anaconda -4.5.11
python-3.6.5
scikit-learn-0.19.1
%matplotlib inline import matplotlib.pyplot as plt import pandas as pd from sklearn.datasets.california_housing import fetch_california_housing #内置数据集 housing = fetch_california_housing() print(housing.DESCR)
California housing dataset.
The original database is available from StatLib
http://lib.stat.cmu.edu/datasets/
The data contains 20,640 observations on 9 variables.
This dataset contains the average house value as target variable
and the following input variables (features): average income,
housing average age, average rooms, average bedrooms, population,
average occupation, latitude, and longitude in that order.
References
----------
Pace, R. Kelley and Ronald Barry, Sparse Spatial Autoregressions,
Statistics and Probability Letters, 33 (1997) 291-297.
housing.data.shape
(20640, 8)
housing.data[0]
array([ 8.3252 , 41. , 6.98412698, 1.02380952,
322. , 2.55555556, 37.88 , -122.23 ])
from sklearn import tree dtr = tree.DecisionTreeRegressor(max_depth = 2) #树的最大深度 = 2 dtr.fit(housing.data[:, [6, 7]], housing.target)#fit(X,Y) ''' 0-average income, 1-housing average age, 2-average rooms, 3-average bedrooms, 4-population, 5-average occupation, 6-latitude, and 7-longitude '''
'\n0-average income,\n1-housing average age, 2-average rooms, 3-average bedrooms, 4-population,\n5-average occupation, 6-latitude, and 7-longitude\n
#要可视化显示 首先需要安装 graphviz http://www.graphviz.org/Download..php #也可以在cmd界面输入conda install python-graphviz来安装graphviz。 #环境变量GRAPHVIZ_DOT,变量值:D:\ProgramData\Anaconda3\pkgs\graphviz-2.38-hfd603c8_2\Library\bin #重启notebook dot_data = \ tree.export_graphviz( dtr, out_file = None, feature_names = housing.feature_names[6:8], filled = True, impurity = False, rounded = True ) #pip install pydotplus 在Anaconda Prompt中 #conda install -c conda-forge pydotplus import pydotplus graph = pydotplus.graph_from_dot_data(dot_data) graph.get_nodes()[7].set_fillcolor("#FFF2DD") from IPython.display import Image Image(graph.create_png())
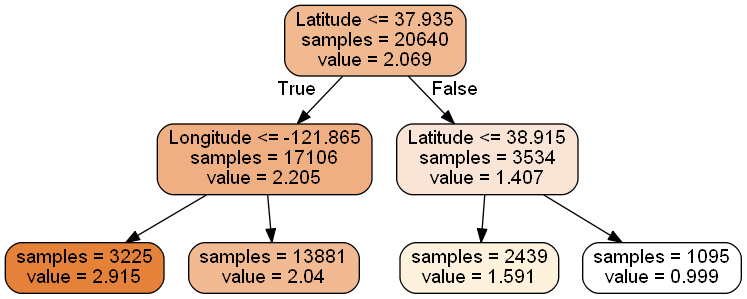
graph.write_png("dtr_white_background.png")
True
from sklearn.model_selection import train_test_split #分割数据集 data_train, data_test, target_train, target_test = \ #X训练集,X测试集,Y训练集,Y测试集 train_test_split(housing.data, housing.target, test_size = 0.1, random_state = 42) #X,Y,验证集大小,随机状态 dtr = tree.DecisionTreeRegressor(random_state = 42) #构造树模型 dtr.fit(data_train, target_train) dtr.score(data_test, target_test)
0.637318351331017
from sklearn.ensemble import RandomForestRegressor #导入随机森林 rfr = RandomForestRegressor( random_state = 42)#构造随机森林 rfr.fit(data_train, target_train) rfr.score(data_test, target_test)
0.7908649228096493
## 树模型参数:
- 1.criterion gini or entropy --------gini系数或者熵值
- 2.splitter best or random 前者是在所有特征中找最好的切分点 后者是在部分特征中(数据量大的时候)
- 3.max_features None(所有),log2,sqrt,N 特征小于50的时候一般使用所有的
- 4.★max_depth 数据少或者特征少的时候可以不管这个值,如果模型样本量多,特征也多的情况下,可以尝试限制下
- 5.★min_samples_split 如果某节点的样本数少于min_samples_split,则不会继续再尝试选择最优特征来进行划分如果样本量不大,不需要管这个值。如果样本量数量级非常大,则推荐增大这个值。
- 6.min_samples_leaf 这个值限制了叶子节点最少的样本数,如果某叶子节点数目小于样本数,则会和兄弟节点一起被剪枝,如果样本量不大,不需要管这个值,大些如10W可是尝试下5
- 7.min_weight_fraction_leaf 这个值限制了叶子节点所有样本权重和的最小值,如果小于这个值,则会和兄弟节点一起被剪枝默认是0,就是不考虑权重问题。一般来说,如果我们有较多样本有缺失值,或者分类树样本的分布类别偏差很大,就会引入样本权重,这时我们就要注意这个值了。
- 8.max_leaf_nodes 通过限制最大叶子节点数,可以防止过拟合,默认是"None”,即不限制最大的叶子节点数。如果加了限制,算法会建立在最大叶子节点数内最优的决策树。如果特征不多,可以不考虑这个值,但是如果特征分成多的话,可以加以限制具体的值可以通过交叉验证得到。
- 9.class_weight 指定样本各类别的的权重,主要是为了防止训练集某些类别的样本过多导致训练的决策树过于偏向这些类别。这里可以自己指定各个样本的权重如果使用“balanced”,则算法会自己计算权重,样本量少的类别所对应的样本权重会高。
- 10.min_impurity_split 这个值限制了决策树的增长,如果某节点的不纯度(基尼系数,信息增益,均方差,绝对差)小于这个阈值则该节点不再生成子节点。即为叶子节点 。
- n_estimators:要建立树的个数
from sklearn.model_selection import GridSearchCV #参数遍历选择 tree_param_grid = { 'min_samples_split': list((3,6,9)),'n_estimators':list((10,50,100))} grid = GridSearchCV(RandomForestRegressor(),param_grid=tree_param_grid, cv=5) #随机算法,参数{字典},交叉验证次数 grid.fit(data_train, target_train) grid.grid_scores_, grid.best_params_, grid.best_score_
([mean: 0.78535, std: 0.00380, params: {'min_samples_split': 3, 'n_estimators': 10},
mean: 0.80483, std: 0.00380, params: {'min_samples_split': 3, 'n_estimators': 50},
mean: 0.80705, std: 0.00304, params: {'min_samples_split': 3, 'n_estimators': 100},
mean: 0.78597, std: 0.00699, params: {'min_samples_split': 6, 'n_estimators': 10},
mean: 0.80423, std: 0.00341, params: {'min_samples_split': 6, 'n_estimators': 50},
mean: 0.80712, std: 0.00364, params: {'min_samples_split': 6, 'n_estimators': 100},
mean: 0.78733, std: 0.00347, params: {'min_samples_split': 9, 'n_estimators': 10},
mean: 0.80468, std: 0.00423, params: {'min_samples_split': 9, 'n_estimators': 50},
mean: 0.80661, std: 0.00400, params: {'min_samples_split': 9, 'n_estimators': 100}],
{'min_samples_split': 6, 'n_estimators': 100},
0.8071216491267976)
rfr = RandomForestRegressor( min_samples_split=3,n_estimators = 100,random_state = 42)
rfr.fit(data_train, target_train)
rfr.score(data_test, target_test)
0.8090829049653158
pd.Series(rfr.feature_importances_, index = housing.feature_names).sort_values(ascending = False)
MedInc 0.524257 AveOccup 0.137947 Latitude 0.090622 Longitude 0.089414 HouseAge 0.053970 AveRooms 0.044443 Population 0.030263 AveBedrms 0.029084 dtype: float64