归并排序(Merge Sort)
1、基本思想:
将两个的有序数列合并成一个有序数列,我们称之为"归并"。
归并排序(Merge Sort)就是利用归并思想对数列进行排序。根据具体的实现,归并排序包括"从上往下"和"从下往上"2种方式。
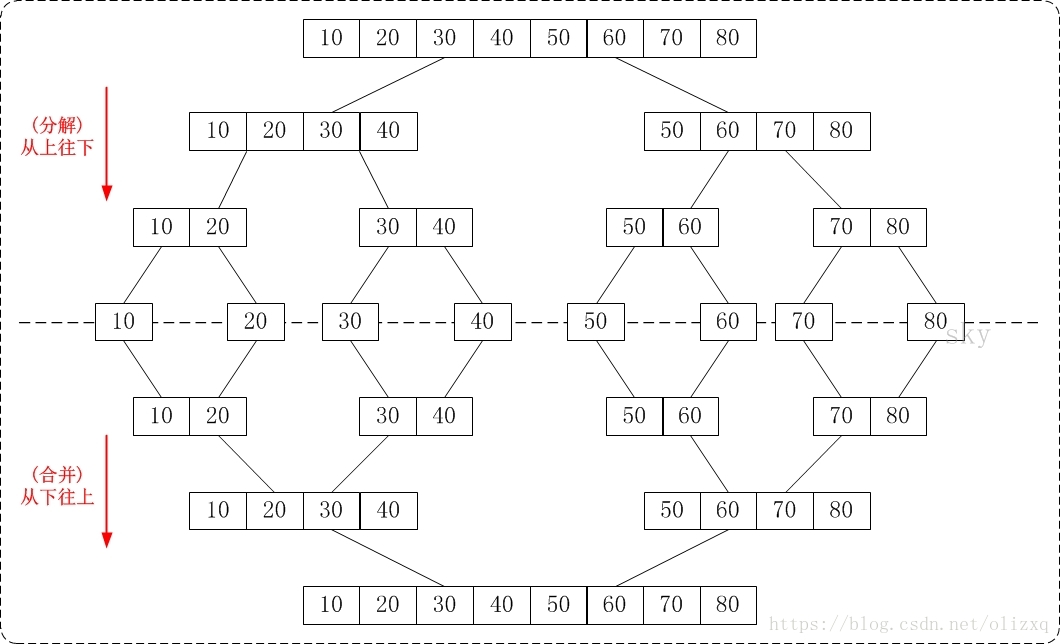
(1)从下往上的归并排序:将待排序的数列分成若干个长度为1的子数列,然后将这些数列两两合并;得到若干个长度为2的有序数列,再将这些数列两两合并;得到若干个长度为4的有序数列,再将它们两两合并;直接合并成一个数列为止。这样就得到了我们想要的排序结果。(参考下面的图片)
(2)从上往下的归并排序:它与"从下往上"在排序上是反方向的。它基本包括3步:
① 分解 – 将当前区间一分为二,即求分裂点 mid = (low + high)/2;
② 求解 – 递归地对两个子区间a[low…mid] 和 a[mid+1…high]进行归并排序。递归的终结条件是子区间长度为1。
③ 合并 – 将已排序的两个子区间a[low…mid]和 a[mid+1…high]归并为一个有序的区间a[low…high]。
下面的图片很清晰的反映了"从下往上"和"从上往下"的归并排序的区别。
2、排序过程:
从上往下的归并排序采用了递归的方式实现。它的原理非常简单,如下图:
通过"从上往下的归并排序"来对数组{80,30,60,40,20,10,50,70}进行排序时:
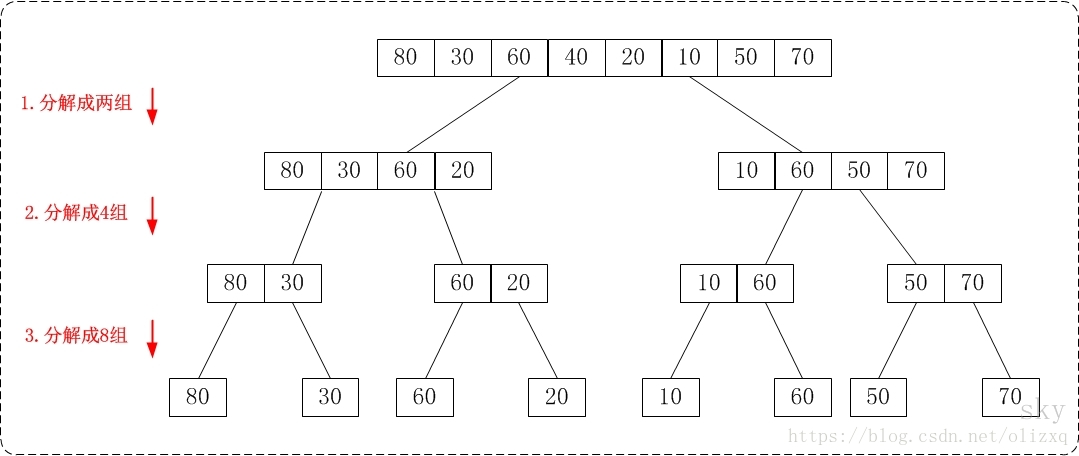
- 将数组{80,30,60,40,20,10,50,70}看作由两个有序的子数组{80,30,60,40}和{20,10,50,70}组成。对两个有序子树组进行排序即可。
- 将子数组{80,30,60,40}看作由两个有序的子数组{80,30}和{60,40}组成。
将子数组{20,10,50,70}看作由两个有序的子数组{20,10}和{50,70}组成。 - 将子数组{80,30}看作由两个有序的子数组{80}和{30}组成。
将子数组{60,40}看作由两个有序的子数组{60}和{40}组成。
将子数组{20,10}看作由两个有序的子数组{20}和{10}组成。
将子数组{50,70}看作由两个有序的子数组{50}和{70}组成。
从下往上的归并排序的思想正好与"从下往上的归并排序"相反。如下图:
通过"从下往上的归并排序"来对数组{80,30,60,40,20,10,50,70}进行排序时:
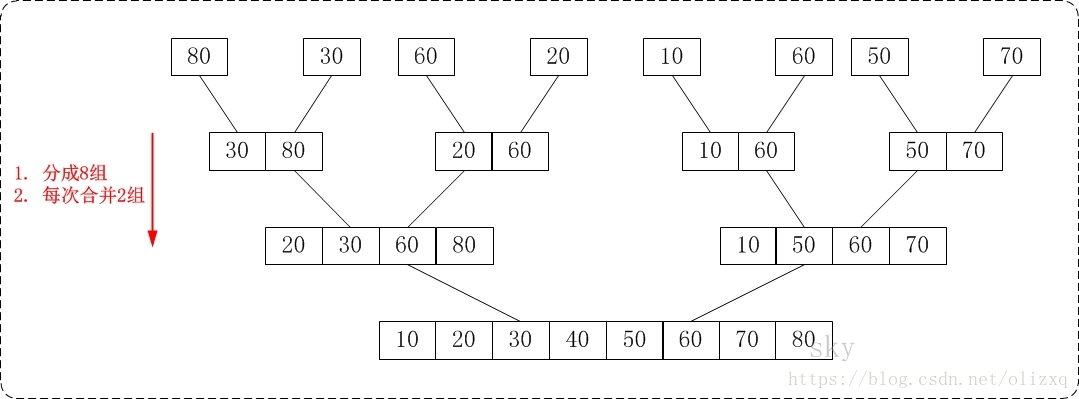
- 将数组{80,30,60,40,20,10,50,70}看作由8个有序的子数组{80},{30},{60},{40},{20},{10},{50}和{70}组成。
- 将这8个有序的子数列两两合并。得到4个有序的子树列{30,80},{40,60},{10,20}和{50,70}。
- 将这4个有序的子数列两两合并。得到2个有序的子树列{30,40,60,80}和{10,20,50,70}。
- 将这2个有序的子数列两两合并。得到1个有序的子树列{10,20,30,40,50,60,70,80}。
3、时间复杂度:
归并排序的时间复杂度是
。
假设被排序的数列中有N个数。遍历一趟的时间复杂度是O(N),需要遍历多少次呢?
归并排序的形式就是一棵二叉树,它需要遍历的次数就是二叉树的深度,而根据完全二叉树可以得出它的时间复杂度是
。
4、稳定性:
归并排序是稳定的算法,它满足稳定算法的定义。
5、应用:
归并排序的两个应用:
1、数据库:基于排序的关系操作中,利用归并排序将表数据划分为n个有序子表,然后将数据逐片读入内存中,执行具体关系操作后输出。数据库中物理计划的选择方法可选用动态规划、分支定界、…
2、MapReduce:在Hadoop MapReduce的shuffle阶段,Map后的数据首先对key hash后再以reduce task数据取模(即Partition),key/value对以及Partition的结果都会被写入内存缓冲区,内存缓冲区将满会将数据溢写到磁盘,溢写时会对key做排序,发生多次溢写,最后将多个溢写文件归并到一起,经网络传输进入相应的TaskTracker,Reduce端执行合并操作。
6、算法实现(python3)
"""
归并排序:
基本思想:
将两个的有序数列合并成一个有序数列,我们称之为"归并"。
① 分解 -- 将当前区间一分为二,即求分裂点 mid = (low + high)/2;
② 求解 -- 递归地对两个子区间a[low...mid] 和 a[mid+1...high]进行归并排序。递归的终结条件是子区间长度为1。
③ 合并 -- 将已排序的两个子区间a[low...mid]和 a[mid+1...high]归并为一个有序的区间a[low...high]。
时间复杂度:O(nlog(n))
参数说明:
data -- 包含两个有序区间的数组
start -- 第1个有序区间的起始地址。
mid -- 第1个有序区间的结束地址。也是第2个有序区间的起始地址。
end -- 第2个有序区间的结束地址。
"""
# 合并排序过程
def merge(data, start, mid, end):
tmp = []
i = start
j = mid + 1
while i <= mid and j <= end: # O(n)
if data[i] <= data[j]:
tmp.append(data[i])
i += 1
else:
tmp.append(data[j])
j += 1
for ii in range (i, mid + 1):
tmp.append(data[ii])
for jj in range(j, end + 1):
tmp.append(data[jj])
for k in range(len(tmp)):
data[start + k] = tmp[k]
# 归并过程
def mergeSort(data, start, end):
if data == None or start >= end:
return
mid = (end + start) // 2 # O(log(n))
mergeSort(data, start, mid)
mergeSort(data, mid + 1, end)
merge(data, start, mid, end)
if __name__ == '__main__':
data = [20, 40, 30, 10, 60, 50]
data_len = len(data)
print("before sort:", data)
mergeSort(data, 0, data_len-1)
print("after sort:", data)
运行结果:
before sort: [20, 40, 30, 10, 60, 50]
after sort: [10, 20, 30, 40, 50, 60]