中做region proposal, 基于点云投影到图片上,在图片中proposal 三维的box
也可以是3D的cnn来做,
propos完之 后可以把2D和3D的feature 结合到proposal中,做一个分类。
缺点是:三维搜索空间非常大,计算量也非常大,而且在3D中proposal 点云的分辨率非常有限,很多时候很难发现比较小的物体。
另外一套思路是基于图片的,我想通过RGB的图片估计3D的box,依赖于对物体大小的先验知识,很难精确的估计物体的大小和位置。
另外也可以基于depth image。对其领域的定义有很多局限,比如两个点在空间中距离很远,但是投影之后的距离会非常近。
所以在图片的表达形式下,2D的cnn收到了很大的局限。很难精确的估计物体的深度和大小
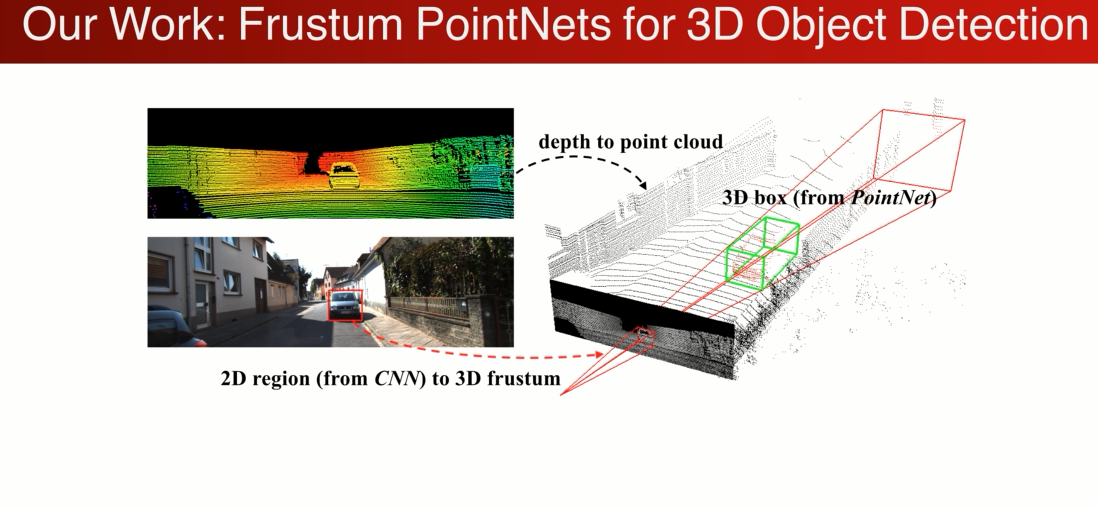
我们的设计思路 希望结合2D和3D的优点,
针对与RGB-D 的输入,先在RGB图片上用一个2Ddector 得到一个2D的检测框,
因为我们知道camera intrases,我们可以有2D的区域(逆投影)生成一个3D的视锥frustum,接下来对物体的搜索就可以在视锥内进行搜索,我们可以将其转化成在3D点云中搜索的问题,
好处,利用2D的detector 来缩小搜索的范围,本来需要在整个3D空间中,因为有2Ddector的帮忙,可以在视锥的范围内搜索,大幅减少了搜索的计算量和复杂度,
2、在视锥内可以针对于点云做操作,利用点云几何的精确性。利用3D,deeplearning 的工具(pointnet)直接处理点云的数据,得到非常精确的3DBB。

基于视锥的3D物体检测,有两个挑战:
1、前景的遮挡和后景的干扰,基于层级的方法在这都会败下阵来
2、点的范围很大,很难用3D cnn 网格化栅格化。
pointnet 3D点云的解决方案:
利用一个2Ddection 将物体检测出来,根据照相机的参数,可以把2D box 变换到 3d 视锥的范围,由于前景的干扰和后景的干扰,希望把关键点拿出来
所以后面会接一个3D pointnet的分割网络。分割出来以后呢,再用一个精确的网络估计物体的3D bb,位置大小
在汽车 小物体(行人 自行车)优势更大。
因为2D的分辨率很高,小物体有优势
为什么有这么优异的结果呢?有两方面原因:
1 选择了3D 分割方法,相比mask-rcn 。将2d的depth point 拿出来发现分割效果非常差,原因是:在图片中很近,但是在3d中很远的,

另外 对输入做归一化,因为对点云的归一化,可以简化学习问题:
比如:

a:俯视图,汽车的位置视锥的范围x 很大
b:归一化之后,旋转z轴,把z指向视锥的中心方向,简化了x的分布和学习问题,
c:进一步,在深度上,z上有很大的分布,我们基于3D物体分割可以找到分割后的中心,物体的点集中在原点附近,进一步简化
d:可以通过一个网络,去估计物体真实的中心,分割和物体中心可能不一样,在最后绿色坐标系进行bb估计
因为是点云数据,所以归一化操作比较方便。矩阵乘法就可以
总结:
两个网络,对输入顺序的置换不变性,轻量级的结构,对数据的丢失非常鲁棒,提供了一个统一的框架为不同的任务服务。具体在3d场景理解中,3d物体识别的应用
AI不仅仅在场景理解中有用,产品设计,
FAQ:
1 PN没考虑点之间的关系,在PN ++ 中有考虑
2 数据集,部件分割shapenet part 场景 s-3d-s scan-net
3 如果仅仅使用雷达,做3D物体检测,有没有可能进行拓展, 简单的拓展是在雷达中进行propal , 就不是一个视锥的propal了 ,把 雷达投影到地面变成一个鸟瞰图,在里面进行区域的pp,在pp里在估计3DBBx,这还是基于投影的方法。
能否直接在3D中做PP呢?苹果voxelnet 利用了pointnet 和3D cnn 直接在雷达数据中进行PP 和 dection
4 点的数量的评价?
输入点数量是可变吗?训练的时候是固定的,测试时候是可变的。
如果是单个图片的话,是可变的。多个其实也是可以的。只需要强行pad到一样的数目即可
5 未来发展趋势?
2D和3D结合,传感器的分辨率不高,3D几何信息丰富,更好的结合?
6 激光雷达 近密远疏 ,该怎么处理呢?
pointnet ++ 中有些结构 能处理这些不均匀采样率的问题,进一步 可以加W 来调节点云的分布
github 上都有数据集下载 可以 Frustum pointnet
7 pointnet ++ 如何用到实例分割
其实frustum pointnet 就是一种实例分割,实例分割在3D中是一个先做的问题,先有实例分割,后又物体检测
8 pointnet ++ 因为需要对局部特征做处理对GPU有要求
可以解决,可以专门写cuda layer 减少gpu的使用率。
1024 ba32 6G内存
9 frustum point 2d检测是gt还是检测结果:
gt ,进行了扰动,2个好处: 1、简单 2、可以和 2 d dector 有个分离,可以随时换2d dector,而不用重新训练后面的网络。
10 有没有可能直接用PN++ 直接对点云数据做检测?
正在研究,voxelnet 也是解决类似的问题
11 volnet 只对点云数据训练做到kitti第一?
只在车上,因为车相对比较大,只用点云应该够用,行人和自行车比较困难
12 法向量的作用?
如果仔细看的话,物体基于Mutil-view还是最领先的,分辨率高,键盘的建, 但是在点云上看和平板没区别。 在mesh上提取的法向量,就能把平板和键盘区别开
13 猫和马非欧空间是怎么处理的?
先算测地距离,降为到3d,用3d的欧式距离模拟测地距离
14 Tnet 可以用姿态gt 监督其训练
15 point ++ 结果不太问题,modelnet data size限制的,split test,鼓励在test 时进行多次旋转以后平均结果。
16 人脸点云很有潜力
17 3D行人检测有意义吗?
图片暗的时候,可以预防交通事故
18 pointnet ++ 中 release 版本没有+T-net 。在model-net分类上Tnet帮助不大,因为PN++ 已经学了局部特征,局部特征其实对旋转不太敏感,已经可以取得比较好效果
19 PN++ 有对局部点云变换的不变性吗?
局部加T-net 是不太合理的,并不能保证不同局部的变换是统一的,如果需要实现统一,capsil(?) net
20 法国数据集是室外的。 可以试试metapoint3D的数据集
21 RGB 相对于点云是锦上添花的
22 为什么用FPS降采样?希望达到一个均匀采样的效果,尽可能采远处的点
23 point++ 提供了多卡的
24 frustum 在2d检测不准的时候影响截断最终的结果吗?
会,但是有能力复原。但是2d的部分非常不好,会限制3D部分
25 GCNN 和 pointnet ++ 有很多相通的地方,在点云上的应用?
都是在3D空间中寻找局部,然后再局部定义某种操作,形成多级的网络架构
pointnet ++ 不仅适用于2d和3d ,还适用于非常高维的空间