一、问题引入:
设有A,B,C三种花,且它们在自然界的数量都相同,即在这三类中任意取一花,P(A)=P(B)=P(C)=1/3。现有一枝花,问它属于哪一类,则在没有任何提示的情况下,可以得知,它是A(或B或C)的可能性一样。
但,若此时用它们花萼的长度,花萼的宽度,花瓣的长度,花瓣的宽度,即4维向量 表示各自的特征,并且这些特征对我们已知。那么,这时它属于哪一类的不确定度减少,则我们能够得知它属于哪一类的概率就大了。
表示各自的特征,并且这些特征对我们已知。那么,这时它属于哪一类的不确定度减少,则我们能够得知它属于哪一类的概率就大了。
已知某样本的特征,判断它是哪一类,就是模式识别的任务,而已知某样本的特征,得出它属于这些类的概率,最大者为所属的类,就是贝叶斯分类的方法。以A为例,利用贝叶斯公式:

其中, 为这三类花中,花萼的长度,花萼的宽度,花瓣的长度,花瓣的宽度的总体密度分布,对于三类来说,都是一致的;
为这三类花中,花萼的长度,花萼的宽度,花瓣的长度,花瓣的宽度的总体密度分布,对于三类来说,都是一致的;
P(A)=1/3,称为先验概率,在实践中有已知的统计;
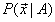 为类条件密度,即A类花的花萼的长度,花萼的宽度,花瓣的长度,花瓣的宽度服从的分布,在朴素贝叶斯分类中,假设该分布密度为4元高斯分布;
为类条件密度,即A类花的花萼的长度,花萼的宽度,花瓣的长度,花瓣的宽度服从的分布,在朴素贝叶斯分类中,假设该分布密度为4元高斯分布;
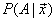 称为后验概率。
称为后验概率。
所以,在求解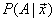 时,我们只需求解其展开公式的分子即可。
时,我们只需求解其展开公式的分子即可。

二、最小错误率的朴素贝叶斯分类:
对于 ,假设该分布密度为4元高斯分布,则为朴素贝叶斯分类,即分布为:
,假设该分布密度为4元高斯分布,则为朴素贝叶斯分类,即分布为:

计算过程如下:
对 展开公式的分子取对数(注:取对数不影响单调性,和极大值的取值),得:
展开公式的分子取对数(注:取对数不影响单调性,和极大值的取值),得:
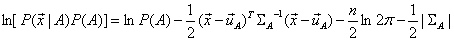
同理,可以计算B,C条件下的结果: ,将这三者中的最大值对应的类,作为决策的类别。
,将这三者中的最大值对应的类,作为决策的类别。
Python代码:
#实验的数据可以从http://aima.eecs.berkeley.edu/data/ 下载iris文档。
import numpy
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
data = numpy.genfromtxt('iris.csv', delimiter=',', usecols=(0,1,2,3))
target = numpy.genfromtxt('iris.csv', delimiter=',', usecols=(4), dtype=str)
#data[0]维花萼的长度,data[1]为花萼的宽,data[2]为花瓣的长,data[3]花瓣的宽,data[4]是标签。
t = numpy.zeros(len(target))
t[target == 'setosa'] = 1
t[target == 'versicolor'] = 2
t[target == 'virginica'] = 3
#训练
clf = GaussianNB()
train, test, t_train, t_test = train_test_split(data, t, test_size=0.4, random_state=0)
clf.fit(train, t_train)
#识别
print(clf.predict([data[3]]))
#print(classifier.predict_proba(data[1]))
#print(classifier.predict_log_proba(data[1]))
print(clf.score(test,t_test)) #计算识别正确率
MATLAB代码:
%需要对数据进行提取,剔除标签(我用Python实现的),得到的数据可直接作为特征向量用于MATLAB中
f1 = open('iris.txt', 'r')
f2 = open('iris_2.txt', 'w')
for i in range(150) :
line = f1.readline()
f2.write(line[0:15]+'\n')
f2.close()
f1.close()
clear;clc;
A=[5.1,3.5,1.4,0.2
4.9,3.0,1.4,0.2
4.7,3.2,1.3,0.2
4.6,3.1,1.5,0.2
5.0,3.6,1.4,0.2
5.4,3.9,1.7,0.4
4.6,3.4,1.4,0.3
5.0,3.4,1.5,0.2
4.4,2.9,1.4,0.2
4.9,3.1,1.5,0.1
5.4,3.7,1.5,0.2
4.8,3.4,1.6,0.2
4.8,3.0,1.4,0.1
4.3,3.0,1.1,0.1
5.8,4.0,1.2,0.2
5.7,4.4,1.5,0.4
5.4,3.9,1.3,0.4
5.1,3.5,1.4,0.3
5.7,3.8,1.7,0.3
5.1,3.8,1.5,0.3
5.4,3.4,1.7,0.2
5.2,4.1,1.5,0.1
5.5,4.2,1.4,0.2
4.9,3.1,1.5,0.1
5.0,3.2,1.2,0.2
5.5,3.5,1.3,0.2
4.9,3.1,1.5,0.1
4.4,3.0,1.3,0.2
5.1,3.4,1.5,0.2
5.0,3.5,1.3,0.3
4.5,2.3,1.3,0.3
4.4,3.2,1.3,0.2
5.0,3.5,1.6,0.6
5.1,3.8,1.9,0.4
4.8,3.0,1.4,0.3
5.1,3.8,1.6,0.2
4.6,3.2,1.4,0.2
5.3,3.7,1.5,0.2
5.0,3.3,1.4,0.2
7.0,3.2,4.7,1.4];
B=[6.4,3.2,4.5,1.5
6.9,3.1,4.9,1.5
5.5,2.3,4.0,1.3
6.5,2.8,4.6,1.5
5.7,2.8,4.5,1.3
6.3,3.3,4.7,1.6
4.9,2.4,3.3,1.0
6.6,2.9,4.6,1.3
5.2,2.7,3.9,1.4
5.0,2.0,3.5,1.0
5.9,3.0,4.2,1.5
6.0,2.2,4.0,1.0
6.1,2.9,4.7,1.4
5.6,2.9,3.6,1.3
6.7,3.1,4.4,1.4
5.6,3.0,4.5,1.5
5.8,2.7,4.1,1.0
6.2,2.2,4.5,1.5
5.6,2.5,3.9,1.1
5.9,3.2,4.8,1.8
6.1,2.8,4.0,1.3
6.3,2.5,4.9,1.5
6.1,2.8,4.7,1.2
6.4,2.9,4.3,1.3
6.6,3.0,4.4,1.4
6.8,2.8,4.8,1.4
6.7,3.0,5.0,1.7
6.0,2.9,4.5,1.5
5.7,2.6,3.5,1.0
5.5,2.4,3.8,1.1
5.5,2.4,3.7,1.0
5.8,2.7,3.9,1.2
6.0,2.7,5.1,1.6
5.4,3.0,4.5,1.5
6.0,3.4,4.5,1.6
6.7,3.1,4.7,1.5
6.3,2.3,4.4,1.3
5.6,3.0,4.1,1.3
5.5,2.5,4.0,1.3
5.5,2.6,4.4,1.2
6.1,3.0,4.6,1.4
5.8,2.6,4.0,1.2
5.0,2.3,3.3,1.0
5.6,2.7,4.2,1.3
5.7,3.0,4.2,1.2
5.7,2.9,4.2,1.3
6.2,2.9,4.3,1.3
5.1,2.5,3.0,1.1
5.7,2.8,4.1,1.3];
C=[6.3,3.3,6.0,2.5
5.8,2.7,5.1,1.9
7.1,3.0,5.9,2.1
6.3,2.9,5.6,1.8
6.5,3.0,5.8,2.2
7.6,3.0,6.6,2.1
4.9,2.5,4.5,1.7
7.3,2.9,6.3,1.8
6.7,2.5,5.8,1.8
7.2,3.6,6.1,2.5
6.5,3.2,5.1,2.0
6.4,2.7,5.3,1.9
6.8,3.0,5.5,2.1
5.7,2.5,5.0,2.0
5.8,2.8,5.1,2.4
6.4,3.2,5.3,2.3
6.5,3.0,5.5,1.8
7.7,3.8,6.7,2.2
7.7,2.6,6.9,2.3
6.0,2.2,5.0,1.5
6.9,3.2,5.7,2.3
5.6,2.8,4.9,2.0
7.7,2.8,6.7,2.0
6.3,3.4,5.6,2.4
6.4,3.1,5.5,1.8
6.0,3.0,4.8,1.8
6.9,3.1,5.4,2.1
6.7,3.1,5.6,2.4
6.9,3.1,5.1,2.3
5.8,2.7,5.1,1.9
6.8,3.2,5.9,2.3
6.7,3.3,5.7,2.5
6.7,3.0,5.2,2.3
6.3,2.5,5.0,1.9
6.5,3.0,5.2,2.0
6.2,3.4,5.4,2.3
5.9,3.0,5.1,1.8];
NA=size(A,1);NB=size(B,1);NC=size(C,1);
A_train=A(1:floor(NA/2),:);%训练数据取1/2(或者1/3,3/4,1/4)
B_train=B(1:floor(NB/2),:);
C_train=C(1:floor(NC/2),:);
u1=mean(A_train)';u2=mean(B_train)';u3=mean(C_train)';
S1=cov(A_train);S2=cov(B_train);S3=cov(C_train);
S11=inv(S1);S22=inv(S2);S33=inv(S3);
S1_d=det(S1);S2_d=det(S2);S3_d=det(S3);
PA=1/3;PB=1/3;PC=1/3; %假设各类的先验概率相等,即都为1/3
A_test=A((floor(NA/2)+1):end,:);
B_test=B((floor(NB/2)+1):end,:);
C_test=C((floor(NC/2)+1):end,:);
%test of Sample_A
right1=0;
error1=0;
for i=1:size(A_test,1)
P1=(-1/2)*(A_test(i,:)'-u1)'*S11*(A_test(i,:)'-u1)-(1/2)*log(S1_d)+log(PA);
P2=(-1/2)*(A_test(i,:)'-u2)'*S22*(A_test(i,:)'-u2)-(1/2)*log(S2_d)+log(PB);
P3=(-1/2)*(A_test(i,:)'-u3)'*S33*(A_test(i,:)'-u3)-(1/2)*log(S3_d)+log(PC);
P=[P1 P2 P3];
[Pm,ind]=max(P);
if ind==1
right1=right1+1;
else
error1=error1+1;
end
end
right_rate=right1/size(A_test,1) %计算出A中测试数据的准确率,同理可以测试B、C