思维导图:

做好推荐系统,需要分三步:1、认识每一个用户 2、给用户推荐用户感兴趣的东西 3、等待各指标上升
认识用户:用户画像
1、什么是用户画像?
用户画像对应的英文有两个:Personas和User Profile。(Personas属于交互设计领域的概念,不属于讨论范围)
例如:常见的用户画像如用标签云的方式绘制一个人的形状
2、用户画像的关键元素
推荐系统的使命是在用户(User)和物品(Item)之间建立连接,一般方式就是,对用户和物品之间的匹配评分,也就是预测用户评分或者偏好。推荐系统在对匹配评分前,则首先需要对用户和物品向量化,根据推荐算法不同,向量化的方式也不同,最终对匹配评分的做法也不同。
用户画像不是推荐系统的目的,而是在构建推荐系统的过程中产生的一个关键环节的副产品。
用户画像的关键元素:
1)、维度 :理论上来说维度越多,画像越精细,但带来的计算代价也是很大的,需要权衡
2)、量化:量化是主观的,以目标为导向,以推荐效果的好坏来反向优化出用户画像才有意义,用户画像的量化主要和‘效果’息息相关,需要根据使用效果(排序、召回等指标)来指导用户画像的量化。
3、构建用户画像的方法
1)、查户口
直接使用原始数据作为用户画像的内容,如注册资料等人口统计信息
2)、堆数据
堆积历史数据,做统计工作,常见的兴趣标签,就是从历史行为数据去挖掘出标签,然后在标签上做数据统计,用统计结果作为量化结果。
3)、黑盒子
用机器学习的方法,学习出人类无法直观理解的稠密向量,在推荐系统中承担的作用非常大。
比如:使用潜语意模型构建用户阅读兴趣,或者使用矩阵分解得到的隐因子,或者使用深度学习模型学习用户的Embedding向量
总结:
1、用户画像到底是什么?
它是对用户信息的向量化表示
2、用户画像的关键元素有那些?
维度、量化。用户画像是跟着使用效果走的,用户画像本身并不是目的
3、通常构建用户画像的手段有哪几类?
1) 查户口做记录 2) 堆数据做统计 3)黑盒子看不懂
从文本到用户画像
从文本开始:
1、用户:
1)注册资料中的姓名、个人签名
2)发表的评论、动态等
3)聊天记录
2、物品:
物品这一端也有大量的文本信息,可以用户构建物品画像,并最终帮助丰富用户画像(User Profile), 例如:
1) 物品的标题、描述
2) 物品本身的内容(一般指新闻资讯类)
3) 物品其它基本属性的文本
文本数据是互联网产品中最常见的信息表达形式,数量多,处理快,存储小,所以文本数据拥有特殊的地位
构建用户画像
要用物品和拥护的文本信息构建出一个基础版本的用户画像,大概需要做这些事:
1、把所有非结构化的文本结构化,去粗取精,保留关键信息
这一步最关键也是最基础,其准确性、粒度、覆盖面决定用户画像的质量
2、根据用户行为数据把物品的结构化结果传递给用户,与用户自己的结构化信息合并
这一步会把物品的文本分析结果,按照用户历史行为把物品画像传递给用户
一、结构化文本
用户端:
我们经常拿到的文本,都是自然语言描述的,就是‘非结构化的’,但是计算机处理时,只能使用结构化的数据索引,检索,然后向量化后再计算
物品端:
从物品端的文本信息,可以利用成熟的NLP算法分析得到的信息,主要算法如下:
1、关键词提取:最基础的标签来源,也为其它文本分析提供基础数据,常用TF-IDF和TextRank
2、实体识别:人物、位置和地点、著作等,常用基于词典的方法结合CRF模型
3、内容分类:将文本按照分类体系分类,用分类来表达较粗粒度的结构话信息
4、文本:在无人制定分类体系的前提下,无监督地将文本划分为多个类簇,别看不是标签,类簇编号也是用户画像的常见构成
5、主题模型:从大量已有的文本学习主题向量,然后预测新的文本在各个主题上的概率分布情况,也很实用,其实也是一种聚类思想,主题向量也不是标签形式,也是用户画像的常用构成。
6、嵌入:也称‘Embedding’,从词到篇章,无不可以学习这种嵌入表达,嵌入表达是为了挖掘出字面意思之下的语义信息,并且用有限的维度表达出来
常用的文本结构化方法:
1、TF-IDF
TF:(Term Frequency)词频,要提取关键词的文本中出现的次数
IDF:(Inverse Document Frequency)逆文档频率的意思,在所有的文本中,统计每一个词出现在多少文本中
计算公式:
IDF = log(N/(n+1))
计算出TF和IDF后,将两个值相乘,就得到每一个词的权重,根据权重筛选关键词的方式有:
1)、给定一个K,取Top K个词(总共得到的词个数大于k)
2)、计算所有词权重的平均值,取平均值之上的词作为关键词
某些场景下,还会加入其它过滤措施,如:只提取动词和名词作为关键词
2、TextRank
1) 文本中,设定一个窗口高度,比如k个词,统计窗口词和词的共现关系,将其看成是无向图
2) 所有词初始化的重要性都是1
3) 每个节点把自己的权重平均分配给和自己有连接的其它节点
4) 每个节点将所有其它节点分给自己的权重求和,作为自己的新权重
5) 如此反复迭代第3、4两步,知道所有的节点权重收敛为止
通过TextRank计算后的词语权重,呈现出这样的特点:那些有共现关系的会出现支持对方称为关键词
3、内容分类
每个门户网站都有自己的频道体系,这个频道体系就是一个非常大的内容分类体系
内容分类短文本方面经典的算法是SVM,在工具上现在比较常用的是Facebook的FastText
4、实体识别
命名实体识别是一个序列标注问题和分词、词性标注属于同一类问题。
对于序列标注问题,常用的算法是隐马尔科夫模型(HMM)或者条件随机场(CRF)
5、聚类
传统的聚类方法在文本中的应用,今天逐渐被主题模型取代,同样是无监督模型,以LDA为代表的主题模型能够更准确的抓住主题,并且能够得到软聚类的结果,也就是说可以让一条文本属于多个类簇。
6、词嵌入
Word Embedding能够为每一个词学习得到一个稠密的向量,通过计算好的词向量可以做以下事情:1、计算词和词之间的相似度,扩充结构化标签,2、累加得到一个文本的稠密向量 3、用于聚类,会得到比使用词向量聚类更好的语义更好的聚类结果
二、标签选择
前面说到,用户端的文本、文本端的文本如何结构化,得到诸如标签、主题等向量,接着即使图和把物品的结构化信息给用户
我们把用户对物品的行为,消费或者没有消费看成是一个分类问题。用户用实际行动帮助我们标注若干数据,那挑选出他感兴趣的特性就变成了一个特征选择问题
最常用的两个方法:卡方检验和信息增益
基本思想:
1、把物品的结构化内容看成文档
2、把用户对物品的行为看成是类别
3、每个用户看见过的物品就是一个文本集合
4、在这个文本集合上使用特征选择算法选出每个用户关心的东西
总结:
1、分析用户的文本和物品的文本,使其结构化
2、为用户挑选有信息量的结构化数据,作为其画像内容
3、把为用户挑选画像标签看成是特征选择问题,主要有卡方检验和信息增益
超越标签的内容推荐系统:
一、为什么要做好内容推荐?
内容推荐就是一个包装成推荐系统的信息检索系统,通常的复杂推荐系统很可能都是从基于内容推荐成长起来的。
推荐系统总是需要接入新的物品,这些新的物品在一开始没有任何展示机会,显然没有用户反馈,这时候只有内容可以帮到它。
基于内容的推荐能把这些新物品找机会推荐出去,从而获得一些展示机会。
如果要把基于内容的推荐做好,需要做好‘抓’、‘洗’、‘挖’,‘算’等步骤:
1、抓:持续抓取数据丰富自己的内容,做好基于内容的推荐,抓取数据补充内容源,增加分析的维度,两者必不可少
2、洗:需要对冗余的内容、垃圾内容、政治色情等敏感内容等等都需要被洗出去
3、挖:很多推荐系统的提升效果并不是用了更复杂的推荐算法,而是对内容的挖掘做的更加深入
4、算:匹配用户的兴趣和物品的属性,计算出更合理的相关性
典型的基于内容推荐的框架图如下所示:
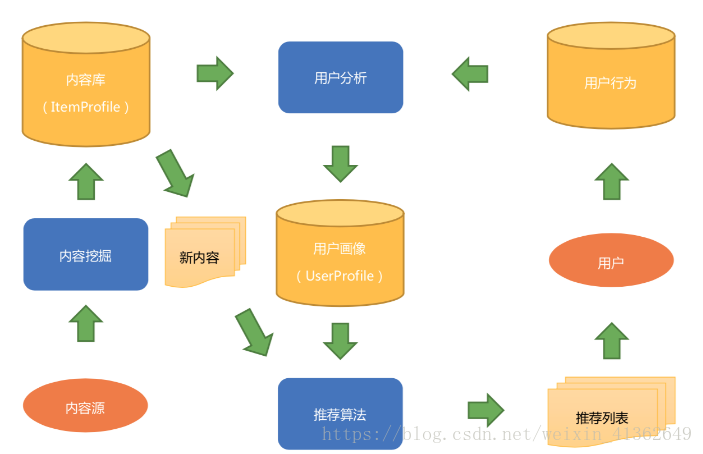
内容这一端:内容经过内容挖掘,得到结构化的内容库和内容模型,也就是物品画像
用户这一端:用户看过推荐列表之后,会产生用户行为数据,结合物品画像,经过用户分析得到用户画像
对于那些没有给用户推荐过的新内容,经过相同的内容分析过程后就可以经过推荐算法匹配,计算得到新的推荐列表给用户,周而复始
内容源:
互联网中,抓数据是一件可做不可说的事情,很多公司都有专门的团队抓数据,补充推荐系统每天的内容消耗
内容分析和用户分析:
基于内容的推荐,最重要的不是推荐算法,而是内容挖掘和分析。内容挖掘越深入,哪怕早期推荐算法仅仅是非常硬的规则,也能取得不错的效果。
例如:对内容分析越深入,能抓住用户群体越精细,推荐的转化率就越高,用户对产品的好感度也就增加啦
内容分析的产出有两个:
1、结构化内容库
最重要的用途是结合用户反馈行为去学习用户画像
2、内容分析模型
在内容分析过程中得到的模型,例如:分类器模型、主题模型、实体识别模型、嵌入模型,这些模型主要用在当新的物品刚刚进入时,需要实时地被推荐出去,这时候对内容的实时分析,提取结构化内容,再于用户画像匹配。
内容推荐算法
对于基于内容的推荐系统,最简单的推荐算法是计算相似性,用户画像内容就表示为稀疏的向量,同时内容端也有对象的稀疏向量,两者计算余弦相似度,根据相似度对推荐物品排序。
基于内容推荐天然有一个优点:拥有很强的解释性,如果再进一步,要更好的利用内容中的结构化信息,因为一个直观的认识是:不同字段的重要性不同。例如:一篇新闻,正文和标题中分析出一个人物名,评论中也分析出其它用户讨论提及的一些人物名,都可以用于推荐。
借鉴信息检索中的相关性计算方法来做推荐匹配计算:BM25F算法
常用的开源搜索引擎如Lucene已经实现经典的BM25F算法,可直接用
前面提到的两种办法都可以做到快速实现,但实际上都不属于机器学习方法,因为没有考虑推荐的目标。
机器学习的思路:
一种典型的场景:提高某种行为的转化率,如点击、收藏、转发等,典型的做法是收集这类行为的日志数据,转换成训练样本、训练预估模型。
每一条样本由两部分构成:一部分是特征,包含用户端的画像内容,物品端的结构化内容,可选的还有日志记录时一些上下文场景信息,如时间、地理位置等;另一部分就是用户行为,作为标注信息,包含有反馈和无反馈两类
用这样的样本训练一个二分类器,常用的模型是逻辑回归和梯度提升树或者两者的结合。在推荐匹配时,预估用户行为发生的概率,按照概率排序,这样更合理更科学,而且这一条路可以一直迭代下去。
小结:
基于内容的推荐一般是推荐系统的起步阶段,而且会持续存在,它的重要性不可取代,因为:内容数据始终存在并且蕴含丰富的信息量,产品冷启动阶段,没有用户行为,别无选择,新的物品要被推荐出去,首选内容推荐
基于内容的整体框架也是比较清晰的,其中对内容的分析最为重要,推荐算法可以考虑先使用相似性计算,也可以采用机器学习思路训练预估模型,当然这必须需要有大量的用户行为做保证。