这篇文章的主要解决的是当输入的图片的尺寸不是既定的 , 采用各种对图片放缩的时候会影响网络的学习. 比如下图, 只裁剪了一部分, 或者放缩的时候发生了几何的形变:

那么为什么会要求输入的大小相同呢, 很大一个原因就是最高层的FC的输入的尺寸必须要相同. 文章就是从这里下手的.
Spatial pyramid pooling: 指的是对于卷积学得的N个feature maps进行多次池化操作, 并且池化核的大小逐渐增大, 这会导致着池化的输出逐渐减小,(像金字塔形状一样) 将这些池化后的输出合并起来, 作为FC的输入, 以此来解决FC要求的输入必须要一致的问题.
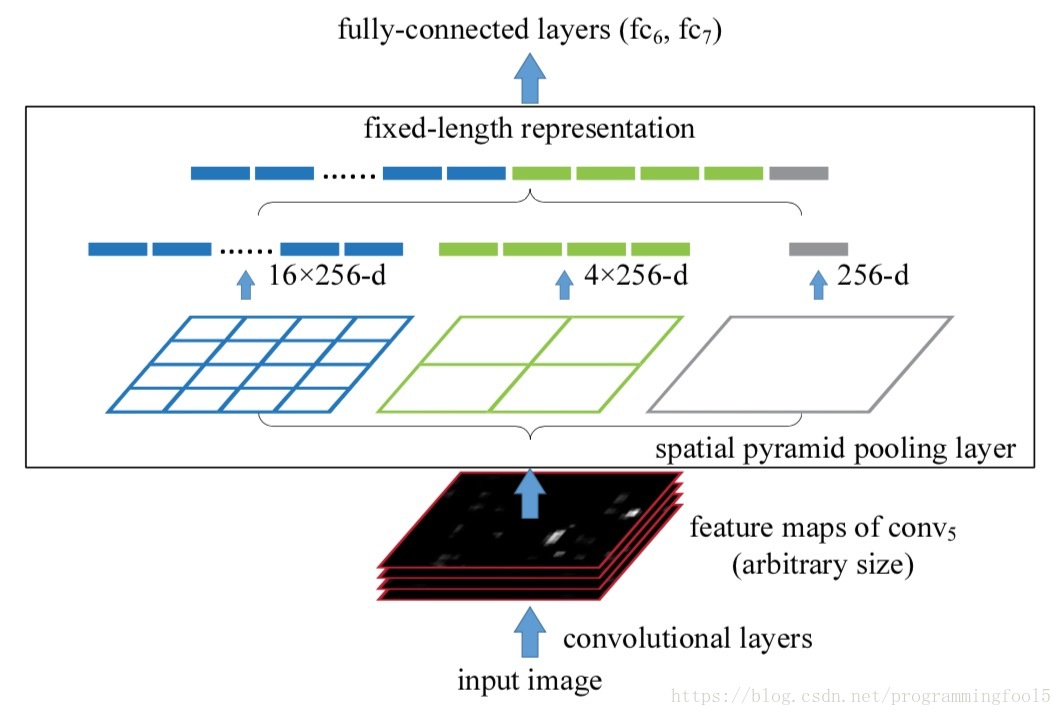
SPP层原理如下所所示,假定CNN层得到的特征图大小为 (比如 ,随输入图片大小而变化),设定的金字塔尺度为 bins(对于不同大小图片是固定的),那么SPP层采用一种滑动窗口池化,窗口大小 ,步为 ,采用max pooling,本质上将特征图均分为 个子区域,然后对各个子区域max pooling,这样不论输入图片大小,经过SPP层之后得到是固定大小的特征。一般设置多个金字塔级别,文中使用了 , 和 三个尺度。每个金字塔都得一个特征,将它们连接在一起送入后面的全连接层即可,这样就解决了变大小图片输入的问题了。
这是其一, 其二, 作者反复强调了 Multi-level pooling has been shown to be robust to object deformations,It is worth noticing that the gain of multi-level pooling is not simply due to more parameters; rather, it is because the multi-level pooling is robust to the variance in object deformations and spatial layout. 即 这种机制下会对目标的形变问题有很好的健壮性. 在我的理解下, 因为采用了这种多级的pooling操作, 所以在一定程度上, 在训练的过程中让网络学习到了在小范围和大范围下的形变下, 仍然能采样到标志性的特征.
再说下对我比较有启发的点, 下面的这个feature maps的图对我理解整个基于CNN的视觉问题有很大的帮助:
回忆一下Stanford的课程:

这是卷积核的可视化, 第一个图, 其中有64个卷积核, 有3个信道, 代表3种颜色, 每个卷积核的大小是 . 通过可视化卷积核, 我们可以发现, (在对卷积核的权重训练完后)每个卷积核正在找的东西, 不同的形状, 不同的颜色, 不同的纹理等等. 这也代表这些卷积核是从不同的角度去寻找他想去寻找的东西: 在预测阶段, 卷积核通过与图像上滑动的卷积来做内积, 我理解的这就是一种投影, 投影计算的过程就是在匹配的过程, 内积大, 那么更加匹配. 那么就会获得最大的激活.

基于此, 我们来看下kaiming大神的这个feature maps的可视化图片, 对于滤波器#175它更倾向于去识别类似于车窗一样的方框一样的东西, 我们看到他的feature maps 上面基于图像位置上面的矩形都获得了或多或少的激活. 对于滤波器#55 它更容易识别圆的物体, 那么注意观察图上的轮胎和人头都获得了比较大的激活.
为什么花了如此多的笔墨来说特征图的可视化呢?
是为了说明These feature maps generated by deep convolutional layers are analogous to the feature maps in traditional methods and can be pooled by bag-of-words or spatial pyramids
(文中的传统方法我还没看, 先写写自己的一点理解和看法)
集合文中多次提出来的Bag-of-Words来理解, 卷积后的每个feature map都侧重于一个视角或者说是一个方面的学习, 类似于每个词, 那么用multi-level pooling去抓取这些词让他们聚集在一起, 这样的想法就比较合乎逻辑了, 同时multi 保证了从不同的局部范围去抓取. 避免盲人摸象或者摸蚂蚁的情况发生.
具体针对Detection来说:
相比于R-CNN不必把2k个候选区域都去卷积了, 一张图片只需要做一次卷积, 候选区域的特征提取直接在最后一层的feature maps作提取.
两部分训练以及标签的设置基本与R-CNN一致:
1.fine-tuning:只训练全连接层, 一个全连接层 , 一个有N+1个分支的分类层
- initialization: Gaussian σ=0.01
- learning rate : 1e-4, 1e-5
- 正例 : [0.5,1]
- 反例(背景) : [01,0.5)
2.SVM:
- 正例: 正标签的样本中与该类对应的
- 反例: 与该类对应的候选框IOU <0.3 以及 候选框与其他类的IOU>0.7的
其他:
Model Combination for Detection: 作者用不同的初始化方法预训练了一个相同架构的模型, 两个模型的输出作非极大值抑制, 结果显示有提升. 但是fine-tuning一个模型的高层,再去做combination, 没有提升. 所以是卷积层特征探测器的不同导致的性能的提升. 相当于做了一个集成.

不同的数据集下, 模型的表现会有不同, 不是说深层多参数的模型一定会表现的好
It is worth noticing that the gain of multi-level pooling is not simply due to more parameters; rather, it is because the multi-level pooling is robust to the variance in object deformations and spatial layout [15].