网上MapReduce的Demo不少,不过学习嘛,还得一步步来。
不说废话了,直接干。
在Linux机器中,搭建了Hadoop伪集群,详见:Hadoop - 1 - 集群搭建
Hadoop学习的代码,完整项目全部上传GitHub上了,需要的同学请自取;
如果觉得还不错,麻烦点个star
https://github.com/Simba-cheng/HadoopCode
Windows操作系统 IDEA中远程调用Hadoop集群进行本地运行
下面看代码,测试数据,这里不贴出来了,去GitHub上拿,或者自己造也行。

用于输出日志
package com.server.conf;
import org.apache.log4j.ConsoleAppender;
import org.apache.log4j.Level;
import org.apache.log4j.Logger;
import org.apache.log4j.PatternLayout;
import org.apache.log4j.RollingFileAppender;
/**
* @author CYX
* @create 2018-08-30-23:38
*/
public class LoadConfig {
public static final Logger logger = Logger.getLogger(LoadConfig.class);
static {
String pattern = "%d{yyyy-MM-dd HH:mm:ss} %p %l - %m%n";
Logger rootLogger = Logger.getRootLogger();
rootLogger.setLevel(Level.INFO);
RollingFileAppender rollingFileAppender = new RollingFileAppender();
//文件数
rollingFileAppender.setMaxBackupIndex(4);
rollingFileAppender.setMaxFileSize("50MB");
rollingFileAppender.setFile("./log/logger.log");
rollingFileAppender.setEncoding("UTF-8");
rollingFileAppender.setLayout(new PatternLayout(pattern));
rollingFileAppender.activateOptions();
rootLogger.addAppender(new ConsoleAppender((new PatternLayout(pattern))));
rootLogger.addAppender(rollingFileAppender);
}
private static class SingletonHolder {
private static final LoadConfig INSTANCE = new LoadConfig();
}
public static final LoadConfig getInstance() {
return SingletonHolder.INSTANCE;
}
}
mapper
package com.server.mapreduce;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.log4j.Logger;
import java.io.IOException;
/**
* 四个泛型类型分别代表:
* KeyIn Mapper的输入数据的Key,这里是每行文字的起始位置(0,11,...)
* ValueIn Mapper的输入数据的Value,这里是每行文字
* KeyOut Mapper的输出数据的Key,这里是每行文字中的“年份”
* ValueOut Mapper的输出数据的Value,这里是每行文字中的“气温”
*
* @author CYX
* @create 2018-08-30-23:43
*/
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
public static final Logger logger = Logger.getLogger(WordCountMapper.class);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
logger.info("key : " + key + " , value : " + value);
//获取每一行数据
String line = value.toString();
//年份
String year = line.substring(0, 4);
//温度
int temperature = Integer.parseInt(line.substring(8));
context.write(new Text(year), new IntWritable(temperature));
logger.info("======" + "After Mapper:" + new Text(year) + ", " + new IntWritable(temperature));
}
}
reducer
package com.server.mapreduce;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.log4j.Logger;
import java.io.IOException;
/**
* 四个泛型类型分别代表:
* KeyIn Reducer的输入数据的Key,这里是每行文字中的“年份”
* ValueIn Reducer的输入数据的Value,这里是每行文字中的“气温”
* KeyOut Reducer的输出数据的Key,这里是不重复的“年份”
* ValueOut Reducer的输出数据的Value,这里是这一年中的“最高气温”
*
* @author CYX
* @create 2018-08-30-23:44
*/
public class WordCountReduce extends Reducer<Text, IntWritable, Text, IntWritable> {
public static final Logger logger = Logger.getLogger(WordCountReduce.class);
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int maxValue = Integer.MIN_VALUE;
StringBuffer sb = new StringBuffer();
for (IntWritable intWritable : values) {
maxValue = Math.max(maxValue, intWritable.get());
sb.append(intWritable).append(" , ");
}
logger.info("Before Reduce: " + key + ", " + sb.toString());
context.write(key, new IntWritable(maxValue));
logger.info("======" + "After Reduce: " + key + ", " + maxValue);
}
}
main
package com.server;
import com.server.conf.LoadConfig;
import com.server.mapreduce.WordCountMapper;
import com.server.mapreduce.WordCountReduce;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.LocalFileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hdfs.DistributedFileSystem;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.log4j.Logger;
/**
* @author CYX
*/
public class MapReduceAppDemo01 {
public static final Logger logger = Logger.getLogger(WordCountMapper.class);
public static void main(String[] args) throws Exception {
//windows指定hadoop目录
System.setProperty("hadoop.home.dir", "/G:\\hadoop\\hadoop-2.8.1");
LoadConfig.getInstance();
//读取文件
String wordCountIputFileHDFS = "hdfs://192.168.137.160:9000/MapReduce-Demo-01/input/wordcount.txt";
//结果输出文件-必须是不存在的文件
String wordCountOutputFileHDFS = "hdfs://192.168.137.160:9000/MapReduce-Demo-01/output/outresult01";
Configuration hadoopConfig = new Configuration();
hadoopConfig.set("fs.hdfs.impl", DistributedFileSystem.class.getName());
hadoopConfig.set("fs.file.impl", LocalFileSystem.class.getName());
Job job = new Job(hadoopConfig);
//job执行作业时输入和输出文件的路径
FileInputFormat.addInputPath(job, new Path(wordCountIputFileHDFS));
FileOutputFormat.setOutputPath(job, new Path(wordCountOutputFileHDFS));
//指定自定义的Mapper和Reducer作为两个阶段的任务处理类
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReduce.class);
//设置最后输出结果的Key和Value的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//执行job,直到完成
job.waitForCompletion(true);
logger.info("Finished");
}
}
如果你现在直接运行程序,肯定是不行的,会出错。
当你在 IDEA 远程调试 Linux Hadoop集群的之前,需要在Windows本地装一个Hadoop。
网上很多资料,这里贴上我找到的资料,不再赘述:
Win7操作系统环境搭建
Win7操作系统搭建可运行Hadoop环境,参考以下:
https://blog.csdn.net/chy2z/article/details/80484848
https://www.cnblogs.com/benfly/p/8301588.html
windows 安装hadoop 问题:
https://blog.csdn.net/qq_24125575/article/details/76186309
https://blog.csdn.net/l1028386804/article/details/51538611
Windows IDEA 远程连接Hadoop集群进行调试
http://www.ptbird.cn/intellij-idea-for-hadoop-programming.html
https://blog.csdn.net/chy2z/article/details/80484848
https://blog.csdn.net/chenguangchun1993/article/details/78130655
本地Windows环境的Hadoop安装好了之后,运行程序,会出现下面这个程序错误:
org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z
为什么会出现这个错误,网上去找,或者去我GitHub中直接拿代码。
上面全部安装、搭建、修改完成之后,就可以运行程序了。

然后去HDFS上看下结果

输出结果

ok,Windows远程调用Hadoop集群没有问题。
MapReduce打包上传Linux服务器运行
通过另一个例子,来看下如何将MapReduce程序打成Jar,上传Linux运行。
map过程:
package com.server.mapreduce;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
import java.util.StringTokenizer;
/**
* Map过程<br>
* Map过程需要继承org.apache.hadoop.mapreduce.Mapper类,并重写map方法。
*
* @author CYX
* @create 2018-09-01-12:28
*/
public class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
protected void map(Object key, Text value, Context context) throws IOException, InterruptedException {
System.out.println("map() , key:" + key + " , value : " + value);
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
reducer过程
package com.server.mapreduce;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* Reducer过程
*
* @author CYX
* @create 2018-09-01-13:16
*/
public class InSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
System.out.println("reduce() , key : " + key + " , values : " + values);
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
result.set(sum);
context.write(key, result);
}
}
main方法
package com.server;
import com.server.mapreduce.InSumReducer;
import com.server.mapreduce.TokenizerMapper;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
/**
* @author CYX
*/
public class MapReduceAppDemo02 {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage : wrodcount <in><out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(MapReduceAppDemo02.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(InSumReducer.class);
job.setReducerClass(InSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
然后,将程序打成jar包,用idea maven中的package。
然后将jar包上传至指定目录中

再声明一下,下面的操作,是基于Hadoop以及配置好环境变量的,如果还没配置最好配一下,方便一些。
服务器上新创建一个目录:
/home/yxcheng/hadoop/mr/mapreducedemo02然后将jar包丢进去。
然后我们创建测试数据:
echo "Hello World" > file-1.bcp
echo "Hello Hadoop" > file-2.bcp最后目录中有这些文件:

一个MapReduce可运行jar包、两个测试数据文件。
下面在hdfs上新建目录,并将bcp文件上传:
#查看hdfs上根节点下所有目录
hadoop fs -ls /
#创建一级目录
hadoop fs -mkdir /MapReduce-Demo-02
#创建二级目录
hadoop fs -mkdir /MapReduce-Demo-02/input
hadoop fs -mkdir /MapReduce-Demo-02/output
#将测试数据上传/MapReduce-Demo-02/input目录
#'./file-1.bcp' linux文件路径
#'/MapReduce-Demo-02/input' HDFS存储路径
hadoop fs -put ./file-1.bcp /MapReduce-Demo-02/input
hadoop fs -put ./file-2.bcp /MapReduce-Demo-02/input
#确认input目录中上传的数据
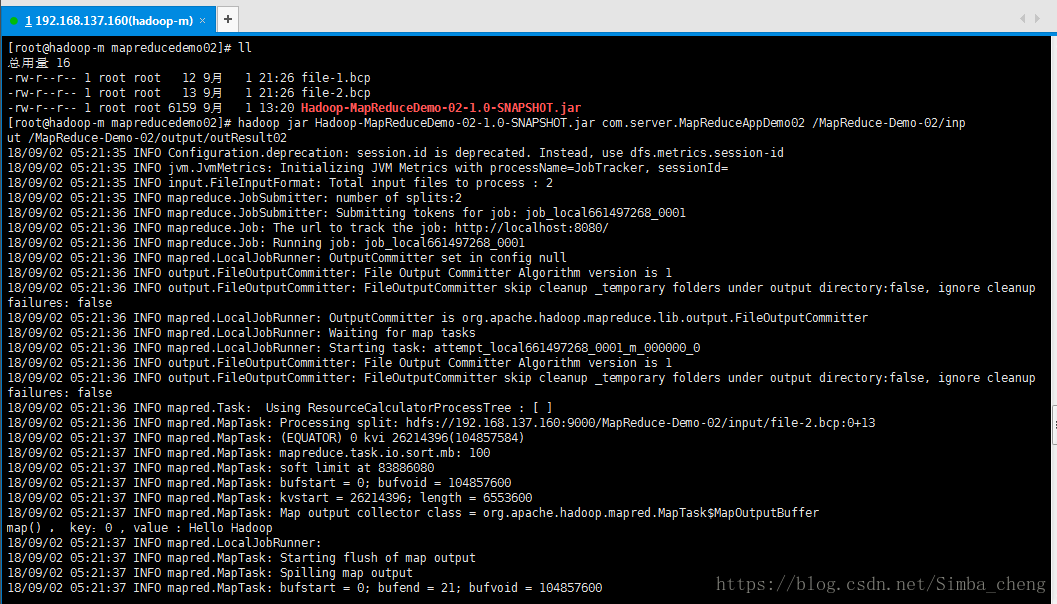
hadoop fs -ls /MapReduce-Demo-02/input上传文件结束之后,运行jar包,具体命令如下:
#hadoop运行jar命令
hadoop jar Hadoop-MapReduceDemo-02-1.0-SNAPSHOT.jar com.server.MapReduceAppDemo02 /MapReduce-Demo-02/input /MapReduce-Demo-02/output/outResult02解释下:
Hadoop-MapReduceDemo-02-1.0-SNAPSHOT.jar:你要运行jar包的名称 com.server.MapReduceAppDemo02 : 运行jar包中的主类全类名 /MapReduce-Demo-02/input:测试数据在hdfs中的目录 /MapReduce-Demo-02/output/outResult02:mapreduce运行结束之后,结果数据输出路径
运行程序:
查看hdfs中的结果数据:


完成