1 算法说明
1.1 基本原理
1967 年MacQueen 首次提出了K 均值聚类算法(K-means算法)。到目前为止用于科学和工业应用的诸多聚类算法中一种极有影响的技术。K-means是最常用的聚类算法之一,能有效地处理规模较大和高维的数据集合,能对大型数据集进行高效分类,把数据分成几组,按照定义的测量标准,同组内数据与其他组数据相比具有较强的相似性,这就叫聚簇。它是聚类方法中一个基本的划分方法,常常采用误差平方和准则函数作为聚类准则函数。k-means算法(C均值算法)是通过迭代寻找C个聚类的一种划分方案,使得用这C个均值来代表相应各类样本时所得到的总体误差最小。
误差平方和度量了C个聚类中心代表C个样本自己所产生的总的误差平方,对于不同的聚类
一般是不相同的。使
极小的聚类是误差平方和准则下的最优结果,这种类型的聚类通常称为最小方差划分。
误差平方和无法用解析的方法最小化,只能采用迭代的方法,通过不断的调整样本的类归属来获得最优解。
K-means算法的效率比较高;缺点是只能处理数值型数据,不能处理分类数据,对例外数据非常敏感,不能处理非凸面形状的聚簇。
K-means算法接受输入量k:然后将n个数据对象划分为k个聚类以便使得所获得的聚类满足:同一聚类中的对象相似度较高;而不同聚类中的对象相似度较小。聚类相似度是利用各聚类中对象的均值所获得一个“中心对象”(引力中心)来进行计算的。
1.2 算法基本步骤
在最开始,需要对样本进行初始划分。初始化分采用“密度”法选择代表点,然后根据选择的代表点对样本进行分类。选择代表点时,通过样本间的欧氏距离,以样本点为球心做球,计算样本球内的样本个数即为样本点密度。然后根据选择的代表点和样本点间的距离来进行初始划分。
最后,通过迭代的方式计算误差平方和的增加量和减小量,不断减小误差,一直到
不再发生变化为止,则找到了最小的误差平方和,此时的聚类划分为最优划分方法。
第一步:选K个初始聚类中心,,其中括号内的序号为寻找聚类中心的迭代运算的次序号。聚类中心的向量值可任意设定,例如可选开始的K个模式样本的向量值作为初始聚类中心。
第二步:逐个将需分类的模式样本按最小距离准则分配给K个聚类中心中的某一个
。对所有的i≠j,j=1,2,…,K ,则有
,
,其中k为迭代运算的次序号,第一次迭代k=1,
表示第j个聚类,其聚类中心为
。
第三步:计算各个聚类中心的新的向量值,j=1,2,…,K,求各聚类域中所包含样本的均值向量:
其中为第个聚类域
中所包含的样本个数。以均值向量作为新的聚类中心,可使如下聚类准则函数
最小:
在这一步中要分别计算K个聚类中的样本均值向量,所以称之为K-均值算法。
第四步:若,j=1,2,…,K,则返回第二步,将模式样本逐个重新分类,重复迭代运算;若
,j=1,2,…,K,则算法收敛,计算结束。具体如下图所示:
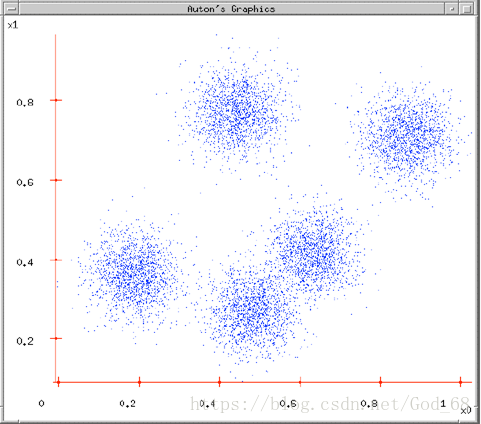
图1. 原始数据
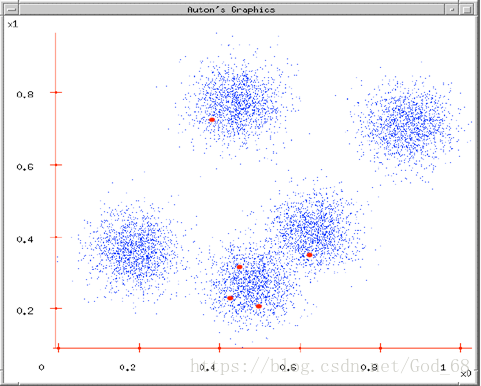
图2. 随机的选择K(K = 5)个初始中心点
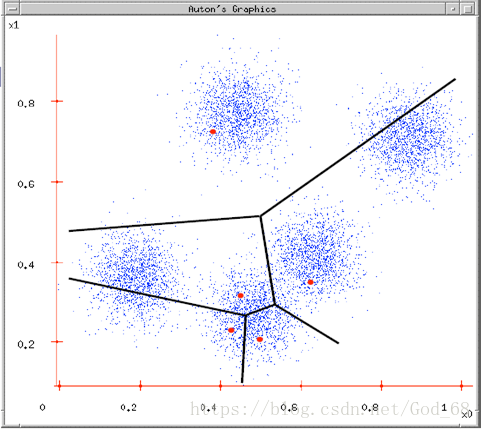
图3. 将各个样本点归到距离自己最近的初始中心点的那一类
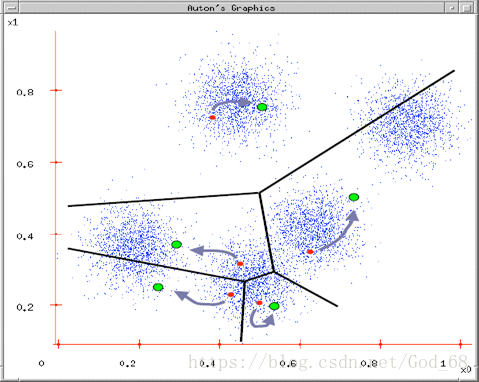
图4. 重新计算新的中心点直到误差最小
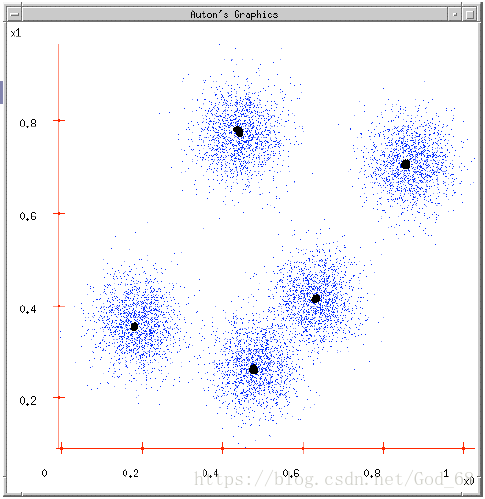
图5. 最终的聚类结果
1.3 算法优缺点
迄今为止,很多聚类任务都选择该经典算法,K-means算法虽然有能对大型数据集进行高效分类的优点,但K-means算法必须事先确定类的数目k,而实际应用过程中,k 值是很难确定的,并且初始聚类中心选择得不恰当会使算法迭代次数增加,并在获得一个局部最优值时终止,因此在实际应用中有一定的局限性。
优点:算法的特点是:第一,能根据较少的已知聚类样本的类别对树进行剪枝确定部分样本的分类;第二,为克服少量样本聚类的不准确性,该算法本身具有优化迭代功能,在已经求得的聚类上再次进行迭代修正剪枝确定部分样本的聚类,优化了初始监督学习样本分类不合理的地方;第三,由于只是针对部分小样本可以降低总的聚类时间复杂度。
缺点:① 在 K-means 算法中 K 是事先给定的,这个 K 值的选定是非常难以估计的。很多时候,事先并不知道给定的数据集应该分成多少个类别才最合适。这也是 K-means 算法的一个不足。
② 在 K-means 算法中,首先需要根据初始聚类中心来确定一个初始划分,然后对初始划分进行优化。这个初始聚类中心的选择对聚类结果有较大的影响,一旦初始值选择的不好,可能无法得到有效的聚类结果,这也成为 K-means算法的一个主要问题。
③ 从 K-means 算法可以看出,该算法需要不断地进行样本分类调整,不断地计算调整后的新的聚类中心,因此当数据量非常大时,算法的时间开销是非常大的。所以需要对算法的时间复杂度进行分析、改进,提高算法应用范围。
2 算法应用
基于k-means聚类方法设计分类器,对随机产生的150个样本数据进行分类设计。用密度法选择代表点,并计算每一代表点的密度对数据进行原始分类;计算每一类样本均值和误差平方和聚类准则;进行迭代运算并求得最优解。
1、随机生成150个样本数据,计算样本大小,设置聚类个数K,并定义中间变量,进行初始化。
2、从150个样本中随机的抽取K个样本作为初始的聚类中心。
3、根据代表点将样本划分为K个聚类。
根据其他样本与代表点间的距离,将样本点划归为与之最近的代表点所代表的类别。
4、计算每一聚类的样本均值和
。
若是第
聚类
中的样本数目,
是这些样本的均值。根据聚类样本均值的公式
计算样本均值。把中的各样本
与均值
间的误差平方和对所有类相加后为:
是误差平方和聚类准则。
5、随机选择样本并对其进行调整。
使用随机函数,选择随机的样本,如果选择的随机样本对应的类中样本数目不为1,则计算随机样本的均方误差的减小量和增加量,否则重新选择样本进行计算。随机样本的均方误差的减小量和增加量
。
考察中的最小者
,如果
,则把
从
移到
中去。
6、进行迭代运算。
对样本移位后,重新计算均值和误差平方和,进行迭代运算。N次运算之后不再改变则计算完成,本实验中取N = 100。然后将决策结果显示到图像中,并显示最后的聚类中心。
3 实验结果
本实验随机生成150个样本,通过K-Means聚类方法可将数据聚集为多类。具体结果如下图所示(每类样本由一个颜色标识,黑点表示最终的聚类中心):
(1)随机产生的150个样本如下图所示:

(2)设置K = 2,其聚类结果如下:

(3)设置K= 5,其聚类结果如下:

(4) 设置K= 10,其聚类结果如下:

(5)设置K= 15,其聚类结果如下:

附录
(1)《模式分类》机械工业出版社、中信出版社,Richard O.Duda, Peter E.Hart, David G.Stork著,李宏东、姚天祥译,第10章,10.4.3 K-均值聚类,423-425