每个样本的异常分数称为局部异常因子。它测量给定样本相对于其邻居的密度的局部偏差。它是局部的,异常得分取决于物体相对于周围邻域的隔离程度。更确切地说,局部性由k近邻给出,其距离用于估计局部密度。通过将样本的局部密度与其邻居的局部密度进行比较,可以识别密度明显低于其邻居的样本。这些被认为是异常值。
局部异常因子(LOF)算法是一种无监督的异常检测方法,它计算给定数据点相对于其邻居的局部密度偏差。它将密度大大低于邻居的样本视为异常值。此示例显示如何使用LOF进行异常值检测,这是scikit-learn中此估计器的默认用例。请注意,当LOF用于离群值检测时,它没有预测,decision_function和score_samples方法。
有关异常值检测和新颖性检测之间的区别以及如何使用LOF进行异常性检测的详细信息,请参阅 用户指南:
类方法
class sklearn.neighbors.LocalOutlierFactor(n_neighbors=20, algorithm=’auto’, leaf_size=30, metric=’minkowski’, p=2, metric_params=None, contamination=’legacy’, novelty=False, n_jobs=None)
| 参数: | n_neighbors : int, optional (default=20) 默认情况下 algorithm : {‘auto’, ‘ball_tree’, ‘kd_tree’, ‘brute’}, optional 用于计算最近邻居的算法: 注意:在稀疏输入上拟合将使用强力来覆盖此参数的设置。
leaf_size : int, optional (default=30) 叶子大小传递给 metric : string or callable, default ‘minkowski’ 用于距离计算的度量。可以使用scikit-learn或scipy.spatial.distance中的任何指标。 如果'预先计算',则训练输入X应该是距离矩阵。 如果metric是可调用函数,则在每对实例(行)上调用它,并记录结果值。callable应该将两个数组作为输入,并返回一个指示它们之间距离的值。这适用于Scipy的度量标准,但效率低于将度量标准名称作为字符串传递。 指标的有效值为:
有关这些指标的详细信息,请参阅scipy.spatial.distance的文档:http://docs.scipy.org/doc/scipy/reference/spatial.distance.html
p : integer, optional (default=2) 来自的Minkowski度量的参数 metric_params : dict, optional (default=None) 度量函数的其他关键字参数。 contamination : float in (0., 0.5), optional (default=0.1) 数据集的污染量,即数据集中异常值的比例。拟合时,用于定义决策函数的阈值。如果是“自动”,则确定决策函数阈值,如原始论文中所示。 在版本0.20中更改:默认值
novelty : boolean, default False 默认情况下,LocalOutlierFactor仅用于异常值检测(novelty = False)。如果您想使用LocalOutlierFactor进行新奇检测,请将Novelty设置为True。在这种情况下,请注意您应该只对新的看不见的数据使用predict,decision_function和score_samples,而不是在训练集上。 n_jobs : int or None, optional (default=None) 为邻居搜索运行的并行作业数。 |
|---|---|
| 属性: | negative_outlier_factor_ : numpy array, shape (n_samples,) 训练样本的LOF相反。越高越正常。内点往往具有接近1( 样本的局部异常因子(LOF)捕获其假定的“异常程度”。它是样本的局部可达性密度与其k近邻的密度之比的平均值。
n_neighbors_ : integer 用于 offset_ : float 偏移量用于从原始分数中获取二进制标签。具有小于offset_的negative_outlier_factor的观察 被检测为异常。偏移设置为-1.5(内部得分约为-1),除非提供的污染参数不同于“auto”。在这种情况下,偏移量的定义方式是我们在训练中获得预期的异常值数量。 |
参考
[1] Breunig,MM,Kriegel,HP,Ng,RT,&Sander,J。(2000,May)。LOF:识别基于密度的局部异常值。在ACM sigmod记录中。
方法
fit(X[, y]) |
使用X作为训练数据拟合模型。 |
get_params([deep]) |
获取此估算工具的参数。 |
kneighbors([X, n_neighbors, return_distance]) |
找到一个点的K邻居。 |
kneighbors_graph([X, n_neighbors, mode]) |
计算X中点的k-邻居的(加权)图 |
set_params(**params) |
设置此估算器的参数。 |
案例
案例1
在下面的示例中,我们从表示数据集的数组构造一个NeighborsClassifier类,并询问谁是[1,1,1]的最近点
samples = [[0., 0., 0.], [0., .5, 0.], [1., 1., .5]]
from sklearn.neighbors import NearestNeighbors
neigh = NearestNeighbors(n_neighbors=1)
neigh.fit(samples)
NearestNeighbors(algorithm='auto', leaf_size=30)
print(neigh.kneighbors([[1., 1., 1.]])) (array([[0.5]]), array([[2]], dtype=int64))
如您所见,它返回[[0.5]]和[[2]],这意味着该元素位于距离0.5处并且是样本的第三个元素(索引从0开始)。您还可以查询多个点:
X = [[0., 1., 0.], [1., 0., 1.]]
neigh.kneighbors(X, return_distance=False) array([[1],
[2]], dtype=int64)
案例2
计算X中点的k-邻居的(加权)图,使用kneighbors_graph方法。
X = [[0], [3], [1]]
from sklearn.neighbors import NearestNeighbors
neigh = NearestNeighbors(n_neighbors=2)
neigh.fit(X)
NearestNeighbors(algorithm='auto', leaf_size=30)
A = neigh.kneighbors_graph(X)
A.toarray()array([[1., 0., 1.],
[0., 1., 1.],
[1., 0., 1.]])
案例3
import numpy as np
import matplotlib.pyplot as plt
from sklearn.neighbors import LocalOutlierFactor
# 正常显示中文
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['SimHei']
np.random.seed(42)
# 生成训练数据
X_inliers = 0.3 * np.random.randn(100, 2)
X_inliers = np.r_[X_inliers + 2, X_inliers - 2]
# 生成一些异常值
X_outliers = np.random.uniform(low=-4, high=4, size=(20, 2))
X = np.r_[X_inliers, X_outliers]
n_outliers = len(X_outliers)
ground_truth = np.ones(len(X), dtype=int)
ground_truth[-n_outliers:] = -1
# 符合异常检测(默认)的模型
clf = LocalOutlierFactor(n_neighbors=20, contamination=0.1)
# 使用fit预测值来计算训练样本的预测标签
# (当LOF用于异常检测时,估计量没有预测,
# 决策函数和计分样本方法)。
y_pred = clf.fit_predict(X)
n_errors = (y_pred != ground_truth).sum()
X_scores = clf.negative_outlier_factor_
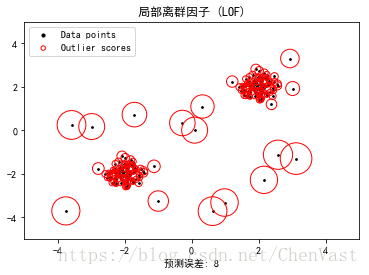
plt.title("局部离群因子 (LOF)")
plt.scatter(X[:, 0], X[:, 1], color='k', s=3., label='Data points')
# plot circles with radius proportional to the outlier scores
radius = (X_scores.max() - X_scores) / (X_scores.max() - X_scores.min())
plt.scatter(X[:, 0], X[:, 1], s=1000 * radius, edgecolors='r',
facecolors='none', label='Outlier scores')
plt.axis('tight')
plt.xlim((-5, 5))
plt.ylim((-5, 5))
plt.xlabel("预测误差: %d" % (n_errors))
legend = plt.legend(loc='upper left')
legend.legendHandles[0]._sizes = [10]
legend.legendHandles[1]._sizes = [20]
plt.show()结果
参考原文: