一、概述
在大数据应用场景里,一般可将数据计算分为离线计算和实时计算,其中离线计算就是我们通常说的批计算处理,代表技术有Hadoop MapReduce、Hive等;实时计算也被称作流计算,代表技术是Storm、Spark Streaming、Flink等。其中,Flink即Apache Flink,它是由Apache软件基金会开发的开源流处理框架,基于Apache许可证2.0开发,其核心是用Java和Scala编写的分布式流数据流引擎。Flink以数据并行和流水线方式执行任意流数据程序,Flink的流水线运行时系统可以执行批处理和流处理程序。每个Flink数据流以一个或多个源(数据输入,例如消息队列或文件系统)开始,并以一个或多个接收器(数据输出,如消息队列、文件系统或数据库等)结束。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。Flink具有Web UI,可以检查,监视和调试正在运行的应用程序。它还可以用于提交执行以执行或取消执行。

Apache Flink 功能强大,支持开发和运行多种不同种类的应用程序。它的主要特性包括:批流一体化、精密的状态管理、事件时间支持以及精确一次的状态一致性保障等。Flink 不仅可以运行在包括 YARN、 Mesos、Kubernetes 在内的多种资源管理框架上,也支持在裸机集群上独立部署。在启用高可用选项的情况下,甚至基本不存在单点失效问题。相关经验事实证明,Flink 已经可以扩展到数千核心,其状态可以达到 TB 级别,且仍能保持高吞吐、低延迟的特性。已经有很多要求严苛的流处理应用都运行在 Flink 之上。流应用需保证最少的停机时间内连续运行,因此流处理器必须提供出色的故障恢复能力,以及在运行时监控和维护应用程序的工具。Apache Flink将重点放在流处理的操作方面,它具备有效的故障恢复能力;

Flink提供了一些功能来确保应用程序保持运行并保持一致:
- 一致性检查点:Flink的故障恢复机制是通过建立在应用程序状态一致性检查点实现的,如果发生故障,将重新启动应用程序,并从最新的检查点加载其状态。结合可重置的数据源,从而可以保证一次状态一致性。
\- 高效的检查点:如果一个应用程序要维护TB量级的状态信息,那么对应用程序的状态进行检查点的开销可能是会非常昂贵。Flink可以执行异步和增量检查点,大大减少检查点对应用程序延迟SLA的影响。
\- 端到端的精确一次:Flink具有针对特定存储系统的事务接收器,即使在发生故障的情况下,也可以确保仅将数据精确地写入一次。
\- 与集群管理器的集成:Flink与Hadoop YARN,Mesos或Kubernetes等集群管理器紧密集成。当某个流程失败时,新流程将自动启动以接管其工作。
\- 高可用性服务的设置:Flink具有高可用性模式,以消除可能的单点故障。HA模式是基于Apache ZooKeeper实现的,实现可靠的分布式协调服务。
\- Flink提供了保存点(状态快照)的功能,以解决更新有状态的应用程序的问题以及其他相关的挑战。保存点是应用程序状态的一致性快照,与检查点非常的相似。与检查点相比,保存点需要手动触发,并且在停止应用程序时不会自动被删除,保证了保存点可用于启动状态兼容的应用程序并初始化恢复状态。使用保存点,可以将应用程序迁移(或克隆)到不同的群集。可便于A/B测试及假设分析场景对比结果(可以通过从同一保存点启动所有版本来比较应用程序的两个(或多个)不同版本的性能或质量。)
\- 对持续运行的流应用程序进行监控并将其集成到运营基础架构中,例如一个组件的监控服务及日志服务等。监控有助于预测问题并提前做出反应。通过日志服务,可以分析调查故障发生的根本原因,另外,一个易于控制运行中的应用程序访问的接口是一个重要的功能。Flink与许多常用的日志记录和监视服务很好地集成在一起,并提供REST API来控制应用程序和查询信息。Flink实现流行的slf4j日志记录接口,并与日志记录框架log4j或logback集成。Flink具有复杂的指标系统,用来收集并报告系统和用户定义的指标。指标可以导出到多个报告器,包括JMX,Ganglia,Graphite,Prometheus,StatsD,Datadog和Slf4j。link提供了REST API来提交新应用程序,获取正在运行的应用程序的保存点或取消应用程序。REST API还提供了正在运行或已完成的应用程序的元数据和收集的指标。
除了外国的一些公司,国内很多厂商也应用了Flink来应对流处理场景,那它们的Flink 做了什么呢?
- Alibaba 使用 Flink 的分支版本 Blink 来优化实时搜索排名。比如当商家上架一个商品之后,实时计算引擎(Flink)可在秒级别 build 商品索引,优化商品搜索。
\- 腾讯利用 Apache Flink 构建了一个内部平台(Oceanus),以提高开发和操作实时应用程序的效率。
\- 快手使用了 Apache Flink 搭建了一个实时监控平台,监控短视频和直播的质量。
滴滴使用 Apache Flink支持了实时监控、实时特征抽取、实时ETL等业务。
更多企业应用案例,参看Flink confluence;
其他相关参考:Flink中文社区;Apache Flink;
二、架构
Flink 是可以运行在多种不同的环境中的,如,它可以通过单进程多线程的方式直接运行,从而提供调试的能力。也可以运行在 Yarn 或者 K8S 这种资源管理系统上面,或在各种云环境中执行。Flink 运行时由两种类型的进程组成:一个 JobManager 和一个或者多个 TaskManager。Flink架构分为3个部分,client,JobManager(简称JM)和TaskManager(简称TM)。client负责提交用户的应用拓扑到jm(和spark的driver用法不同),flink的client只是单纯的将用户提交的拓扑进行优化,然后提交到jm,不涉及任何的执行操作。jm负责task的调度,协调checkpoints,协调故障恢复等。tm负责管理和执行task。

2.1、整体架构



Flink把任务调度管理和真正执行的任务进行了分离(物理分离)。对比spark的调度和执行任务是在一个jvm里的,也就是driver。分离的好处很明显,不同任务可以复用同一个任务管理(jm,tm),避免多次提交,缺点可能就是多了一个步骤,需要额外提交维护tm。



部署参考:

2.2、Flink的任务执行流程


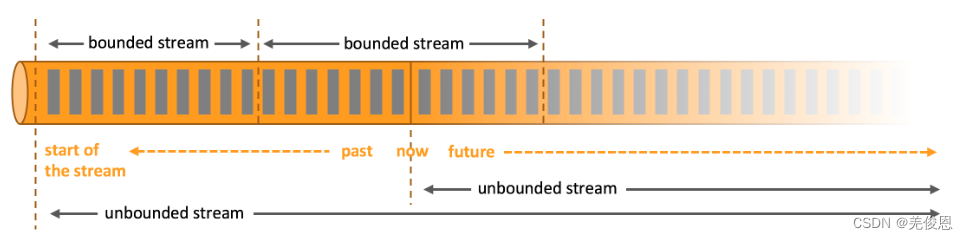
在Spark的世界观中,一切都是由批次组成的,离线数据是一个大批次,而实时数据是由一个一个无限的小批次组成的。而在Flink的世界观中,在 Flink 中,一切数据都是 Stream,离线数据是有界限的流,实时数据是一个没有界限的流,即所谓的 unbounded (无界)流和 bounded(有界)流。使用过 Hive 或 Mapreduce 或 mysql 的同学应该知道,数据存在 hdfs 或其他文件系统上,并且是一个固定的大小,我们把这些数据称为一批数据。使用过 Spark Streaming 或 Storm 的同学也应该知道数据源源不断的流入,流出,计算,这个过程的数据称为数据流。在 Flink 里,我们把批/流数据全部抽象成流,分为有界的流和无界的流。
无界流:有定义流的开始,但没有定义流的结束。它们会无休止地产生数据。无界流的数据必须持续处理,即数据被摄取后需要立刻处理。我们不能等到所有数据都到达再处理,因为输入是无限的,在任何时候输入都不会完成。处理无界数据通常要求以特定顺序摄取事件,例如事件发生的顺序,以便能够推断结果的完整性。
有界流:有定义流的开始,也有定义流的结束。有界流可以在摄取所有数据后再进行计算。有界流所有数据可以被排序,所以并不需要有序摄取。有界流处理通常被称为批处理。
未完待续……