全段时间说写,一直也没有写,开学遥遥无期,赶紧充充电!
一文读懂目标检测:R-CNN、Fast R-CNN、Faster R-CNN、YOLO、SSD
目标检测算法总结
1、传统视觉:Cascade + HOG/DPM + Haar/SVM以及上述方法的诸多改进、优化;
2、候选区域/框 + 深度学习分类:通过提取候选区域,并对相应区域进行以深度学习方法为主的分类的方案,如:
R-CNN(Selective Search + CNN + SVM)
SPP-net(ROI Pooling)
Fast R-CNN(Selective Search + CNN + ROI)
Faster R-CNN(RPN + CNN + ROI)
R-FCN
等系列方法;
3、基于深度学习的回归方法:YOLO/SSD/DenseBox 等方法;以及最近出现的结合RNN算法的RRC detection;结合DPM
DeformableCNN等
原文很好的总结了常用算法的优缺点,及步骤,现在搬运一下:
RCNN
1.在图像中确定约1000-2000个候选框 (使用选择性搜索Selective Search)
2.每个候选框内图像块缩放至相同大小,并输入到CNN内进行特征提取
3.对候选框中提取出的特征,使用分类器判别是否属于一个特定类
4.对于属于某一类别的候选框,用回归器进一步调整其位置
Fast R-CNN
1.在图像中确定约1000-2000个候选框 (使用选择性搜索)
2.对整张图片输进CNN,得到feature map
3.找到每个候选框在feature map上的映射patch,将此patch作为每个候选框的卷积特征输入到SPP layer和之后的层
4.对候选框中提取出的特征,使用分类器判别是否属于一个特定类
5.对于属于某一类别的候选框,用回归器进一步调整其位置
Faster R-CNN
1.对整张图片输进CNN,得到feature map
2.卷积特征输入到RPN,得到候选框的特征信息
3.对候选框中提取出的特征,使用分类器判别是否属于一个特定类
4.对于属于某一类别的候选框,用回归器进一步调整其位置
由此可见,速度的提升主要集中在两方面,一个是如何选取候选框,另一个是何时对候选框进行计算。Fast R-CNN相对于CNN提升的地方在于,CNN提前选好几千个候选框,一一进入CNN计算,速度较慢;而Fast R-CNN则是先选框,然后整张图进行CNN计算,在feature map中映射出候选框,进行回归判定。Faster R-CNN相对于Fast R-CNN进步的地方,在于当图片输入到RPN中后才得到候选框的特征信息,纵观三个网络,候选框的提取时间原来越靠后,是为了保证整张图只进行一次CNN特征提取就好,大大节省了时间。
速度提升了,那么准确度呢?所有的网络到最后计算的回归都是在全连接层进行的,那么就限制了输入网络的大小,必须resize成同一规格,前面的提取的各种大大小小的提取框,resize成同一规格的,失真还是很严重的。
SPP-NET的出现,解决了这个问题。
SPP-NET全称,Spatial Pyramid Pooling(空间金字塔池化),最后一个卷积层后,接入了金字塔池化层,保证传到下一层全连接层的输入固定,而非在输入图像一开始就进行resize。速度提升一百倍的基础上,解决了输入需要resize造成失真的问题。Fast R-CNN 就借鉴了这种结构,最后一个卷积层后加了一个ROI pooling layer,损失函数使用了多任务损失函数(multi-task loss),将边框回归Bounding Box Regression直接加入到CNN网络中训练,这样使得精度有所提升。Faster R-CNN的进步在于引入Region Proposal Network(RPN)替代Selective Search,同时引入anchor box应对目标形状的变化问题。
Faster R-CNN详解###
conv layers以及feature maps不需要过多介绍,直接上干货。
RPN
参考博客
通俗来讲,就是在前一步得到了特征图,到了这一步,先进行3 * 3 * 256 * 256的卷积层(可能是为了扩大感受野)得到了得到11 * 11 * 256的输出特征图。然后设定了3种尺寸和三种比例的物体框,开始在特征图上滑动,足以圈出整个物体。这样要比在原图上……毫无目的画框框快速的多。
后面待更……
详解Faster R-CNN
1 RPN网络
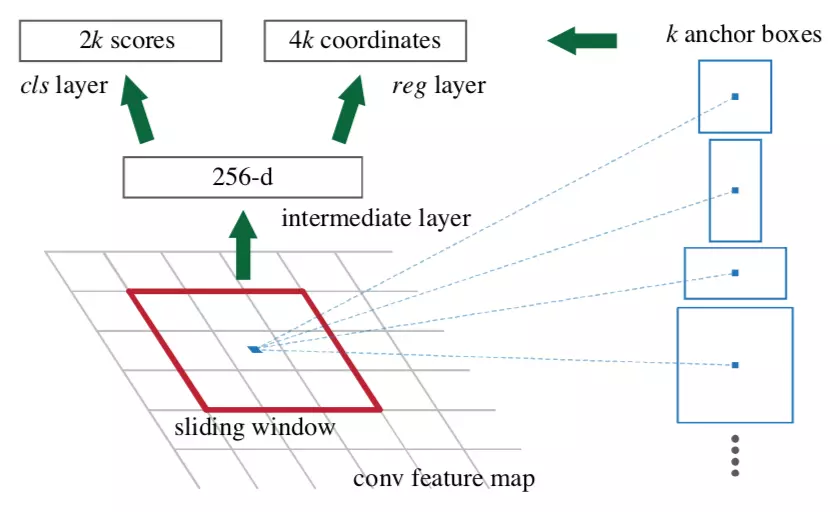
原文中RPN网络为CNN后面接一个3* 3 的卷积层,再接两个 1* 1的卷积层(原文称这两个卷积层的关系为sibling),其中一个是用来给softmax层进行分类,另一个用于给候选区域精确定位。
2 Anchor
Feature map中每个点上有k个anchor(原文如上k=9),而每个anchor要分foreground和background。
下面这张图一目了然。
3 RPN训练
RPN训练中对于正样本文章中给出两种定义。第一,与ground truth box有最大的IoU的anchors作为正样本;第二,与ground truth box的IoU大于0.7的作为正样本。文中采取的是第一种方式。文中定义的负样本为与ground truth box的IoU小于0.3的样本。
4 RPN网络与Fast R-CNN网络的权值共享
先训练RPN,然后使用得到的候选区域训练Fast R-CNN,之后再使用得到的Fast R-CNN中的CNN去初始化RPN的CNN再次训练RPN(这里不更新CNN,仅更新RPN特有的层),最后再次训练Fast R-CNN(这里不更新CNN,仅更新Fast R-CNN特有的层)。
——————————————————————————————待更新,代码详解
