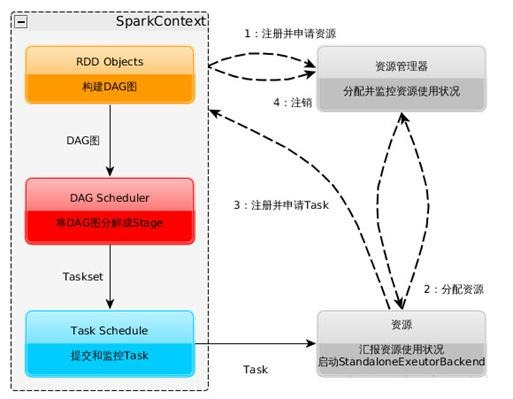
1.当一个application提交时候,首先重建一个sparkcontext,向资源管理器申请executor资源(executor的memery and core 数量),Executor根据心跳发送到资源管理器上;
2.driver会为其根据rdd的依赖(宽依赖:rdd操作需要shuffle,窄依赖:rdd操作不需要shuffle)构建最短的有向无环图,即是(DAGscheduler;
3.拿到DAGscheduler之后,只是逻辑运行结构图,根据DAG 生成stage,由stage里的task分发给taskscheduler, 各个资源节点向sparkcontext申请task,由taskshceduler分发给executor task执行 同时sparkcontext将源码分发给各个executor,如果中途task执行失败,则根据改task是否有shuffle操作判断,如果有则根据DAGshcduler去寻找依赖重头执行,如果没有依赖,则有taskscheduler执行;
4.等待task执行完成任务,释放资源;
思考:分发task时候有可能会造成一个task执行快,一个task慢的情况,这样分发不均匀有什么调整的方法?
答:这样的情况一般发生在数据不均匀的情况,数据不均匀的情况在大数据中出现的情况很多(比如说rowkey的不均匀,导致region过大,hive数据不均匀导致最后一个reduce执行过慢等等)

通常有三种解决方案:
1.业务优化 (根据实际情况给出);
2.程序优化 (比如说某个sql需要count(distinct id)的时候,这个时候会导致所有的数据都是集中到一个parrttion中去,这个时候的效率可想而至,我们可以通过先group by id 将数据做一次map reduce,之后在做一次count,这样的会效率快很多;
3.数据优化 (实际没操作过:我们知道所有的数据都是key 值对的,我们可以将所有的数据的key值增加一个hash值,将所有的数据均匀打散,然后先内部做一次MR聚合计算,减少数据量,之后再去掉key值上的hash,这样的数据量减少之后在做mr,这样数据分布均衡且计算量会少很多);