一、Spark 是什么
Spark 是基于内存计算的框架。
二、Spark 产生的背景
Spark 产生的原因主要是为了解决 Hadoop 的缺点,这里有一个时间线可以引出 Spark 的诞生。
1、Hadoop 1.x——2011年
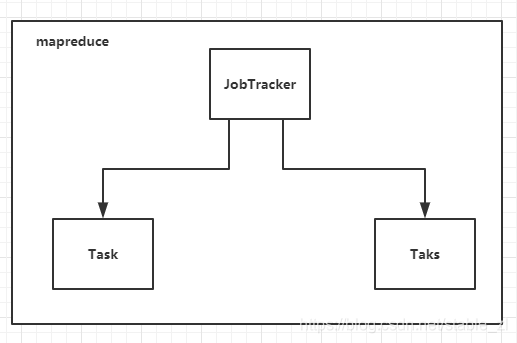
(Hadoop 1.x 架构)
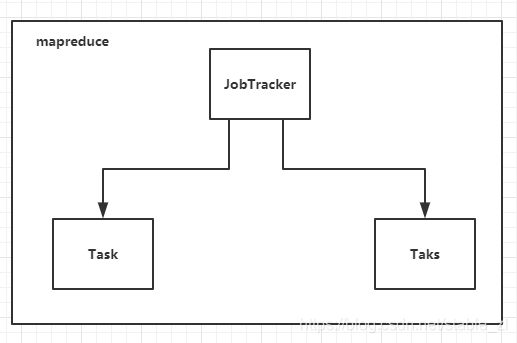
( Hadoop 1.x 的 mapreduce 架构)
Hadoop1.x 于 2011 年正式发布,此时用的人很多,但是在一段时间后,人们发现了 Hadoop 1.x 存在的问题(主要就是 mapreduce 存在问题):
1、mapreduce 是基于数据集的计算:每次都从磁盘上读取文件,然后进行计算,最后写入磁盘,一个任务就关闭。这看起来没有什么问题,但是随着需要,我们需要处理的实时数据、流数据、图数据越来越多,频繁读取磁盘的 mapreuduce 显然速度不够快,因此我们想要引入一种新的计算方法来解决这个问题。但是—— (请看2)
2、在 Hadoop 1.x 的时候,mapreduce 不仅仅负责计算,还负责资源和任务的调度,资源调度和计算紧紧地耦合在了一起,而我们如果想要仅仅改变计算框架显然是不可能的,没有资源调度来分配资源怎么计算呢?
2、在Hadoop 1.x 的时候,Mapreduce 中有一个进程叫作 JobTracker,JobTracker 即负责资源调度,又负责任务调度,而 JobTracker 手下有个进程叫作 TaskTracker,该进程负责计算,这里的 JobTracker 所负担的任务太重了,紧密耦合。
人们不能忍受此时 Hadoop 1.x 的问题,便诞生了 spark。
2、Spark 的诞生——2013年 6 月
Spark 的诞生就是为了解决上面提到的 mapreduce 的问题,为了解决慢的问题它采取了基于内存计算的策略,并且支持了迭代式计算;为了解决耦合性的问题,Spark 将资源调度和任务调度相分离:
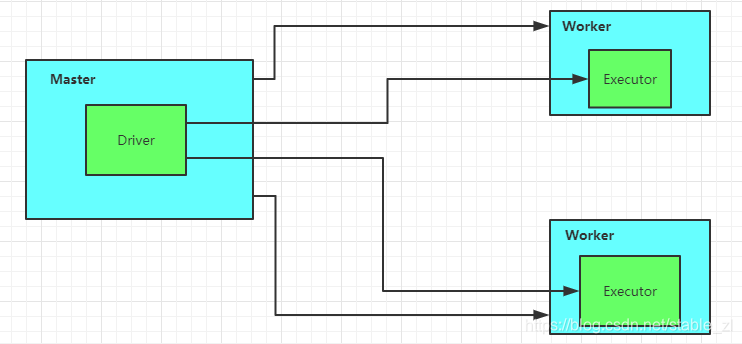
(Spark 架构)
解释图中的元素:
Master:负责资源调度
Application Master:负责任务调度,Driver 通过某种机制来和 Master 进行通信,Driver 并不是 Master 的一部分,Master 仅仅是负责资源调度的,因为在 Spark 诞生的时候,还没有 YARN,所以它用的是自己的资源调度器,名叫 Master,在 YARN 之后,Driver 便可以连接到 YARN 的 ResouceManager 从而代替 Master。
Worker:负责计算,并且进行该台节点上的资源调度
Executor:负责执行计算
可以从图中看到:与 Worker 直接相连的是 Master,与 Executor 直接相连的是 Driver
所以可以看到,Spark 架构中最重要的两个概念就是 Driver 和 Executor,因为只有它两是不可替代的。
3、Hadoop 2.x——2013年11月
在 Hadoop 2.x 中,引入了 YARN,正是 YARN,才拯救了 Hadoop,YARN 把资源调度、任务调度与计算相分离。
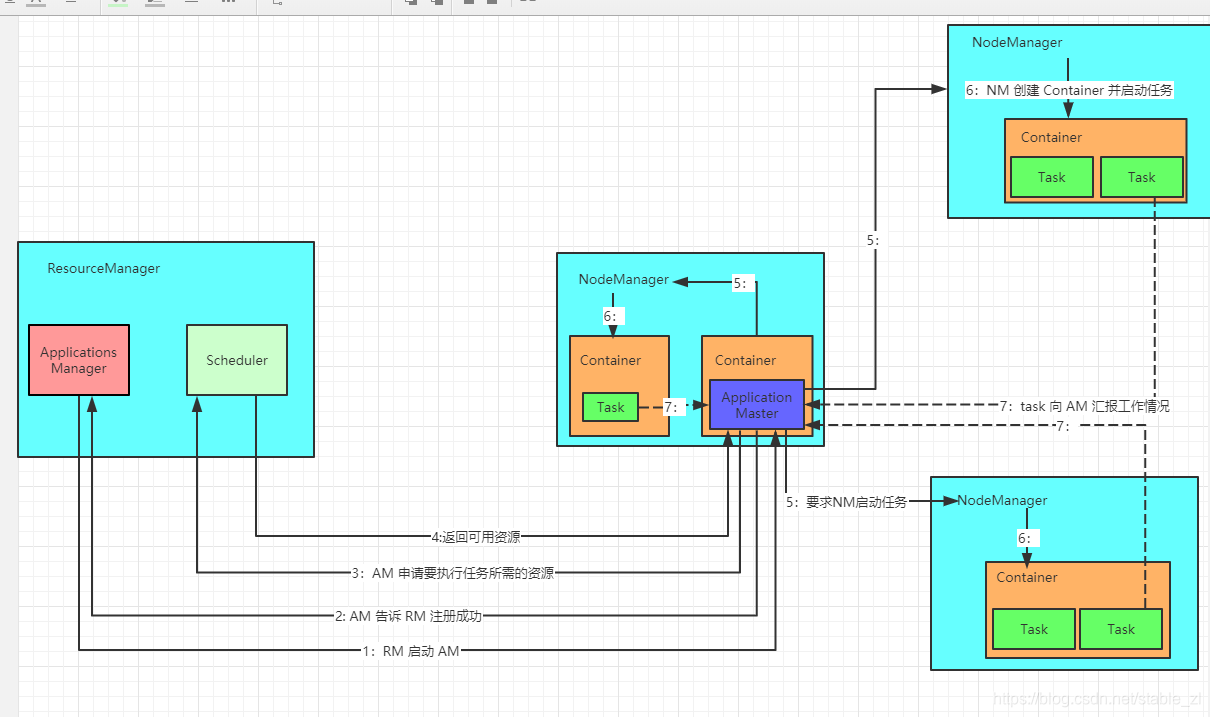
图中一共有 2 大块元素,一块是 ResourceManager,一块是 NodeManager 。
ResourceManager: 可以看到,ResourceManager 是负责资源的管理与调度,再加上一个启动 ApplicationMaster,注意:这里的调度是纯粹的资源调度,不涉及任务调度,任务调度应该是在 AM 中完成的。
**NodeManager:**NodeManager 是每个节点上的资源和任务管理器,在 NodeManager 上面完成计算功能。
**ApplicationMaster:**负责向 RM 申请资源,启动、监控任务。当用户向 ResourceManager 提交任务后,RM 会首先找到可用的 NM,在其中分配一个 Container,在其中启动 AM,AM不是固定的,而是根据用户的提交变化,如果提交 MR 任务,那么 AM 就是关于 MR 的,如果是 Spark ,那么 AM 就是关于 Spark 的。
Container: Container 是资源的抽象,就像我们 Windows 系统中的虚拟机,虚拟机可以利用 Windows 的资源,然后再这个资源上可以启动 Linux 或者 Mac,同样,在 YARN 中的Container 中,我们也可以启动 MapReduce 或者 Spark 的任务。
要理解这些元素的作用是什么,主要还是得理解整个框架的工作流程。
综上,YARN 做到了解耦合,我们随便上来一个计算框架,只要把 AM 和 Task 换成自己的东西,就可以在 Hadoop 2.0 上运行。是真的强大!
三、Spark 在 YARN 上的工作流程
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2kXok9CM-1583725096217)(C:\Users\dell\AppData\Roaming\Typora\typora-user-images\image-20200307124214254.png)]
通过上述总结,我们看到 Spark alone 运行模式 与 YARN 的结构非常类似,Spark alone 中的 Driver 就相当于 AM,Master 就相当于 RM,Worker 就相当于 NM,Executor 就相当于 Task。
我们如果想要在 Hadoop 2.0 中运行 Spark,只需要把 Spark 的 Driver 放到 YARN 的 Application 处,把 Spark 的 Executor 放到 YARN 的 Task 便可。
三、Spark 中重要的两个组件
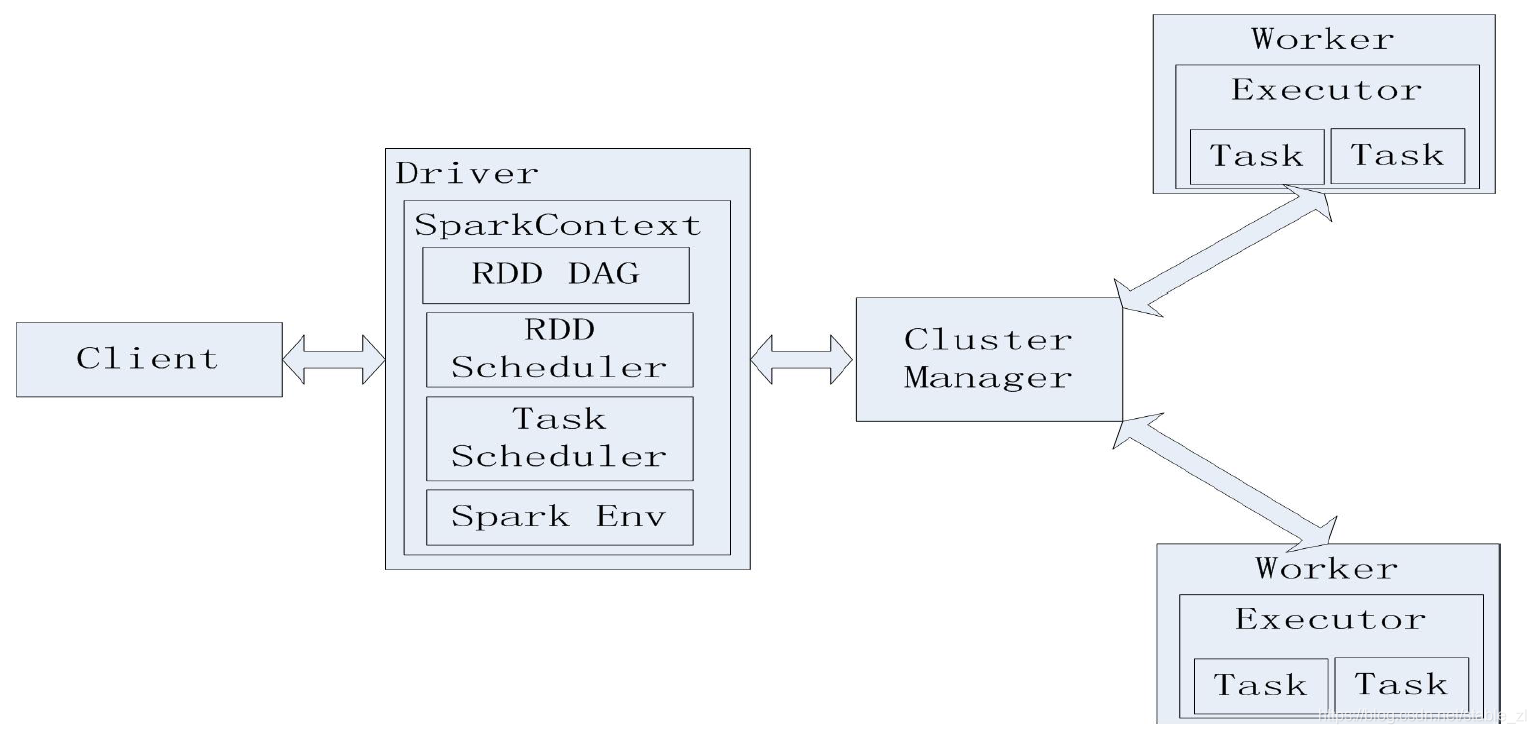
在诞生了 YARN 之后,Spark 的资源调度器就可以是 ResourceManager 或者 Master 了,而 Worker 就可以是 Spark 中的 Worker 或者是 YARN 中的 NodeManager 了,这两个都是可替换的,因此,Spark 中最核心的两个组件就是 Driver 和 Executor 了。
1、Driver
Driver 就是开发程序中 main 方法的进程。
2、Executor
Executor 是一个工作进程,负责在 Spark 作业中运行任务,任务间相互独立。
四、Spark 部署模式
1、local
spark 任务在本地运行,local[k] 就代表启动 k 个线程来运行,local[*] 就代表启动全部线程来运行。
2、standalone
独立地运行在一个集群上。
3、yarn
运行在资源管理系统上,如 yarn 和 mesos。
运行,local[*] 就代表启动全部线程来运行。
2、standalone
独立地运行在一个集群上。
3、yarn
运行在资源管理系统上,如 yarn 和 mesos。
