2018年第24届国际模式识别大会International Conference on Pattern Recognition (ICPR)
在北京国家会议中心召开,会议从8月20日到24日持续1周时间。
有阿里的读光平台的介绍,周志华的的deep forest,以及业内大佬。还可以与作者面对面交流post,感觉提升很大。
论文(poster):Scene Text Detection via Deep Semantic Feature Fusion and Attention-based Refinement
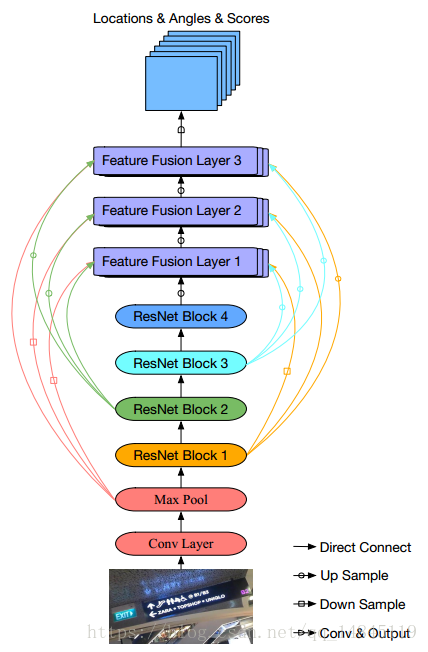
改进的EAST,原始的EAST将pool2,pool3,pool4,pool5的特征进行融合。该论文改进后将pool2,pool3,pool4,pool5的特征都和后续的3个特征融合层进行融合。
个人感觉有点生硬的进行长宽维度不统一的特征的融合,论文显示效果有提升,有待实现验证。
论文(poster):An Efficient System for Hazy Scene Text Detection using a Deep CNN and Patch-NMS
是个印度的学者,
论文主要是雾中场景文字的检测。
主要贡献在于:
- 不是进行文本/背景的二分类,而是文本(Text)/雾(Haze)/文本+雾(Haze+Text)/背景(Background)的四分类。
- 基于图片中每个patch做的G-NMS
- 自己贡献一个带雾的数据集,Fast text detection from single hazy image using smart device
论文:Focus On Scene Text Using Deep Reinforcement Learning
华南理工金连文老师组的作品,基于强化学习来改进文字检测。

论文:Robust Scene Text Detection with Deep Feature Pyramid Network and CNN based NMS Model
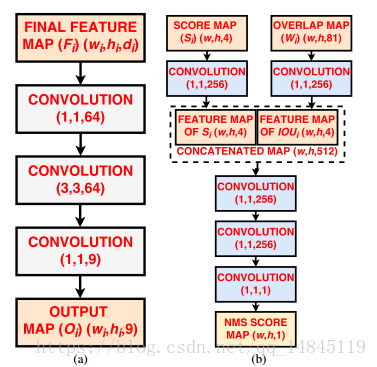
类似于face++ 的IOU net,主要在NMS那块将score map和overlap map组合,通过网络学习出一个NMS分数。
论文:Sliding Line Point Regression for Shape Robust Scene Text Detection
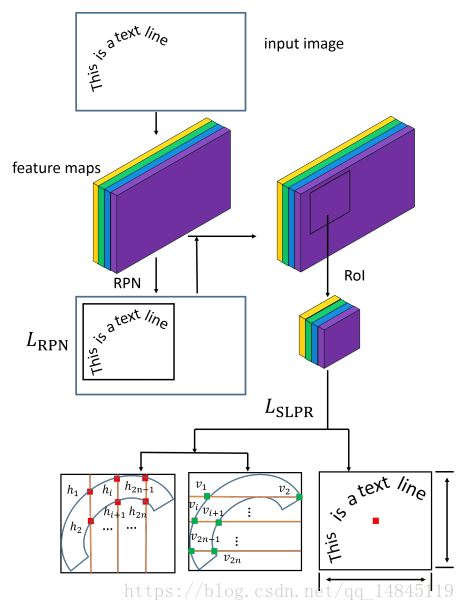

文章主要在传统检测框架的基础上,增加了水平7个维度和竖直7个维度的各2个点的回归。最终实现了对曲形文本的检测。感觉思想还是挺novel的。
论文:Document Image Classification with Intra-Domain Transfer Learning and Stacked Generalization of Deep Convolutional Neural Networks
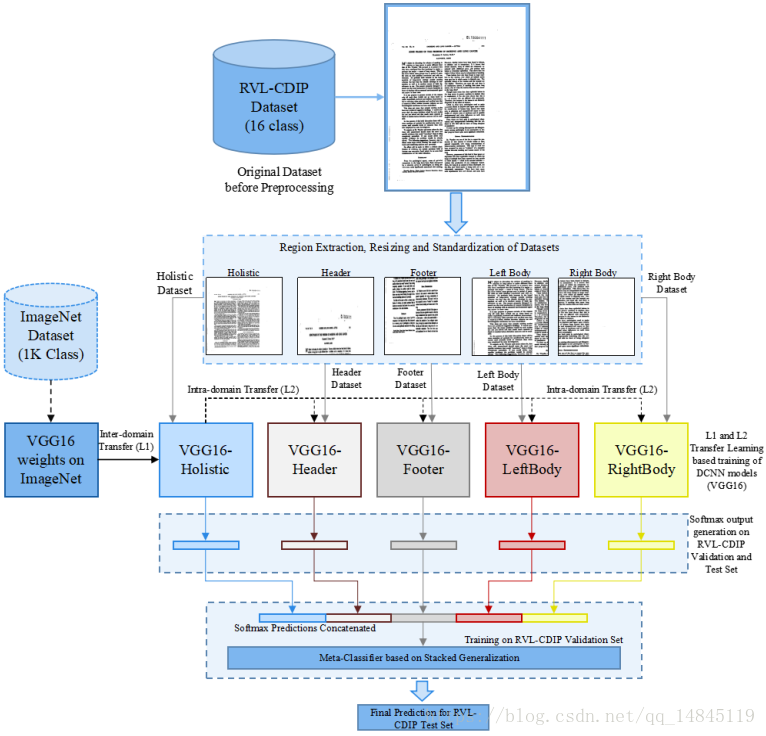
基于区域的文档结构学习,通过对文档的上下左右和全局进行集成学习。实现了16类(Letter, Memo,Email, Folder, Form, Handwritten,Invoice,Advertisement,Budget,News,Presentation,Scientific Publication Questionnaire, Resume, Scientific Report,Specification)不同文档的分类。在RVL-CDIP文档数据集上达到92.21%的分数。
论文:Multi-scale Fusion with Context-aware Network for Object Detection

尺度和上下文信息对检测起着重要的作用。文章主要在多尺度和上下文信息上进行改进。最终得到75.9% mAP on PASCAL VOC 2007,72.0%mAP on PASCAL VOC 2012 ,23.2% mAP on MS COCO。
论文:Aligning Text and Document Illustrations: towards Visually Explainable Digital Humanities

主要实现文档中图片和文字的对齐操作,就是找到和一幅图片相对应的文字内容。
论文:A Fusion Strategy for the Single Shot Text Detector
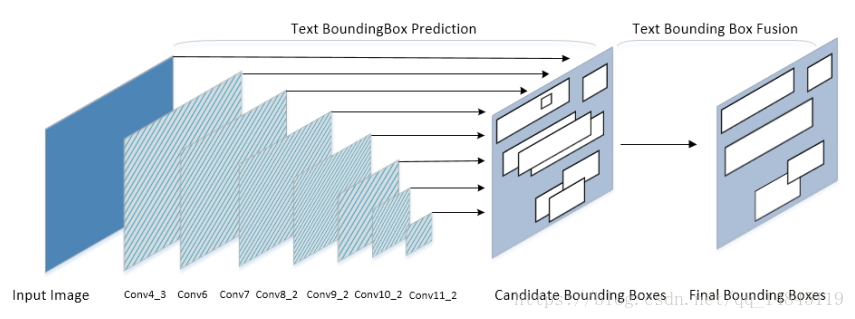
主要提出了Text-BBF 方法来代替传统的NMS方法
论文(oral):Scene Text Detection with Recurrent Instance Segmentation
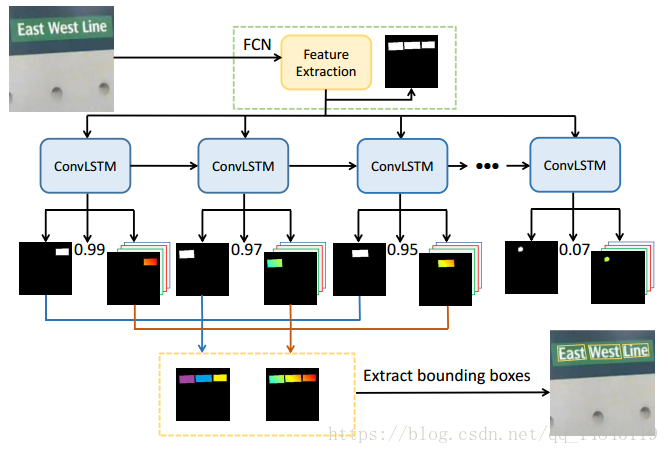
自动化所刘成林老师组的作品。整体感觉像EAST+lstm。
论文(post):Scene text rectification using glyph and character alignment properties

- 一行字符串中,大部分字符的顶部点(蓝色)和底部点(绿色)应该在同一个水平线上。
- 矫正的字母的宽度应该最小。
论文主要基于字形和字符的上面2点属性对场景文字进行校正。最终使得识别结果有提升。

论文:ThinNet: An Efficient Convolutional Neural Network for Object Detection

主要提出了一个轻量的物体检测框架ThinNet ,ThinNet 主要包含2给模块Front module 和Tinier module 。Front module主要是减少了卷积层的filter数量,增加了卷积的层数。Tinier module中将普通的卷积换为了pointwise卷积。整体感觉没什么创新。
论文:Dense Receptive Field for Object Detection
Github:https://github.com/yqyao/DRFNet

第一篇看到的icpr中开源程序的论文。论文主要提出了一个新的改进的ssd的one stage检测框架DRFNet 。如上图所示,主要的改进的思想就是多个scale的特征的融合。
论文(post):R2CNN: Rotational Region CNN for Arbitrarily-Oriented Scene Text Detection

北京三星电子研究院的作品。
主要还是改进的faster RCNN。
- 修改了不同的anchor,更加适应文字检测。
- 修改roi pooling,在原始7*7的基础上,增加了3*11和11*3的featuremap。再将所有的feature map融合进全连接层。
- 最后的边界框的回归,采用回归左上角的点x,y和右上角的点x,y和高度h,这样来定位斜框。当然原始faster的回归的坐标对齐的框也保留,进行多任务学习,相互促进。
- 由于出来的框是斜框,于是有了Inclined NMS。
整体感觉没有特别创新的东西,感觉这些修改都是针对文字这个特殊检测对象进行的本该这样的修改。
论文:Fused Text Segmentation Networks for Multi-oriented Scene Text Detection
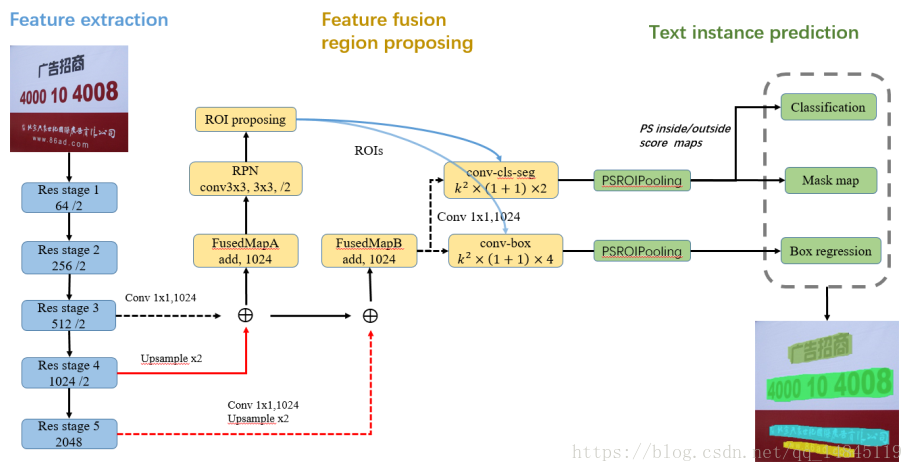
主要提出feature fusion的思想做特征融合。后续的roi pooling换成了psroipooling(position sensitive roipooling)。
论文(poster):CG-DIQA: No-reference Document Image Quality Assessment Based on Character Gradient
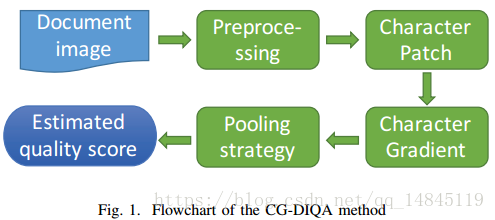
上海中安信息科技的论文,主要做文档质量鉴定。对输入的文档图片进行预处理,然后MSER提取文本区域,并计算梯度,根据梯度的大小进行文档质量鉴定,梯度越大,文档质量越好。
个人感觉文字的梯度和文档质量之间貌似没啥联系。可能越清晰的文档,明暗对比越鲜明,噪声越多的文档,明暗对比较差吧。
论文(poster):Page Object Detection from PDF Document Images by Deep Structured Prediction and Supervised Clustering
刘成林老师组的论文,感觉这篇思想非常的好。非常推荐读。
整体流程如下,
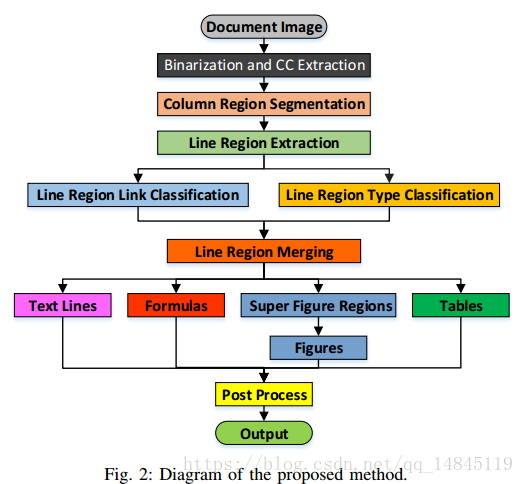
论文主要实现文档布局分析。
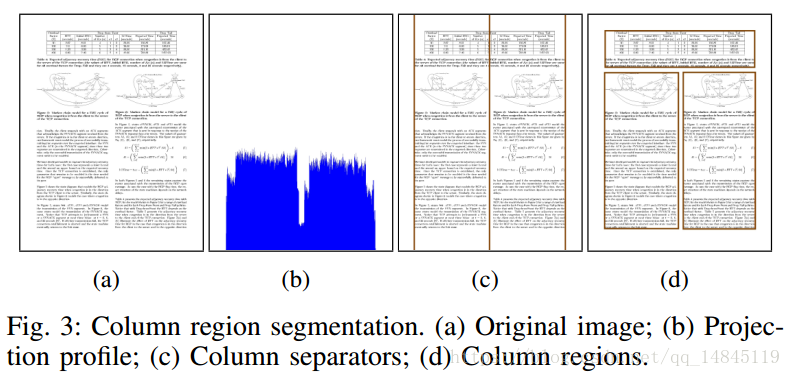
首先基于投影法,分别对文档图片进行水平和竖直的投影,可以得到每一个大块的区域。这里假定了文档图片是没有噪声的黑白的干净的图片。

对于每一个区域内的图片,再进行水平方向的投影,得到行区域。这个行区域可能是只有一行,也可能是好几行合并到一起。然后将该行区域输入到下面的网络中,进行公式,图,表,文字的四分类。注意这里输入的图片大小为32*640。

但是当有好多行被分为一行区域时,该网络得到的结果就会不准确。因此对于高度大于100像素的行区域,使用下面的网络进行进一步矫正。网络输入大小为64*64。

这样就得到了每一个行区域的类别概率。对于相邻的两行是否需要合并,则通过下面的网络进行。感觉有种seglink的味道。
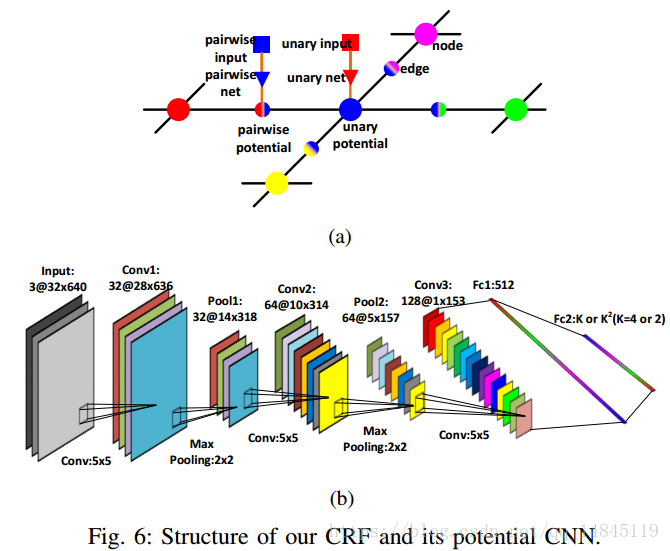
该网络的输入还是32*640,输入为灰度图,但是是将要判断是否需要进行合并的2行,分别将其中一行作为第一个通道,另外一行作为第二个通道,这两行在高度方向concat起来的图作为第三个通道。将这样一个组合的图片作为输入图片,得到输出的2个分类。
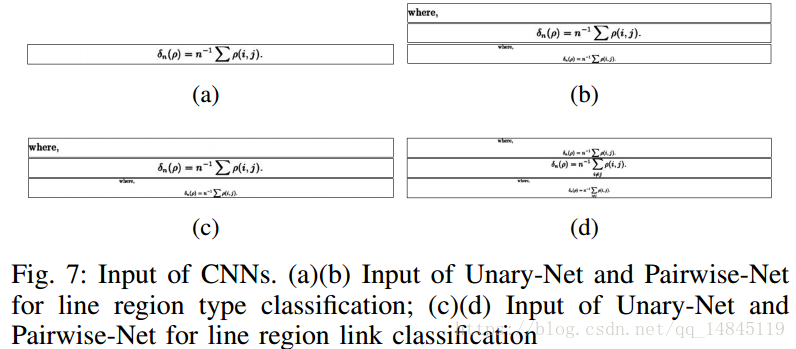
然后作者这里还利用了一个基于CRF的图模型。会输出第一行为某类的概率和第二行为某类的概率,以及两者同时满足的概率。然后将一个区域中的所有行都组合起来,形成上面的图,最终要得到满足整个图概率最大化。
论文(poster):Watercolor, segmenting images using connected color components

论文主要提出了基于LAB空间,颜色连通域的文档图像分割方法。该方法的优势在于没有任何阈值需要设置。
论文:A robust and efficient method for license plate recognition
论文主要提出一种车牌识别的方法。网络结构为LCR(LocateNet ,CutNet ,RecNet)
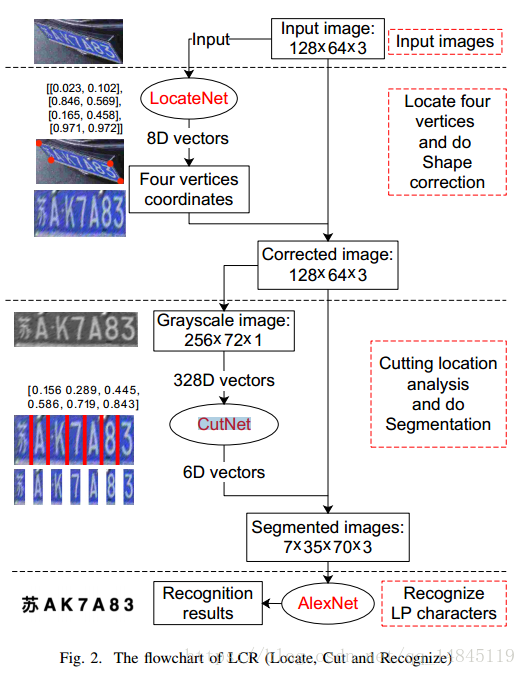
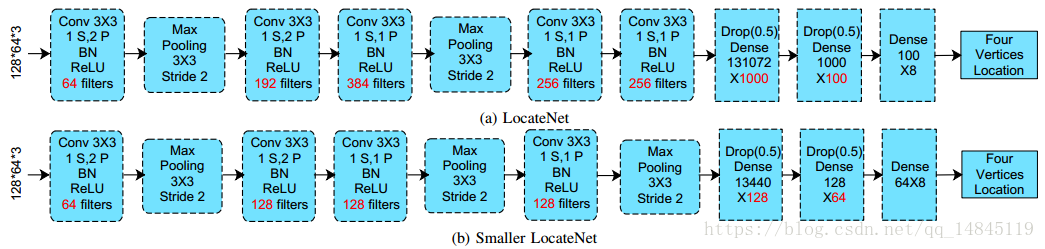
LocateNet 负责回归4个坐标值,然后经过仿射变换将输入图片转化为转正的车牌图片。
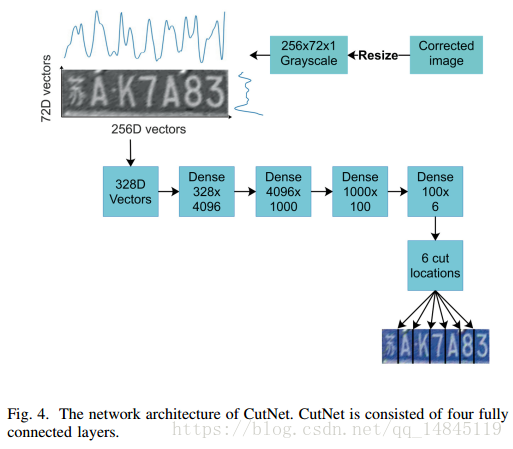
CutNet 负责回归出6个分割的线
RecNet使用AlexNet对分割出的单个字符进行识别。
论文:Staff line Removal using Generative Adversarial Networks
论文主要使用GAN来去除乐谱的下划线,在ICDAR/GREC 2013 取得了99.14%的F-m score。可以将该方法应用在文本下划线的去除上。
整体结构,

生成器结构,采用U-Net,
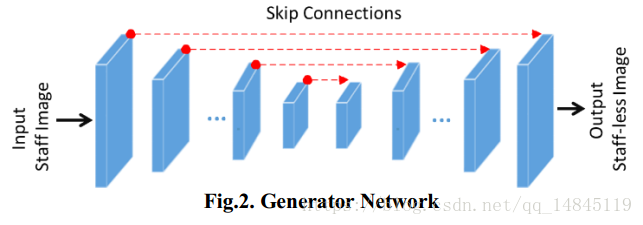
判别器结构,
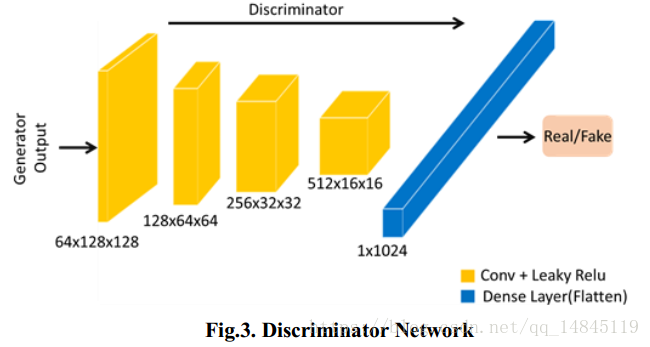
论文:Word Level Font-to-Font Image Translation using Convolutional Recurrent Generative Adversarial Networks
论文主要提出使用GAN来生成可变长的各种字体风格的字体。
整体框架,

网络结构,

最终效果,

从上图还是可以看出,生成的数据虽然和原始的数据很像,但是还是存在人眼可以辨别出的区别,应该还是没达到可以作为训练数据的程度。
论文:Screen-rendered text images recognition using a deep residual network based segmentation-free method
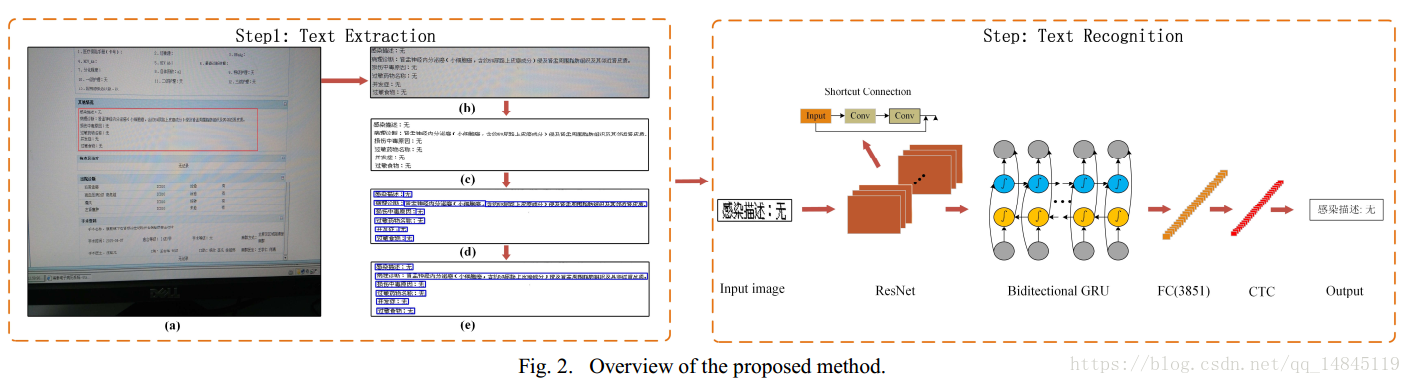
论文提出了对于屏幕渲染的文字的识别方法,本质还是Resnet+lstm+ctc,分别在ORAND-CAR-A dataset, ORAND-CAR-B dataset 取得了91.89%和93.79%的分数。
论文:Weighted-Gradient Features for Handwritten Line Segmentation
论文对手写文档的文本行线的分割提出了一种基于Weighted Gradient Features (WGF) +k-means 的方法。
最终结果,

论文(oral):A Novel Integrated Framework for Learning both Text Detection and Recognition
阿里巴巴计算平台组的论文。主要提出了一个端到端的文本检测+识别框架。整体来看faster RCNN+CRNN的合体。
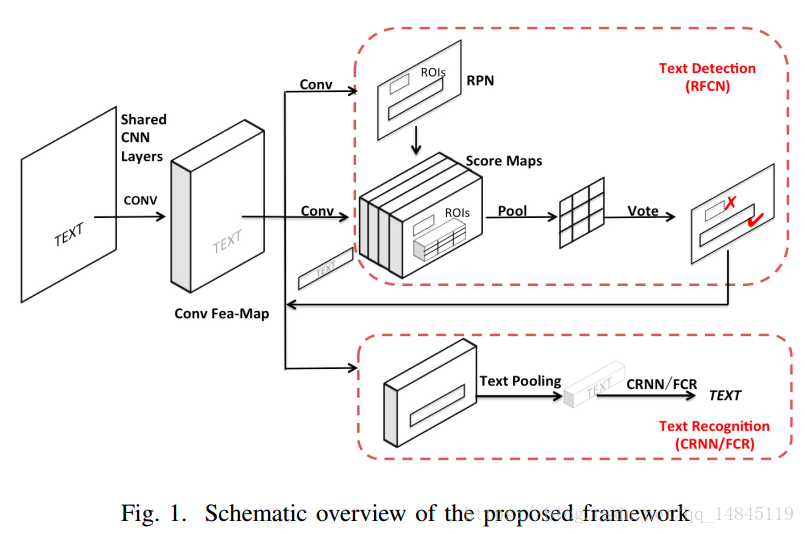
检测+识别一起做感觉有个优势就是,如果单独的做,检测不好的框,将会直接影响识别,识别就会因为检测的不好而识别错。但是假如一起做,即使检测的不准确,识别也会得到正确的结果。因为识别的特征是直接在共享卷积层那部分的特征图上提取出来的。前面的共享卷积层已经对框外面的那些像素有过卷积操作,也就是感受野会比框略大。所以也就容易弥补检测的缺陷。

论文:Pyramid Embedded Generative Adversarial Network for Automated Font Generation
阿里巴巴的论文,主要基于Pyramid Embedded Generative Adversarial Network (PEGAN) 来造字。
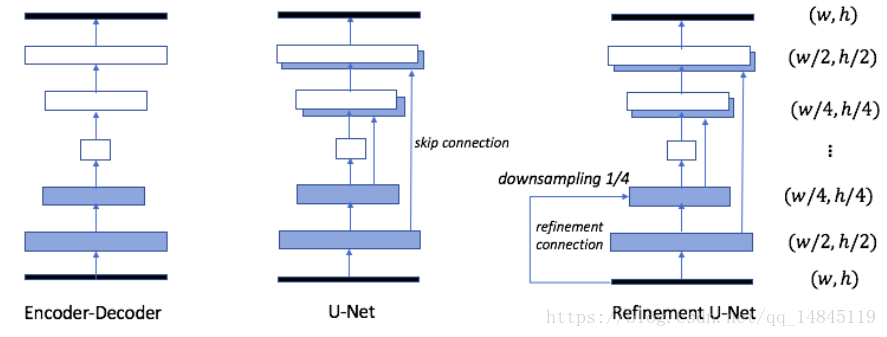
其中生成器,对U-net进行了改进,在U-net的基础上,将前面部分的特征都进行下采样与后面的部分进行融合,也就是refinement connection操作。
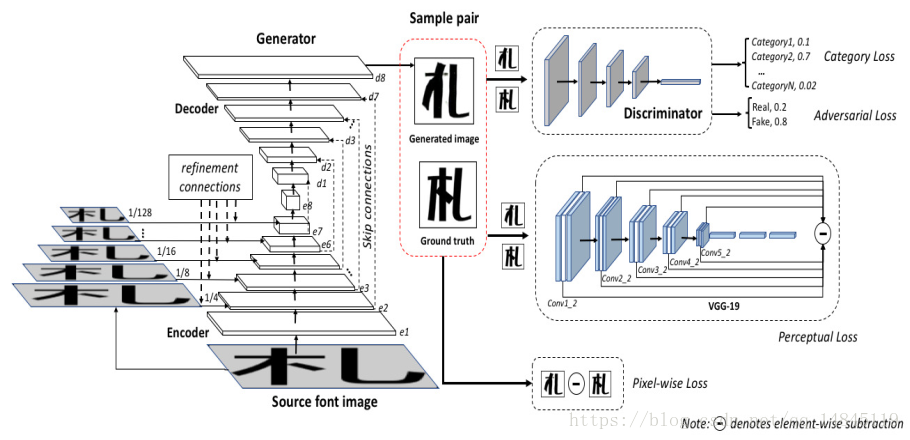
亮点在于训练过程中使用了4个loss。分别为pixel-wise loss,adversarial loss,caregory loss,perceptual loss。
pixel-wise loss:生成器的L1 loss。
adversarial loss:判别器的分类的loss
caregory loss:字的类别的分类的loss
perceptual loss:基于感知的loss,对于vgg-19的每一层featuremap都对输入的2个图做L1 loss。
整体来看,对于U-net的特征融合的改进,还有4个loss的提出,都是比较有创新的。值得学习。
论文:Trajectory-based Radical Analysis Network for Online Handwritten Chinese Character Recognition
论文提出了一种基于笔画轨迹的汉字识别方法trajectory-based radical analysis network (TRAN) ,并且在CASIA-OLHWDB database 测试集上取得了60%的准确性。
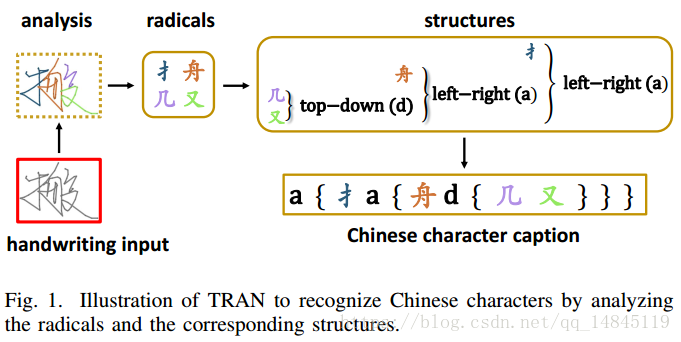
字体的结构如下,
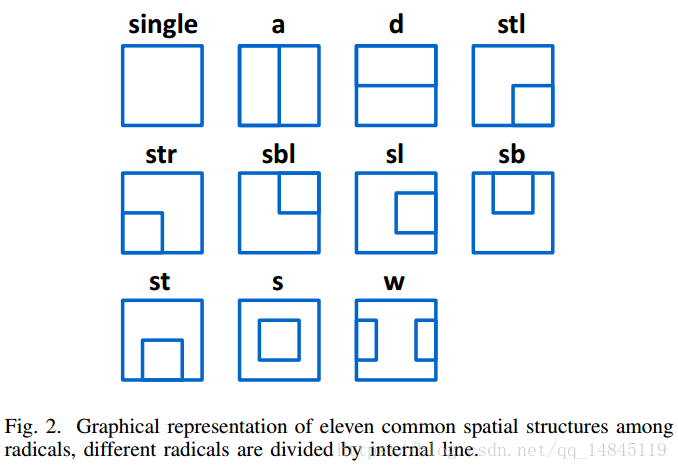
整体结构,

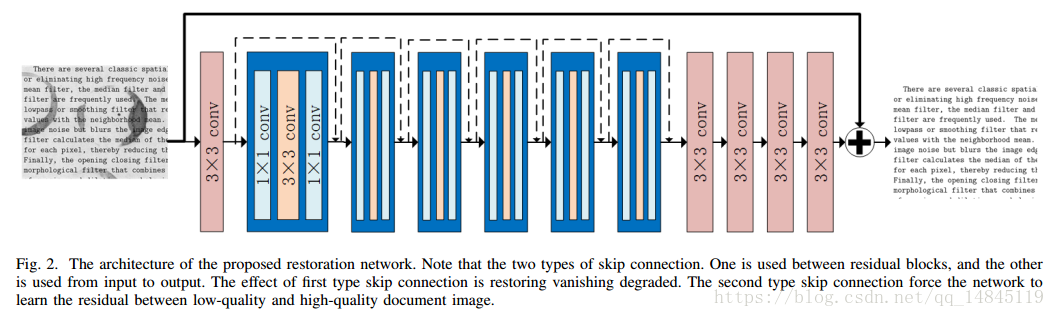
论文(post):Skip-Connected Deep Convolutional Autoencoder for Restoration of Document Images
论文提出了SkipConnected Deep Convolutional Autoencoder (SCDCA) 网络进行文档图像的denoising和 deblurring 操作。
网络的创新在于,卷积层之间的shortcut和输入层和输出层之间的shortcut。
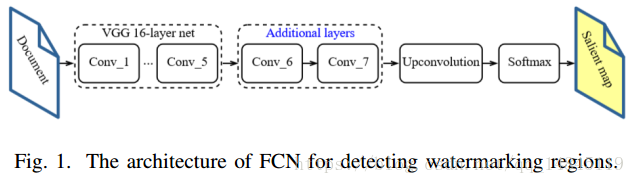
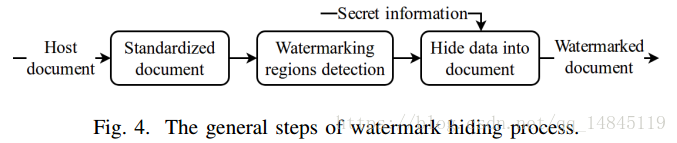
论文:Document Images Watermarking for Security Issue using Fully Convolutional Networks
论文主要提出了文档图像中水印的嵌入方法,首先基于FCN找到文字区域,然后再基于文字区域进行水印的嵌入。
FCN结构,
整体流程,
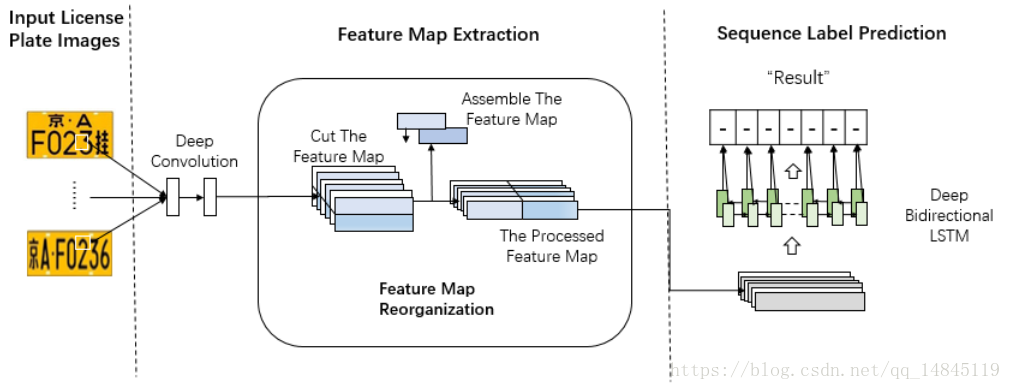
论文(post):An End-to-End Neural Network for Multi-line License Plate Recognition
论文提出了双行车牌的识别方法,主要是对featuremap基于height一分为二,然后在width方向concat起来。最终网络既可以识别单行车牌,也可以识别多行车牌。最终在SYSU-ITS license plate 数据集上取得了98.5%的准确性。
论文:A Hybrid Deep Architecture for Robust Recognition of Text Lines of Degraded Printed Documents
论文主要实现对于打印的文档图片的去背景的操作。主要使用GMM。然后再对修正过的图片进行基于crnn的识别。
不同方法的对比,可以看出GMM方法可以取得更好的效果。

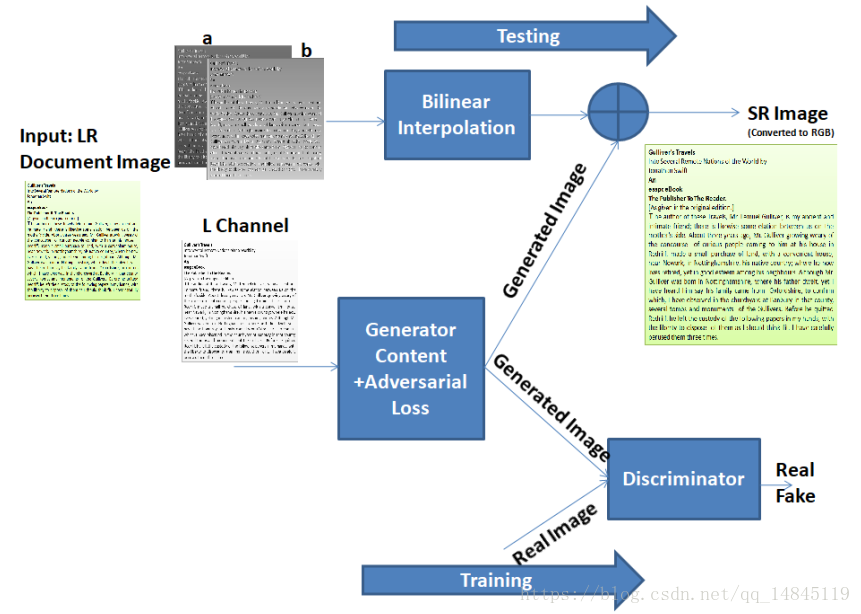
论文:Enhancing OCR Accuracy with Super Resolution
论文主要通过GAN实现的超分来改善文档图片的质量,进而提高识别率。
论文(post):Historical document image binarization using background estimation and energy minimization
基于传统方法的背景去除方法,主要基于背景检测,能力最小化,笔画宽度变换(SWT),基于拉普拉斯能量的分割。最终在DIBCO 和H-DIBCO benchmark数据集上击败了其他传统方法。
处理流程,

几种方法的结果对比,

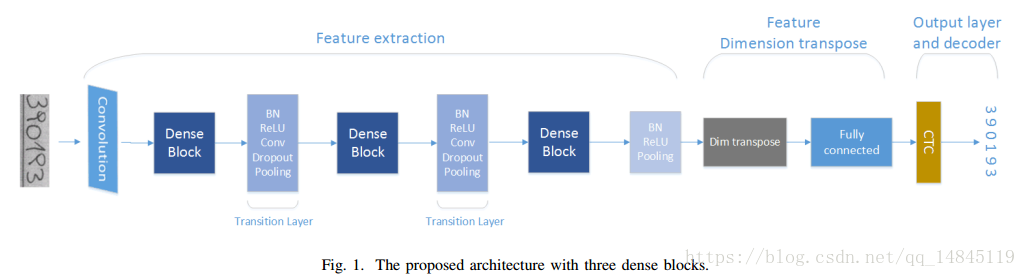
论文(post):Handwritten Digit String Recognition using Convolutional Neural Network
还是crnn的一套,用在了handwritten digit string recognition (HDSR),基础结构替换为desnet,最终在ORAND-CAR-A和ORAND-CAR-B datasets 分别达到了 92.2% 和94.02% 的识别率。
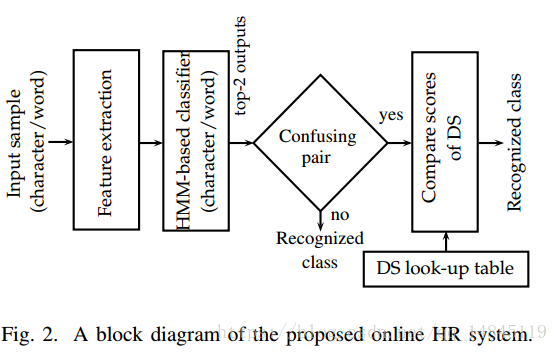
论文:Exploring Discriminative HMM States for Improved Recognition of Online Handwriting
论文基于隐马尔科夫hidden Markov model (HMM) 对字符的识别结果进行top-2的纠正。感觉类似beam search的思想,要找到整个链的最大的识别率总和。
论文:ICPR2018 Contest on Robust Reading for Multi-Type Web Images
阿里巴巴和华南理工金连文合作的论文。
ICPR MTWI 2018 挑战赛三:网络图像的端到端文本检测和识别:
ICPR MTWI 2018 挑战赛二:网络图像的文本检测:
ICPR MTWI 2018 挑战赛一:网络图像的文本识别:
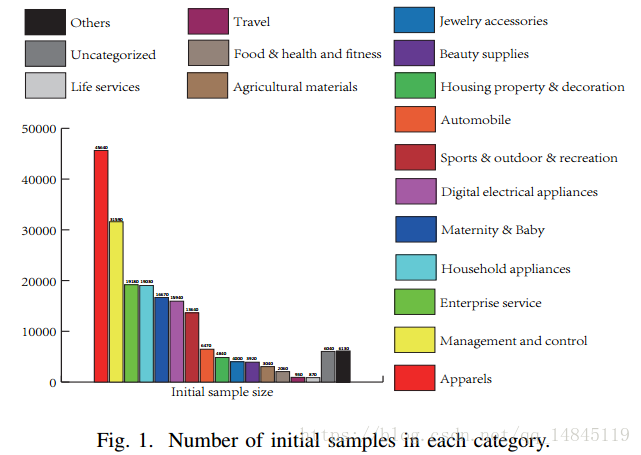
数据集为MTWI 数据集,主要包含淘宝的20000张网络图片。主要包含17个类别,类别分布如下图。该数据集可以用于文本检测+识别的训练和测试。
The papers: