首先,给大家推荐一个平台,Coursera (类比国内的mooc网),你可以在上面学习诸多国外一流大学的公开课视频,各个领域的都有,涉猎范围很广。想要出国留学的小伙伴儿不妨在上面事先感受一波国外授课的氛围与模式。
言归正传,作为一名程序猿,算法实在是太重要了!即便不是一名程序员,学习一下算法编程也是很有好处的。因为,在某种层面上讲,算法是你针对计算机进行的解决问题的思想上的映射,代码就是你想法的载体,逻辑的展现形式和与计算机进行沟通的工具。随着学习的深入,你会发现好多编程的技巧其实都源于生活!学习编程就是感悟生命!当然,在某种程度上,你也可以理解为我在胡说八道!哈哈!
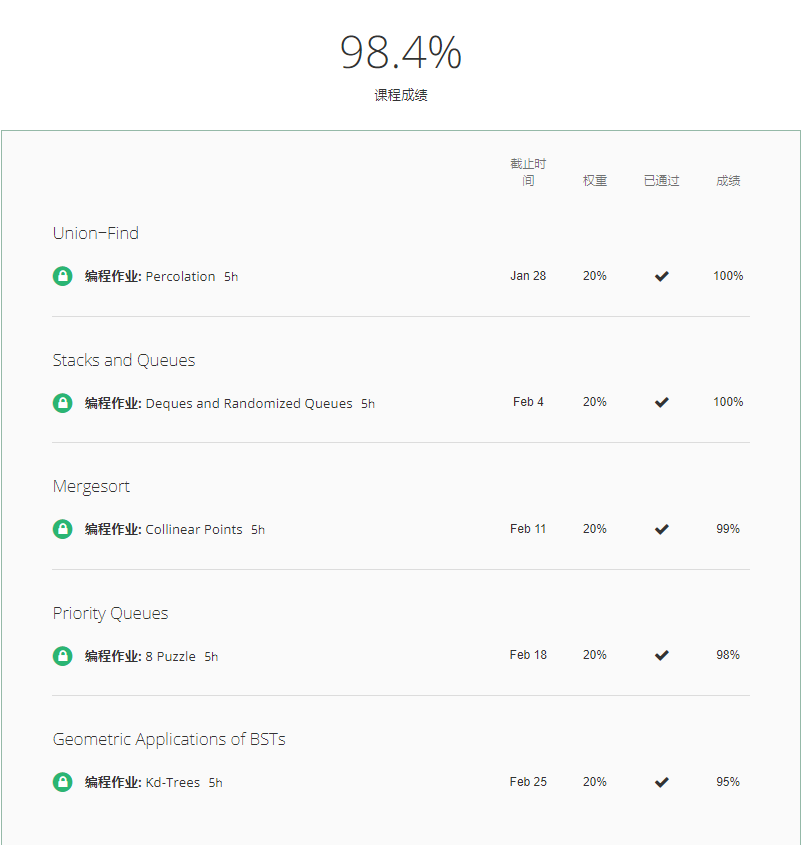
下面介绍一下我学习普林斯顿大学_算法公开课:Part_1的经历吧!
由于是回顾课程,所以重点放在对核心算法的理解与剖析上:
第一部分:并查集
问题描述:你可以把下面这个图整体想象成是一个地下管道通水系统。黑色的是土,白色的是空管道,蓝色的是通水的管道。
显然,水是从上往下流的,只有靠近最上边界的管道才可以通水。同时,这个通水的过程是有压力的,不知道是不是有一个水泵,还是自然现象,凡是联通的水管情况是保持一致的,即不管管道是否是逆生长,既然你们手拉手是联通的,那就是一伙儿的,要么同流合污,要么空空如也!这里有一个关键点,你在编程中会注意到:下边界不是自联通的。而上边界,你可以想象成在其上方有一个水库,凡是靠近边界的水管都有水喝,呵呵!说了这么多废话,那么问题究竟是什么呢?就是针对一大片直立的黑土地,随机的铺设管道,啥时候水管才能Percolate?Percolate啥意识呢?就是上下边界中存在至少一条联通的水流!

答案是:
mean= 0.59229975
stddev= 0.011781283036553099
95% confidence interval=[0.5899906185248356,0.5946088814751644]
就是说大概随机管道铺设覆盖率达到60%,上下边界水流就通了!
怎么样,60分及格不无道理吧!编程即生活吧!
并查集核心算法:
package unionFind;
public class SelfUN {
private int count;
private int[] parent;
//private int[] size;//记录以当前节点为根节点的子树拥有的节点总数。
public SelfUN(int n) {//节点初始化。
count = n;
parent = new int[n];
//size = new int[n];
for (int i = 0; i < n; i++) {//初始状态每个节点的父节点是其自身。
parent[i] = i;
//size[i] = 1;
}
}
public int getCount() {//获取并查集中节点总数。
return count;
}
private void validate(int p) {//节点是否有效判别。
try {
if (p < 0 || p >= count) {
throw new IllegalArgumentException("");
}
} catch (Exception e) {
System.out.println("The parameter is wrong!");
}
}
public int find(int p) {//查集
validate(p);
int root = p;
while (parent[root] != root) {//找到根节点
root = parent[root];
}
while (p != root) {//路径压缩,将除根节点以外的所有节点都直指根节点。即每一次find都是一次优化。
int tmp = parent[p];
parent[p] = root;
p = tmp;
}
return root;
}
public boolean connected(int p, int q) {//追根溯源,查看两个节点是否具有相同的根节点,进而判别是否互相联通。
return find(p) == find(q);
}
public void union(int p, int q) {//将两个节点并集,归为一类。
if (find(p) == find(q))//如果原本互联,则无需操作。
return;
/* 此处保证总是将较小的那棵树合并到较大的那棵树上,以原较大的树的根节点作为合并后的根节点的好处是使得树更均衡,也是一种路径上的优化。
* 一种极端的情况是:路径压缩过程中可以保证遍历的是节点更少的那棵树,时间复杂度在一定程度上降低了。
* if(size[p]<=size[q]) { parent[p]=q; size[q]+=size[p]; }else { parent[q]=p;
* size[p]+=size[q]; }
*/
// count--;
if (p <= q) {//此处类比大根堆,遵循某种规律实际上也是一种路径上的优化,与size的引入同理。
parent[p] = q;
} else {
parent[q] = p;
}
}
}
算法评论:
尼古拉斯·沃斯说过:算法+数据结构=程序
本人认为:算法是一种抽象的逻辑思维,而数据结构作为实现算法的描述基础,对于算法的衍生和实现起到了举足轻重的作用。合理的数据结构是优质算法的第一步,一定程度上左右着算法的走向,很是关键。
并查集的数据结构就是树。简单的数组却巧妙的描述了父子节点间的关系:数组下标为子节点,数组值为父节点。当父子节点不断联通,关系也变得复杂起来,比如某个节点是另一个节点七大姑八大姨的儿子的舅舅的姥爷的姥姥的侄子,你会想?What?!!但如果告诉你,追根溯源你们有相同的老祖宗,500年前是一家啊!是不是关系就清晰明了了。管他三七二十一,反正500年前是一家,都是亲戚。并查集所关注的正式这个源头。而树所包含的逻辑关系很好的描述了追根溯源这一流程。树的根节点就是源头,就是传说中的老祖宗!
算法应用:
应用一,先给大家热个身,玩个裁剪小游戏。问题不作描述,自己理解吧!
package unionFind;
import java.util.Scanner;
public class Successor {
private SelfUN un;
private boolean[] num;
public Successor(int n) {
un = new SelfUN(n);
num = new boolean[n];
for (int i = 0; i < n; i++) {
num[i] = false;//默认没有被裁剪掉。
}
}
public int getValue(int p) {
if(num[p]==false)return p;//没有被裁剪掉,则返回其本身。
//if(p==un.getCount())return p;
int root = un.find(p);
if (root == un.getCount())//数组的范围,也就是节点的范围是:0到n-1.这里count的值为n。
return -1;//最后一个节点被裁剪后,其返回的值为-1.
return un.find(p) + 1;//其余节点被裁剪后,其返回的值是当前节点链的最后一个节点的下一个节点。
}
public void remove(int p) {
if (num[p] == true)
return;//已被裁剪无需操作。
num[p] = true;//标注已被裁剪。
if (p!=0&&!un.connected(p - 1, p)&&num[p-1]==true) {//判别非第一节点的前一个节点是否亦被裁剪。
un.union(p - 1, p);//是的话,合并。
}
if ((p+1)!=un.getCount()&&!un.connected(p, p + 1)&&num[p+1]==true) {//判别非最后一个节点的后一个节点是否亦被裁剪掉。
un.union(p, p + 1);//是的话,合并。注意,这里并查集默认是将后一个节点作为根节点合并的。
}
}
public static void main(String args[]) {
Scanner sc = new Scanner(System.in);
System.out.println("Please input the parameter:");
int num = sc.nextInt();
Successor s = new Successor(num);
s.remove(1);
System.out.println(s.getValue(1));
System.out.println(s.getValue(0));
s.remove(2);
System.out.println(s.getValue(1));
s.remove(3);
System.out.println(s.getValue(1));
s.remove(4);
System.out.println(s.getValue(1));
sc.close();
}
}
应用二,Percolation,对的,就是上面提到过的,60分万岁,管道达到60%覆盖率上下边界流通。
使用并查集去追根溯源还是挺简单的,只需判断上下边界是否联通就ok啦!比如一个n*n+1的并查集,0和n*n+1分别代表上下边界,但在实现过程中存在一个问题:backwash,即回流。回流是啥呢?就是与底边界联通的,同时与上边界非联通的管道可能被误判为有水流注入,原因是并查集过程中的追根溯源过程只有一个老祖宗!!!我们将那些只与下边界联通的管道同那些与上下边界同时联通的管道一视同仁,追根同源。而实际情况是下边界是黑土地,上边界是大水池。仅仅同时联通黑土地的管道并没有任何关系。
想法一,使用两个并查集,一个判别是否同时与上下两个边界同时联通,另一个判别是否与上边界联通,而非回流照成的误判。
代码如下:
package unionFind;
import edu.princeton.cs.algs4.WeightedQuickUnionUF;
import edu.princeton.cs.algs4.StdOut;
//import edu.princeton.cs.algs4.StdIn;
public class Percolation1 {
private int count;
private WeightedQuickUnionUF un;//并查集,用于判别是否与上下边界同时联通。
private WeightedQuickUnionUF unTop;//并查集,仅用于判别是否与上边界联通。
private boolean[] tag;//标记,判别是否有铺设管道。
// private boolean isPercolates=false;
// private int row, col;
public Percolation1(int n) {//构造函数初始化。
if (n < 0)
throw new IllegalArgumentException("Illegal Argument!");
count = n;
un = new WeightedQuickUnionUF(n * n + 2);
unTop = new WeightedQuickUnionUF(n * n + 1);
tag = new boolean[n * n + 2];
tag[0] = true;
tag[n * n + 1] = true;
for (int i = 1; i < n * n + 1; i++) {
tag[i] = false;
}
tag[n * n + 1] = true;//用于上下边界联通判别,类比tag[0] = true.
}
public void validate(int p) {
if (p < 1 || p > count)
throw new IllegalArgumentException("Illegal Argument!");
}
public void open(int row, int col) {
validate(row);
validate(col);
int curIndex = (row - 1) * count + col;
if (tag[curIndex])
return;
tag[curIndex] = true;
if (row == 1) {
un.union(0, curIndex);
unTop.union(0, curIndex);//该并查集仅用于判别当前管道与上边界是否联通。
}
if (row == count) {//下边界与上边界此处处于等价关系、下边界类比上边界倒置情形。
un.union(count * count + 1, curIndex);
}
//当前铺设的管道与其四周的管道进行连接,放入同一个集合。
if (col - 1 >= 1 && tag[curIndex - 1]) {
un.union(curIndex, curIndex - 1);
unTop.union(curIndex, curIndex - 1);
}
if (col + 1 <= count && tag[curIndex + 1]) {
un.union(curIndex, curIndex + 1);
unTop.union(curIndex, curIndex + 1);
}
if (row - 1 >= 1 && tag[curIndex - count]) {
un.union(curIndex, curIndex - count);
unTop.union(curIndex, curIndex - count);
}
if (row + 1 <= count && tag[curIndex + count]) {
un.union(curIndex, curIndex + count);
unTop.union(curIndex, curIndex + count);
}
}
public boolean isOpen(int row, int col) {
int curIndex = (row - 1) * count + col;
return tag[curIndex];//是否有管道铺设的标记位。
}
public boolean isFull(int row, int col) {
int curIndex = (row - 1) * count + col;
if (un.connected(0, curIndex) && un.connected(count * count + 1, curIndex) && unTop.connected(0, curIndex)) {
return true;//是否为通水管道判别,unTop用于防止回流。
} else {
return false;
}
}
public int numberOfOpenSites() {
int calcu = 0;
for (int i = 1; i <= count * count; i++) {
if (tag[i] == true)
calcu++;//总的管道数目。
}
return calcu;
}
public boolean percolates() {
for (int i = 1; i <= count; i++) {
for (int j = 1; j <= count; j++) {
if (isOpen(i, j) && isFull(i, j)) {
return true;//遍历每一块黑土地,寻找通水管道,如果存在,则percolate.
}
}
}
return false;
}
public static void main(String[] args) {
Percolation1 p = new Percolation1(1);
p.open(1, 1);
//p.isOpen(1, 1);
//p.open(3, 7);
//StdOut.println(p.isOpen(1, 1));
//StdOut.println(p.isOpen(1, 2));
//StdOut.println(p.isFull(1, 1));
//p.open(2, 1);
StdOut.println(p.isFull(1, 1));
StdOut.println(p.percolates());
}
}
上述代码在percolates函数与isFull函数的编写上不够精简,下面对其进行修改,这里不作解释,请自行体会!
package unionFind;
import edu.princeton.cs.algs4.WeightedQuickUnionUF;
import edu.princeton.cs.algs4.StdOut;
public class Percolation2 {
private int curOpen = 0;
private final int count;
private final WeightedQuickUnionUF unTop;
private final WeightedQuickUnionUF un;
private boolean[] tag;
public Percolation2(int n) {
if (n < 1) {
throw new IllegalArgumentException("Illegal Argument!");
}
count = n;
unTop = new WeightedQuickUnionUF(n * n + 1);
un = new WeightedQuickUnionUF(n * n + 2);
tag = new boolean[n * n + 2];
tag[0] = true;
tag[n * n + 1] = true;
for (int i = 1; i < n * n + 1; i++) {
tag[i] = false;
}
tag[n * n + 1] = true;
}
private void validate(int p) {
if (p < 1 || p > count) {
throw new IllegalArgumentException("Illegal Argument!");
}
}
public void open(int row, int col) {
validate(row);
validate(col);
int curIndex = (row - 1) * count + col;
if (tag[curIndex])
return;
curOpen++;
tag[curIndex] = true;
if (row == 1) {
unTop.union(0, curIndex);
un.union(0, curIndex);
}
if (row == count) {
un.union(count * count + 1, curIndex);
}
if (col - 1 >= 1 && tag[curIndex - 1]) {
unTop.union(curIndex, curIndex - 1);
un.union(curIndex, curIndex - 1);
}
if (col + 1 <= count && tag[curIndex + 1]) {
unTop.union(curIndex, curIndex + 1);
un.union(curIndex, curIndex + 1);
}
if (row - 1 >= 1 && tag[curIndex - count]) {
unTop.union(curIndex, curIndex - count);
un.union(curIndex, curIndex - count);
}
if (row + 1 <= count && tag[curIndex + count]) {
unTop.union(curIndex, curIndex + count);
un.union(curIndex, curIndex + count);
}
}
public boolean isOpen(int row, int col) {
validate(row);
validate(col);
int curIndex = (row - 1) * count + col;
return tag[curIndex];
}
public boolean isFull(int row, int col) {
validate(row);
validate(col);
int curIndex = (row - 1) * count + col;
if (unTop.connected(0, curIndex)) {
return true;
}
return false;
}
public int numberOfOpenSites() {
return curOpen;
}
public boolean percolates() {
if (numberOfOpenSites() < count) {
return false;
}
if (un.connected(0, count * count + 1)) {
return true;
}
return false;
}
public static void main(String[] args) {
Percolation2 p = new Percolation2(1);
p.open(1, 1);
StdOut.println(p.isFull(1, 1));
StdOut.println(p.percolates());
}
}
想法二,可不可以只用一个并查集呢?进而节省空间和提升效率。答案是:当然可以!
package unionFind;
import edu.princeton.cs.algs4.WeightedQuickUnionUF;
import edu.princeton.cs.algs4.StdOut;
public class Percolation {
private int curOpen = 0;
private final int count;
private final WeightedQuickUnionUF un;
private byte[] tag;
// 之前的boolean类型的标记位只能描述两种状态,即管道与黑土。而通水管道是用un.union(0, curIndex)判别的。
// 我们应该注意到,之所以造成回流的原因是我们运用了不恰当的数据结构来描述与底部边界联接的管道。// 它不是一棵树。所以我们完全可以仅仅是增添标记去单独标明那些与底部边界相连的管道。
//这里我们将其设置为tag[curIndex]=2来表示。
public Percolation(int n) {// n是整个黑土地的边长,默认是一个方形。if (n < 1) {
throw new IllegalArgumentException("Illegal Argument!");
}
count = n;
un = new WeightedQuickUnionUF(n * n + 1);
tag = new byte[n * n + 1];
tag[0] = 1;// 1表示通水管道。
for (int i = 1; i < n * n + 1; i++) {
tag[i] = 0;// 0表示黑土地。
}
}
private void validate(int p) {
if (p < 1 || p > count) {
throw new IllegalArgumentException("Illegal Argument!");
}
}
public void open(int row, int col) {
validate(row);
validate(col);
int curIndex = (row - 1) * count + col;
if (tag[curIndex] > 0)
return;
curOpen++;// 记录管道个数。
tag[curIndex] = 1;
if (row == 1) {
un.union(0, curIndex);
}
if (count == 1) {// 仅有一块黑土地铺设一块管道的情形,也是percolates的。
tag[un.find(0)] = 2;// 仅有一块的情形是与底部联通的。
return;
}
if (row == count) {// 最后一行铺设的管道,与大地边界联通,标记为2.
tag[curIndex] = 2;
}
if (col - 1 >= 1 && tag[curIndex - 1] > 0) {// 当前管道左边有管道。
if (tag[un.find(curIndex - 1)] == 2 || tag[un.find(curIndex)] == 2) {
un.union(curIndex, curIndex - 1);
tag[un.find(curIndex)] = 2;// 合并后的根节点也标注为2.
// 这里我们应该意识到,我们并不是将每一个与底部联通的管道都标注为2.而是用仅仅标注其根节点来描述整棵树上的节点都是与底部联通的。
} else {
un.union(curIndex, curIndex - 1);
}
}
if (col + 1 <= count && tag[curIndex + 1] > 0) {// 当前管道的右边有管道。
if (tag[un.find(curIndex + 1)] == 2 || tag[un.find(curIndex)] == 2) {
un.union(curIndex, curIndex + 1);
tag[un.find(curIndex)] = 2;
} else {
un.union(curIndex, curIndex + 1);
}
}
if (row - 1 >= 1 && tag[curIndex - count] > 0) {// 当前管道的上边有管道。
if (tag[un.find(curIndex - count)] == 2 || tag[un.find(curIndex)] == 2) {
un.union(curIndex, curIndex - count);
tag[un.find(curIndex)] = 2;
} else {
un.union(curIndex, curIndex - count);
}
}
if (row + 1 <= count && tag[curIndex + count] > 0) {// 当前管道的下边有管道。
if (tag[un.find(curIndex + count)] == 2 || tag[un.find(curIndex)] == 2) {
un.union(curIndex, curIndex + count);
tag[un.find(curIndex)] = 2;
} else {
un.union(curIndex, curIndex + count);
}
}
}
public boolean isOpen(int row, int col) {
validate(row);
validate(col);
return tag[(row - 1) * count + col] > 0;// 判别是管道还是黑土。
}
public boolean isFull(int row, int col) {
validate(row);
validate(col);
if (isOpen(row, col) && un.connected(0, (row - 1) * count + col)) {// 判别是否是通水管道。
return true;
}
return false;
}
public int numberOfOpenSites() {
return curOpen;// 返回管道数目。
}
public boolean percolates() {
if (numberOfOpenSites() < count) {// 如果铺设的管道小于整个黑土地的边长,那么percolates是不可能的。
return false;
}
return tag[un.find(0)] == 2;// 与上边界联通且与下边界联通。
}
public static void main(String[] args) {
Percolation p = new Percolation(2);
p.open(1, 1);
p.open(2, 1);
StdOut.println(p.isFull(1, 1));
StdOut.println(p.percolates());
}
}
后面的课程请参见:https://blog.csdn.net/GZHarryAnonymous/article/details/80398106