此爬虫的目的是爬取今日头条街拍的组图图片
工具 环境:python3.6,windows10,pycharm
思路:
首先在今日头条网站种搜索关键字街拍,审查网络,街拍显示内容是通过ajax加载的
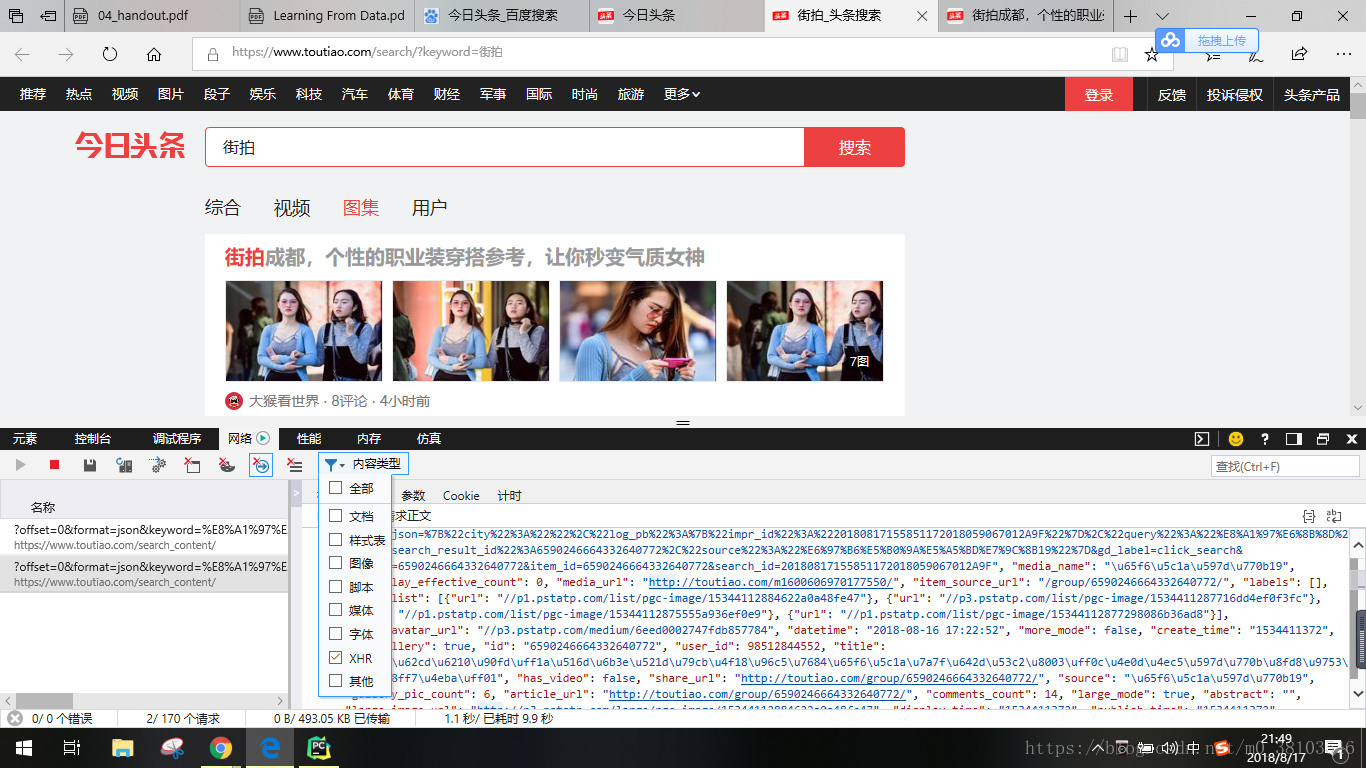
加载出的文件中,article_url是每个图集的链接地址,然后逐个访问图集的链接地址再查看里面的图片。点入其中某一个链接审查元素可以看到有一个字典类型的数据,从中可以提取图片的链接地址。

图片的链接地址在一个gallery的数据项中,将其中的url内容提取出来,然后进行下载,保存在本地文件中。
源代码如下:
from urllib.parse import urlencode
from requests.exceptions import RequestException
import json
import requests
import re
from bs4 import BeautifulSoup
#请求头文件,在获取index的内容的时候没有请求头也可以获得内容,但是在获取detail的时候没有请求头不能获取到内容
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36 Edge/17.17134'
}
#获取index的内容
def get_page_index(offset,keyword):
#获取链接地址
data = {
'offset':offset,
'format':'json',
'keyword':keyword,
'autoload':'true',
'count':'20',
'cur_tab':3
}
url = 'https://www.toutiao.com/search_content/?'+urlencode(data)
try:
response = requests.get(url,headers=headers)
#请求成功
if response.status_code == 200:
return response.text #返回响应的内容
return None
except RequestException:
print('请求索引页出错')
return None
#解析index获取的响应内容
def parse_page_index(html):
#将获取的网页内容转换为json字典类型
data = json.loads(html)
#在data属性中获取article_url属性内容
if data and 'data' in data.keys():
for item in data.get('data'):
yield item.get('article_url') #获取生成器
#获取详情页
def get_page_detail(url):
try:
response = requests.get(url,headers=headers)
if response.status_code == 200:
return response.text
return None
except RequestException:
print('请求详情页出错',url)
return None
#写入文件的地址
path = r'D:\pic\images'#r保持字符串的原始值,不进行转义
#解析详情页
def parse_page_detail(html,url):
soup = BeautifulSoup(html , 'lxml')
#获取图集的title,title在html文件的标签中,可以使用select方法直接获得
title = soup.select('title')[0].get_text()
# print(title)
#在响应报文中使用正则表达式提取内容
image_pattern = re.compile('gallery: JSON.parse\((.*?)\),')
result = re.search(image_pattern,html)
if result:
i=0
#需要使用两次json.loads(),只使用一次不能将字符串转换为字典类型
data = json.loads(json.loads(result.group(1)))
if data and 'sub_images' in data.keys():
#获取sub_images数据项中的内容
sub_images = data.get('sub_images')
#获取sub_images字典内容中的url属性的值
images = [item.get('url') for item in sub_images]
for image in images:
#获取每个图片地址的内容
im = requests.get(image)
string = r'\\'+ title+ 'p'+str(i)
#定义文件储存路径,并将图片保存在文件中
fp = open(path+'\%s.jpg'% string,'wb')
fp.write(im.content)
fp.close()
i=i+1
return {
'title':title,
'url':url,
'images':images
}
def main():
html = get_page_index(0,'街拍')
# print(html)
for url in parse_page_index(html):
# print(url)
html = get_page_detail(url)
result = parse_page_detail(html,url)
print(result)
if __name__ == '__main__':
main()
该代码中包含四个函数,分别为:获取index和解析index文件,获取详情页文件和解析详情页文件,其中出现的问题在代码中进行了简要的说明。