引用于:https://blog.csdn.net/u010195841/article/details/69257897
overcoming catastrophic forgetting in neural networks
出处:2017 Jan 25 PNAS(proceedings of the national academy of sciences)
作者:deepmind团队 具体作者就不一一表述
deepmind团队是深度学习应用方向最厉害的团队,隶属于google。
部分翻译:
如今深度神经网络有个很难以解决的问题,就是持续学习(continual learning)。人脑的神经元数量是有限的,故而在人脑的整理学习过程中,不会出现应对一个新的问题就重新规划问题,而是对已有的神经元组合进行修改,使之能适应于持续学习。
这篇文章就是根据生物学上的突破(synaptic consolidation突触整合),将已有的深度神经网络进行修改,增加参数,使之能更好的适用于人工神经网络的持续学习。
Abstract
The ability to learn tasks in a sequential fashion is crucial to the development of artificial intelligence. Neural networks are not, in general, capable of this and it has been widely thought that catastrophic forgetting is an inevitable feature of connectionist models. We show that it is possible to overcome this limitation and train networks that can maintain expertise on tasks which they have not experienced for a long time. Our approach remembers old tasks by selectively slowing down learning on the weights important for those tasks. We demonstrate our approach is scalable and effective by solving a set of classification tasks based on the MNIST hand written digit dataset and by learning several Atari 2600 games sequentially
从摘要中我们可以得到几点信息:
(1)顺序学习能力是人工智能的发展的拦路虎;
(2)灾难性遗忘是网络结构的必然特征(catastrophic forgetting);
(3)顺序学习的定义,即根据任务A训练网络模型后,再根据任务B训练网络模型,此时对任务A进行测试,还可以维持其重要内容;
(4)它们对于灾难性遗忘提出了一个改进型的算法;
(5)改进型算法的测试集有两个,MINST和Atari。
Introduction
Introduction太长了,就不粘具体的内容,只给出具体有用的信息:
(1)为什么人工神经网络的连续学习会出现问题?
由于当前的人工神经网络对顺序任务的学习方式是先训练任务A,然后再训练任务B,任务A的参数与任务B的参数基本无关,使得当任务B训练完成后,该网络无法给出任务A的结果。
(2)什么叫做灾难消失?
在网络顺序训练多重任务时,对先前任务的重要权重无法保留,称之为灾难性消失。
算法设计环节
这篇文章的算法设计叫做Elastic weight consolidation(EWC),重要的部分(算法设计)在我读论文的时候,要求给出完整翻译(有部分是意译)。
In brains, synaptic consolidation enables continual learning by reducing the plasticity of synapses that are vital to previously learned tasks. We implement an algorithm that performs a similar operation in artificial neural networks by constraining important parameters to stay close to their old values. In this section we explain why we expect to find a solution to a new task in the neighborhood of an older one, how we implement the constraint, and finally how we determine which parameters are important.
在大脑中,通过减少突触的可塑性,整合突触能够持续学习,这对先前的学习任务极为重要。我们在人工神经网络中执行一个算法,具有同样的性能,通过限制重要参数以便于保留以前的参数值。这部分中,我们解释了三个问题:为什么我们期望在以前的学习任务周围找出一个新任务的解决方案;怎么实施限制;最后怎么确定哪些参数是重要的。
In this work, we demonstrate that task-specific synaptic consolidation offers a novel solution to the continual learning problem for artificial intelligence. We develop an algorithm analogous to synaptic consolidation for artificial neural networks,which we refer to as elastic weight consolidation (EWC for short). This algorithm slows down learning on certain weights based on how important they are to previously seen tasks. We show how EWC can be used in supervised learning and reinforcement learning problems to train several tasks sequentially without forgetting older ones, in marked contrast to previous deep-learning techniques.
在我们的工作中,我们表明特定任务突触整合方案提供了一种新奇的人工智能持续学习的解决方案。我们为人工神经网络提出类似于突触整合的算法,命名为elastic weight consolidation(EWC)。这个算法降低重要权重的学习率,重要权重的决定权是以前任务中的重要性。我们展示EWC怎样被使用于监督学习和强化学习中,对比实验是深度学习技术。

图1:弹性权重整合(EWC)确保训练任务B时同时记得任务A。训练轨迹阐明概要的参数空间,参数范围被很好的展示,任务A(灰色)、任务B(奶白)。经过第一次训练后,参数集合是。如果我们训练任务B单独使用梯度下降(蓝色箭头),当我们在最小化任务B的损失函数时,会失去任务A训练后的结果。另外,如果我们训练过程中相同的系数(绿色箭头)限制每一个权重,这样限制就过于严重,我们只能记住任务A的训练结果而无法训练任务B。相反的,EWC找到任务B的解决方案,不会对任务A的参数进行重大改变(红色箭头)通过明确的计算任务A的权重如何重要。
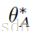
算法总结:
(1)此算法的设计原理采用映射的效果,将任务A的部分重要参数空间仍然复用,其它参数映射到任务B的参数空间中,这种映射的采用方案为条件概率,使用先验概率和后验概率,将条件概率公式进行修改。具体的见下面的图片(公式实在不好实现,所以进行手写图片的方式)

仅仅保存备用,如引用请标明原作者:https://blog.csdn.net/u010195841/article/details/69257897