bn一般就在conv之后并且后面再接relu
1.如果输入feature map channel是6,bn的gamma beta个数是多少个?
6个。
2.bn的缺点:
BN会受到batchsize大小的影响。如果batchsize太小,算出的均值和方差就会不准确,如果太大,显存又可能不够用。
3.训练和测试时一般不一样,一般都是训练的时候在训练集上通过滑动平均预先计算好平均-mean,和方差-variance参数,在测试的时候,不再计算这些值,而是直接调用这些预计算好的来用,但是,当训练数据和测试数据分布有差别是时,训练机上预计算好的数据并不能代表测试数据,这就导致在训练,验证,测试这三个阶段存inconsistency
4.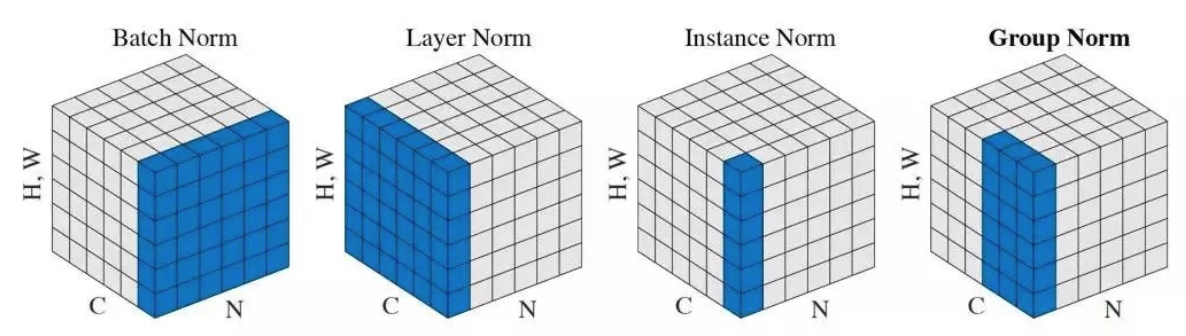
batch norm:在一个batch里所有样本的feature map的同一个channel上进行norm,归一化维度为[N,H,W]
layer norm:在每个样本所有的channel上进行norm,归一化的维度为[C,H,W]
instance norm:在每个样本每个channel上进行norm,归一化的维度为[H,W]
group norm:将channel方向分group,然后每个group内做归一化,算(C//G)*H*W的均值,GN的极端情况就是LN和I N
GG 表示分组的数量, 是一个预定义的超参数(一般选择 G=32G=32). C/GC/G 是每个组的通道数, 第二个等式条件表示对处于同一组的像素计算均值和标准差. 最终得到的形状为 N×(C/G)
延伸问题:这个group norm怎么去求?
http://www.dataguru.cn/article-13318-1.html
https://blog.csdn.net/qq_14845119/article/details/79702040