版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/zhq9695/article/details/82956729
目录
学习完吴恩达老师机器学习课程的无监督学习,简单的做个笔记。文中部分描述属于个人消化后的理解,仅供参考。
如果这篇文章对你有一点小小的帮助,请给个关注喔~我会非常开心的~
0. 前言
- 监督学习(supervised learning):样本数据已经标记了所属的类别
- 无监督学习(unsupervised learning):样本数据未标记所属的类别
无监督学习通常采用聚类算法(clustering algorithm)对其分门别类,通常成为“簇”(cluster)。常见的聚类算法有 K-means(K-均值),初始作如下定义:
--- 簇的数量
--- 第
个样本向量
--- 第
--- 第
个簇中心的向量
--- 第
1. K-means的算法流程
K-means主要由簇分配和移动聚类中心两部分组成,是一种迭代的算法,2个簇的流程可如下描述:
- 簇分配:随机选择两个样本点,作为簇中心,将每个样本划分至距离更近的簇中心,作为它所属的簇
- 移动聚类中心:分别计算两个簇中,属于这个簇所有样本的均值,将这个取平均后的向量位置作为当前簇新的中心
- 重新进行簇分配、移动聚类中心,不断迭代,直到聚类中心不再改变
用伪代码,可作如下描述:

2. 代价函数(优化目标函数)
优化目标函数(代价函数)如下定义:
很明显,代价函数表示的是,所有样本与各自属于的簇中心的欧式距离的平方和再取平均。
注:K-means聚类算法有时候会陷入局部最优解。
如下图所示(图源:吴恩达机器学习),就是一个局部最优的例子:
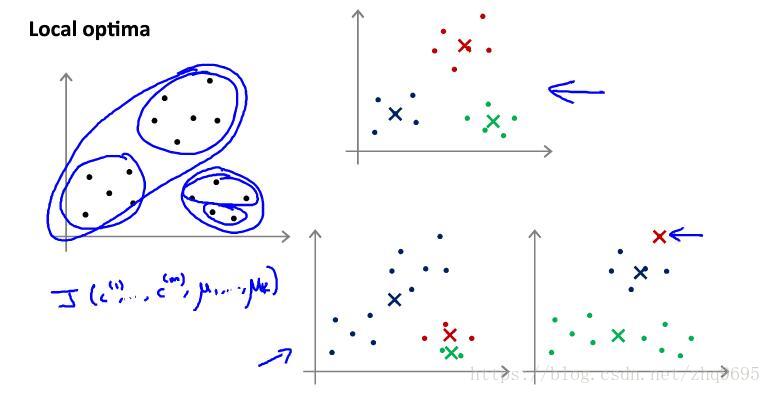
为避免局部最优,可在上述伪代码外再嵌套一层循环,每次确定簇中心之后计算代价函数,多次迭代之后,选择代价函数最小的一组结果。此方法适合 值较小(小于10)的情况。
3. K 的选择
簇的数量的选择,通常有两种方法,均要求 :
- 人工选择:根据需求或者已知的知识,进行人工选择簇的数量
- 肘部法则:如下图所示(图源:吴恩达机器学习),尝试不同的
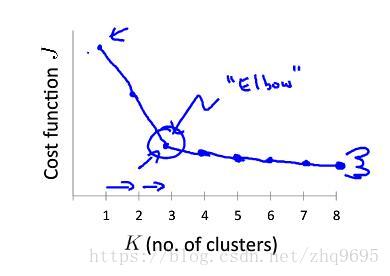
如果这篇文章对你有一点小小的帮助,请给个关注喔~我会非常开心的~