看paper的时候看到same padding的说法,之前撸代码的时候用过tensorflow中的same padding,但是现在具体怎么用的记不清了,查了网上的资料,总感觉很多有些晦涩,也不能说错,但是就是好像没说清楚的样子,容易让人产生歧义。特此整理一波。
(依旧会借鉴前人哦~~~)
在卷积函数conv2d和pooling函数中都会用到下面的这种padding方式~
在用tensorflow写CNN的时候,调用卷积核api的时候,会有填padding方式的参数,找到源码中的函数定义如下(max pooling也是一样),卷积函数原型:
def conv2d(input, filter, strides, padding, use_cudnn_on_gpu=None,data_format=None, name=None)源码中对于padding参数的说明如下:
padding: A `string` from: `"SAME", "VALID"`.The type of padding algorithm to use.让我们来看看变量x是一个2x3的矩阵,max pooling窗口为2x2,两个维度的strides=2。
第一次由于窗口可以覆盖(橙色区域做max pooling),没什么问题,如下:
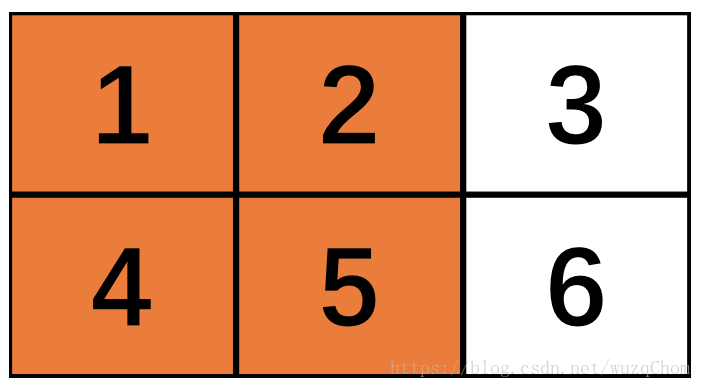
接下来就是“SAME”和“VALID”的区别所在:由于步长为2,当向右滑动两步之后,“VALID”方式发现余下的窗口不到2x2所以直接将第三列舍弃,而“SAME”方式并不会把多出的一列丢弃,但是只有一列了不够2x2怎么办?填充!
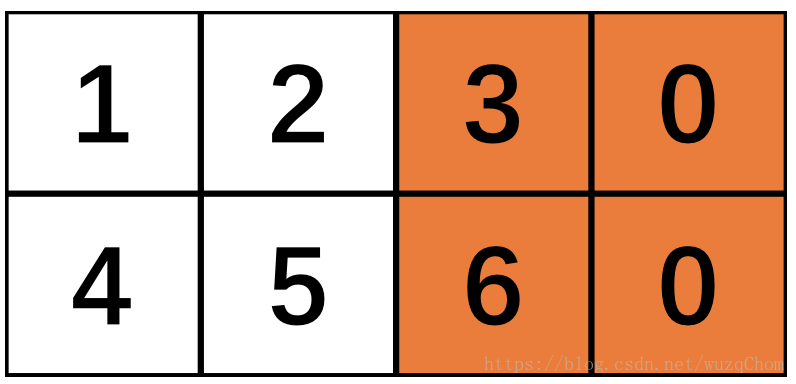
如上图所示,“SAME”会增加第四列以保证可以达到2x2,但为了不影响原来的图像像素信息,一般以0来填充。这就不难理解不同的padding方式输出的形状会有所不同了。
在CNN用在文本中时,一般卷积层设置卷积核的大小为n×k,其中k为输入向量的维度(即[n,k,input_channel_num,output_channel_num]),这时候我们就需要选择“VALID”填充方式,这时候窗口仅仅是沿着一个维度扫描而不是两个维度。可以理解为统计语言模型当中的N-gram。 比如用在textcenn用来做文本分类的时候就是这么做的~
我们设计网络结构时需要设置输入输出的shape,源码nn_ops.py中的convolution函数和pool函数给出的计算公式如下:
If padding == "SAME":
output_spatial_shape[i] = ceil(input_spatial_shape[i] / strides[i])
If padding == "VALID":
output_spatial_shape[i] =
ceil(
( input_spatial_shape[i] -
(spatial_filter_shape[i]-1) * dilation_rate[i]
)
/ strides[i]
).源码有点乱,其padding之后的大小计算公式可以如下
dilation_rate为一个可选的参数,默认为1,这里我们可以先不管它。
整理一下,对于“VALID”,输出的形状计算如下:
对于“SAME”,输出的形状计算如下:
其中,W为输入的size,F为filter为size,S为步长, 为向上取整符号。
可能你以为你了解了细节,但是如果我举个例子,对于3*3的原始矩阵,如果stride=1,filter size=2*2,那么根据公式计算出来的same结果是:3*3,valid计算结果是:2*2
又是为什么呢?
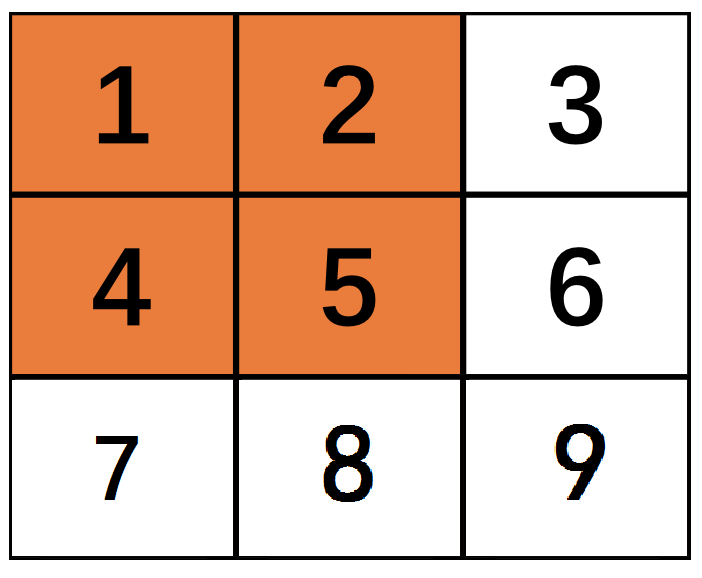
按照上面举的第一个例子看,应该是都是2*2才对啊,因为没有剩余的啊~
其实是这样的,原则是最后一列必须作为最后一个filter的第一列,也就是3 6这一列需要是最后filter的第一列,这样在卷积或者pooling的时候才不会丢失信息,也算是小细节啦~
其他具体计算可以详见参考文献2
参考文献: