局部异常因子算法-Local Outlier Factor(LOF)
在数据挖掘方面,经常需要在做特征工程和模型训练之前对数据进行清洗,剔除无效数据和异常数据。异常检测也是数据挖掘的一个方向,用于反作弊、伪基站、金融诈骗等领域。
异常检测方法,针对不同的数据形式,有不同的实现方法。常用的有基于分布的方法,在上、下α分位点之外的值认为是异常值(例如图1),对于属性值常用此类方法。基于距离的方法,适用于二维或高维坐标体系内异常点的判别,例如二维平面坐标或经纬度空间坐标下异常点识别,可用此类方法。

这次要介绍一下一种基于密度的异常检测算法,局部异常因子LOF算法(Local Outlier Factor)
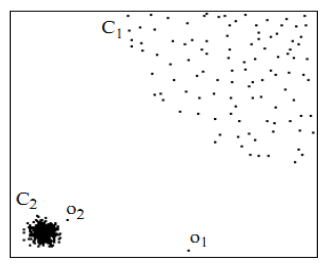
用视觉直观的感受一下,如图2,对于C1集合的点,整体间距,密度,分散情况较为均匀一致,可以认为是同一簇;对于C2集合的点,同样可认为是一簇。o1、o2点相对孤立,可以认为是异常点或离散点。现在的问题是,如何实现算法的通用性,可以满足C1和C2这种密度分散情况迥异的集合的异常点识别。LOF可以实现我们的目标。
下面介绍LOF算法的相关定义:
1) d(p,o):两点p和o之间的距离。
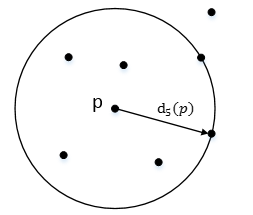
2) k-distance:第k距离
对于点p的第k距离dk(p)定义如下:
dk(p)=d(p,o),并且满足:
a) 在集合中至少有不包括p在内的k个点o' ∈ C{x ≠ p}, 满足d(p,o') ≤ d(p,o) 。
b) 在集合中最多有不包括p在内的k−1个点o' ∈ C{x ≠ p},满足d(p,o') < d(p,o)。
如下图,离p第5远的点在以p为圆心,d5(p)为半径的
3) k-distance neighborhood of p:第k距离邻域
点p的第k距离邻域Nk(p),就是p的第k距离即以内的所有点,包括第k距离。
因此p的第k邻域点的个数 |Nk(p)| ≥ k。
4) reach-distance:可达距离
点o到点p的第k可达距离定义为:reach−distancek(p,o) = max{dk(o), d(p,o)}
也就是,点o到点p的第k可达距离,至少是o的第k距离,或者为o、p间的真实距离。
5) local reachability density:局部可达密度
点p的局部可达密度表示为:
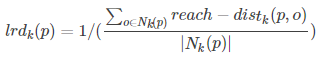
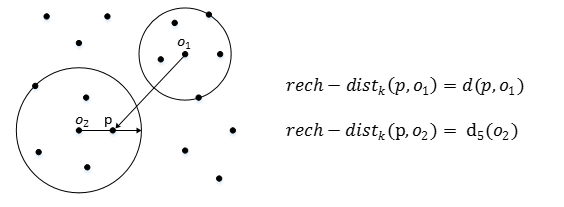
表示点p的第k邻域内的点到p的平均可达距离的倒数。
6) local outlier factor:局部离群因子
点p的局部离群因子表示为:
表示点p的邻域点Nk(p)的局部可达密度与点p的局部可达密度之比的平均数。 
local outlier factor越接近1,说明p的其邻域点密度差不多,p可能和邻域同属一簇;
local outlier factor越小于1,说明p的密度高于其邻域点密度,p为密集点;
local outlier factor越大于1,说明p的密度小于其邻域点密度,p越可能是异常点。
因为LOF对密度的是通过点的第k邻域来计算,而不是全局计算,因此得名为“局部”异常因子,这样,对于图1的两种数据集C1和C2,LOF完全可以正确处理,而不会因为数据密度分散情况不同而错误的将正常点判定为异常点。
个人理解:
现在再回过头来看一下lof的思想,主要是通过比较每个点p和其邻域点的密度来判断该点是否为异常点,如果点p的密度越低,越可能被认定是异常点。至于密度,是通过点之间的距离来计算的,点之间距离越远,密度越低,距离越近,密度越高,完全符合我们的理解。而且,因为lof对密度的是通过点的第k邻域来计算,而不是全局计算,因此得名为“局部”异常因子,这样,对于图1的两种数据集C1和C2,lof完全可以正确处理,而不会因为数据密度分散情况不同而错误的将正常点判定为异常点。
算法思想已经讲完了,现在进入干货环节,亮代码。
给一个python实现的lof算法:
https://github.com/damjankuznar/pylof
再给一下我fork之后的代码:
https://github.com/wangyibo360/pylof
有区别:
上面提到了,对于重复点局部可达密度可能会变为无限大的问题,我改的代码对这个问题做了处理,如果有重复点方面的场景,可以用我的代码,源代码这块有bug没有fix,而且好像代码主人无踪影了,提的pull也没人管。。。
另一方面:可以直接调用sklearn中的包实现该算法:
在中等高维数据集上执行异常值检测的另一种有效方法是使用局部异常因子(Local Outlier Factor ,LOF)算法。
1、算法思想
LOF通过计算一个数值score来反映一个样本的异常程度。这个数值的大致意思是:一个样本点周围的样本点所处位置的平均密度比上该样本点所在位置的密度。比值越大于1,则该点所在位置的密度越小于其周围样本所在位置的密度,这个点就越有可能是异常点。关于密度等理论概念,详见下面第二部分。
2、LOF的具体理论
详见上面的介绍
3、LocalOutlierFactor主要参数和函数介绍
class sklearn.neighbors.LocalOutlierFactor(n_neighbors=20, algorithm=’auto’, leaf_size=30, metric=’minkowski’, p=2, metric_params=None, contamination=0.1, n_jobs=1)
1)主要参数
n_neighbors :
设置k,default=20
contamination :
设置样本中异常点的比例,default=0.1
2)主要属性:
negative_outlier_factor_ : numpy array, shape (n_samples,)
和LOF相反的值,值越小,越有可能是异常点。(注:上面提到LOF的值越接近1,越可能是正常样本,LOF的值越大于1,则越可能是异常样本)。这里就正好反一下。
3)主要函数:
fit_predict(X)
X : array-like, shape (n_samples, n_features
返回一个数组,-1表示异常点,1表示正常点。
4、LOF实例(sklearn)
# !/usr/bin/python
# -*- coding:utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
from sklearn.neighbors import LocalOutlierFactor
from scipy import stats
# 构造训练样本
n_samples = 200 #样本总数
outliers_fraction = 0.25 #异常样本比例
n_inliers = int((1. - outliers_fraction) * n_samples)
n_outliers = int(outliers_fraction * n_samples)
rng = np.random.RandomState(42)
X = 0.3 * rng.randn(n_inliers // 2, 2)
X_train = np.r_[X + 2, X - 2] #正常样本
X_train = np.r_[X_train, np.random.uniform(low=-6, high=6, size=(n_outliers, 2))] #正常样本加上异常样本
# fit the model
clf = LocalOutlierFactor(n_neighbors=35, contamination=outliers_fraction)
y_pred = clf.fit_predict(X_train)
scores_pred = clf.negative_outlier_factor_
threshold = stats.scoreatpercentile(scores_pred, 100 * outliers_fraction) # 根据异常样本比例,得到阈值,用于绘图
# plot the level sets of the decision function
xx, yy = np.meshgrid(np.linspace(-7, 7, 50), np.linspace(-7, 7, 50))
Z = clf._decision_function(np.c_[xx.ravel(), yy.ravel()]) # 类似scores_pred的值,值越小越有可能是异常点
Z = Z.reshape(xx.shape)
plt.title("Local Outlier Factor (LOF)")
# plt.contourf(xx, yy, Z, cmap=plt.cm.Blues_r)
plt.contourf(xx, yy, Z, levels=np.linspace(Z.min(), threshold, 7), cmap=plt.cm.Blues_r) # 绘制异常点区域,值从最小的到阈值的那部分
a = plt.contour(xx, yy, Z, levels=[threshold], linewidths=2, colors='red') # 绘制异常点区域和正常点区域的边界
plt.contourf(xx, yy, Z, levels=[threshold, Z.max()], colors='palevioletred') # 绘制正常点区域,值从阈值到最大的那部分
b = plt.scatter(X_train[:-n_outliers, 0], X_train[:-n_outliers, 1], c='white',
s=20, edgecolor='k')
c = plt.scatter(X_train[-n_outliers:, 0], X_train[-n_outliers:, 1], c='black',
s=20, edgecolor='k')
plt.axis('tight')
plt.xlim((-7, 7))
plt.ylim((-7, 7))
plt.legend([a.collections[0], b, c],
['learned decision function', 'true inliers', 'true outliers'],
loc="upper left")
plt.show() 
顺便截一张sklearn官网是上面的相关函数:

参考文献:
http://scikit-learn.org/stable/modules/generated/sklearn.neighbors.LocalOutlierFactor.html#sklearn.neighbors.LocalOutlierFactor
http://scikit-learn.org/stable/auto_examples/neighbors/plot_lof.html
http://scikit-learn.org/stable/auto_examples/covariance/plot_outlier_detection.html
https://blog.csdn.net/wangyibo0201/article/details/51705966