关于Flask的一些笔记
Python
路由和视图函数
-
Flask对象的初始化是程序实例,一般的参数为程序主模块或包的名字,一般的Python.__name__属性即可。构造函数Flask根据这个参数找到程序的根目录,或者资源的根文件;
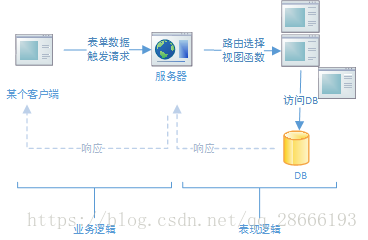
app = Flask(--name--)客户端(浏览器等)发送一个(Http)请求,对应的web服务器处理会把请求发送给Flask实例,也就是当前的app。这个实例根据这个请求的URL,执行对应的代码,返回响应。处理URL和代码映射的过程叫路由。在Flask中就是使用对象app.route函数装饰器,来进行路由处理的。这个装饰器装饰的函数是一个视图函数。
Python代码中嵌入字符串响应中会使代码难以维护,不建议使用。而使用模板进行处理。
另,URL映射除了装饰器外,还有非装饰器格式的app.add_url_rule() -
路由可以使用动态控制,动态部分的占位默认为字符串,也可以是int、path、float类型的;
app.route('/user/<int:id>')
程序和请求上下文
-
Flask收到请求后,视图函数处理的应该是一些请求对象。但是如果给每个视图函数都加上这些对象的参数,不便于代码维护和设计原则;Flask提供了一些上下文对象,暂时是全局可访问的。Flask中有程序上下文(current_app/g)和请求上下文(request/session)。
Flask在调用视图函数后,一般返回些简单的字符串,并且包含状态码(默认200)
响应的对象,可以是一个匿名的由返回字符串、状态码和头部消息,也可以使用response对象进行封装
也可以使用模板进行响应的抽离 -
我们希望web服务能够使用模板,将业务逻辑和表现逻辑分开:
- 模板中使用占位符,动态的将响应的内容加载进业务最终的逻辑视图中,呈现给用户。使用动态变量代替占位符的过程叫渲染。在渲染中,也可以动态的在路由中增加参数即变量,这些变量还可以进行过滤。
- jinja2的模板中,可以识别所有的数据类型:包括列表、字典、对象等;jinja2模板默认会对所有的变量进行转义,所以在进行含有HMML的参数传递时,要使用safe过滤器。
Bootstrap
- Bootstrap集成了一些css和js的HTML基础样式,可以看成是一种拓展的模板,可以进行更好的适配和优良的图形风格的包装。
- Bootstrap是客户端的框架,不会影响到服务端的操作,服务端只需引用即可。使用url_for函数可以代替html文件中写死的链接,而实现动态的变化
表单
-
Flask-WTF能保护所有表单免受跨站请求伪造。每个表单继承自一个Form类,其中有多个字段对象,附带多个验证函数。字段构造函数的第一个参数是把表单渲染成HTML的格式。
-
在表单中重新填写数据,但是不点击提交而是刷新浏览器时,会出现一个警告(post请求的)——浏览器会直接发送已处理的最后一个请求。所以建议一般post请求使用重定向的方式。重定向会使用URL定向到另一个地址,然后给这个URL发送GET请求。 这样一来,重定向后GET请求保留不了post请求中的数据,则使用session控制。
-
默认情况会使用cookies记录用户会话,cookies是本地存储的,使用设置过的secret_key进行加密签名;一旦cookies被篡改签名就会失效,cookies本身也将过期
-
session可以看成一个字典,一般不使用直接的键映射,而使用get,这样不存在键值是会返回None值;
数据库
- 数据中,具有ORM和ODM两种模型,前者成为对象关系映射,后者称为文档关系映射。可以将数据库的操作映射到面向对象的高级模型中。这两种把对象业务转换成数据库业务会有一定的损耗,但大部分情况下,这点损失能够带来更高的生产效率。
- SQLAlchemy ORM是Flask框架中提供的抽象层,支持多种关系型数据库引擎,包括MySQL、Postgres和SQLite。它是一个较强的关系型数据库框架,提供了高层ORM,也提供了使用数据库原生SQL的低层功能。程序中一般将数据库URL保存到Flask配置对象的配置文件一个KEY中(并且有一个key可以设置每次修改后的自动commit)。
- Flask-SQLAlchemy的数据库实例提供一个基类、一些函数和辅助函数定义模型结构。如db.model、db.Column等。不指定表名则会使用类名作为默认表名。
- 表间关系定义时,被参考的外键要使用db.relationship()函数定义,在主表中的Column函数定义中使用db.ForeignKey()函数说明。
- 数据库操作中有一个会话session,来管理数据库所作的改动,由db.session表示。
大型程序的结构
Flask并不强调大型项目使用特定的组织方式
- 配置选项:多个配置,开发、测试和生产环境需要不同的数据库等
- 程序工厂函数(_init_.py),是能够动态地实现程序实例的创建,将这些过程迁移到可显示调用的工厂函数,减少了全局化。配置类中的对象可以直接通过from_object方法导入。
- 蓝本:预定义路由的操作,可以将另外定义的路由及视图函数的文件如view,装载入蓝本文件中。再将蓝本在工厂函数create_app中注册,这样通过create_app,就将预定义的路由经由蓝本,和程序实例app对象联系到一起了。
实例项目的问题
-
一般的项目使用virtualvenv即一个虚拟的环境副本较好,不影响其他或者本地的设置。需要拓展的库和包也都安装在虚拟环境下
-
在项目中,虚拟环境下每次安装了新的库后,使用
pip freeze > requirement.txt写入;进行项目迁移后,可以重新在虚拟环境下pip install -r requirement.txt一键安装所有依赖 -
使用manage(Flask-Scripts)创建关于app执行的命令行操作对象——有些扩展在app实例对象生产后才会初始化,若直接执行命令行界面,就没有上下文对象了
-
Flask中model中的一个对象实例,其实就是表中的一行记录
-
可以使用 dir() 内置函数来查看一个 Query 对象提供的方法列表
dir(db.session.query(User));一条读取语句的链式操作都是一个 first() 或 all() 函数结束的. 它们会终止链式调用并返回结果. -
Models数据库提供两种查询方式,一种是使用对象名.query进行查询(BaseQuery Object),另一种是db.session.query查询。例如分页pagination这个就只能使用前者进行查询。
User.query.paginate(1,10) # 查询第 1 页,且 1 页显示 10 条内容
相比较而言,基本查询first()\all()返回的是models的对象或其对象列表,而pagination返回一个对象,这些对象还可以进行其他操作,如页码、页数、包含的对象等 -
update中就如使用原生 SQL 指令来更新记录一样, 如果没有指定要更新具体的哪一条记录的话, 会将该字段所在列的所有记录值一同更新, 所以切记使用过滤条件来定位到具体需要更新的记录
-
在多对多的关系中,关联关系会使用另一个新表来表示,在某一关系模型中使用Secondary属性来描述。这个关联关系表一般直接使用Metadata的对象来定义(db.Table)。一般这个关联关系需要在发生关联的两个表之前定义。管理关系的表会由数据库自动处理。