目录
本文所用数据可在博客资源中获取。
一、前言
“拍照赚钱”作为移动互联网下的一种自助式服务模式,用户在 APP 上领取拍照任务并执行,从而获得相应报酬。从数据中可观察到任务定价和任务执行情况,最终定价按位置范围可分为四类:北纬约 23 °至 23.08 °,东经约 113.1 °至 113.2 °;北纬约 23.1 °至 23.2 °,东经约 113.21 °至 113.5 °;北纬约 113.8 °至 114.1 °,东经约 22.5 °至 22.8 °;北纬约 22.8 °至 23. 9 °,东经约 113.5 °至 113. 8 °。这四个范围分别对应佛山市、清远市、深圳市和东莞市。任务未完成可能与地理位置有关,纬度越高,任务未完成可能性比完成可能性越大。 此外,店铺拒访等原因也会造成任务未完成。现在请你对地理位置进行异常检测,观察哪些数据可能为异常数据。
二、任务准备
(1)库准备:
import excelReader
import gspread
import xlrd
import pandas as pd
from sklearn import metrics
import numpy as np(2)数据准备:
data = pd.read_excel("D:\\dataspace\\已结束项目任务数据.xls")
data=pd.DataFrame(data)
print(data)
pd.set_option('display.max_rows',None)
pd.set_option('display.max_columns', None)
print("维度:",data.shape)
print("信息展示\n",data.info)
print("数据类型\n",data.dtypes)
x=data.iloc[:,[1,2]].values
#切分经度纬度两列数据作为异常检测的目标数据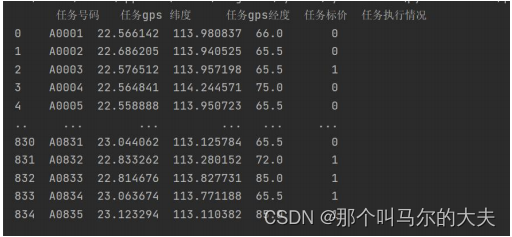
通过展示数据,可发现数据属性列为任务号码、任务gps纬度、任务gps经度、任务标价、任务执行情况。其中任务经纬度、任务标价为数值型数据,任务执行情况可作为数值型标称属性数据。
数据准备好后,接下来将对数据中的异常值进行检测,进行异常检测的方法有多种,本文介绍DBSCAN聚类方法。
三、采用DBSCAN聚类进行异常检测
(1)首先引入DBSCAN的算法原理。
DBSCAN是基于密度空间的聚类算法,在机器学习和数据挖掘领域有广泛的应用,其聚类原理通俗点讲是每个簇类的密度高于该簇类周围的密度,噪声的密度小于任一簇类的密度。
采用该算法进行异常检测时,将数据集划分为核心点,边界点和噪声点,并按照一定的连接规则组成簇类。
其次定义三个概念,密度直达、密度可达、密度相连。
密度直达:选取一个点A为核心点,假如另一个点B在该点邻域内,则说明由A核心点到邻域内的点B密度直达。
密度可达:如果一个点A在另一个点B邻域内,且两者都为核心点,则A的邻域点由B密度可达。
密度相连:若A,B均为非核心点,且A,B处于同一个簇类中,则称A与B密度相连。
只要任意两个样本点是密度直达或密度可达的关系,那么该两个样本点归为同一簇类,上图的样本点ABCE为同一簇类。因此,DBSCAN算法从数据集D中随机选择一个核心点作为“种子”,由该种子出发确定相应的聚类簇,当遍历完所有核心点时,算法结束。
注:在编写代码时,可使用DBSCAN函数来构建模型,其中eps表示邻域半径。设置参数时考虑eps 的取值是否过大覆盖了特征的所有区域。
(2)调整eps参数,确定最优的min_samples的范围。
from sklearn.cluster import DBSCAN
score1list = []
for i in range(1,11):
model_dbs = DBSCAN(eps=0.2, min_samples=i)
labels1 = model_dbs.fit_predict(x)
score1 = metrics.silhouette_score(x, labels1)
score1list.append(score1)
print('轮廓系数\n',score1list)
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['KaiTi']
plt.plot(range(1,11),score1list,'o-')
plt.title('silhouette score')
plt.xlabel('min_samples',size=12)
plt.ylabel('轮廓系数',size=12)
plt.show()
这里引入轮廓系数的概念,轮廓系数(Silhouette Coefficient Index)是一种聚类评估指标,用于评估数据聚类的效果。其取值范围在[-1, 1]之间,指标值越大表示聚类结果聚类效果越好。
由图可知,根据轮廓系数的值可判断,当最小样本数到2时,轮廓系数达到最大,此时的最小样本数2为最优样本数。
(3)设定最优参数,绘制DBSCAN分类法散点图。
model_dbs = DBSCAN(eps=0.2,min_samples=2)
Ypred2 = model_dbs.fit_predict(x)
print(Ypred2)
Y1=pd.DataFrame(Ypred2).value_counts().sort_index()
print(Y1)
import matplotlib.pyplot as plt
plt.title("DBSCAN 分类法散点图")
plt.scatter(x[Ypred2==0,0],x[Ypred2==0,-1],c="blue",label='0')
plt.scatter(x[Ypred2==-1,0],x[Ypred2==-1,-1],c='yellow',label='1')
plt.legend()
plt.show() 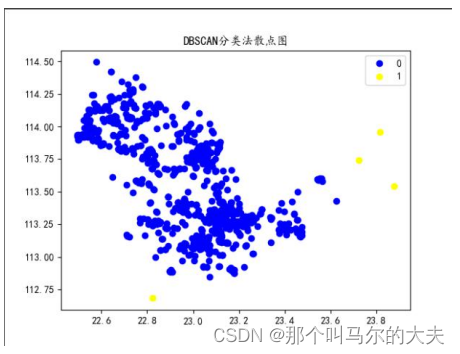
通过散点图可看出, 任务完成数比未完成数要多,说明该数据异常值很少。
(4) 统计异常点检测结果:
print('DBscan 异常点检测结果',data[Ypred2==-1])
print(data[Ypred2==-1]["任务执行情况"].value_counts())根据 DBscan 异常点的检测结果,可得出以下结果:

由异常数据的经纬度可知,任务未完成情况与经纬度的特殊性有关。