布隆过滤器(Bloom Filter):是位图的扩展。
对于位图的话,对于判断整形数据存在不存在的话,是非常的方便的,但是对于字符串就显得难以解决掉的,这个时候就出现了布隆过滤器。
对于数据的话,除了整形数据的话也就是字符串的数据了,而布隆过滤器就是处理如何判断一个字符串是如何存在的。
方法:对于字符串的话,还是采用位图的方式来储存,那这就出现了一个问题,如何将字符串储存到位图中呢,这就牵扯到要将字符串转化为一个整形数据。
大家可以看下一个大佬总结出来:http://www.cnblogs.com/-clq/archive/2012/05/31/2528153.html
大家可以点进去看一下。
而对于位图的话,仅仅存放到位图的一个位置,那是会产生错误的。因为对于字符串的话就有可能,多个字符串标记在一个位图的空间,这样就会出现问题,所以一般对于一个字符串的话都会采用多个hash函数将字符串转化为位图的存储地址,这样的话就不会害怕出现冲突了。
比如:对于字符串“sport”和“delete”来说,我们采用用三个hash函数,我大概画一个图来看一下
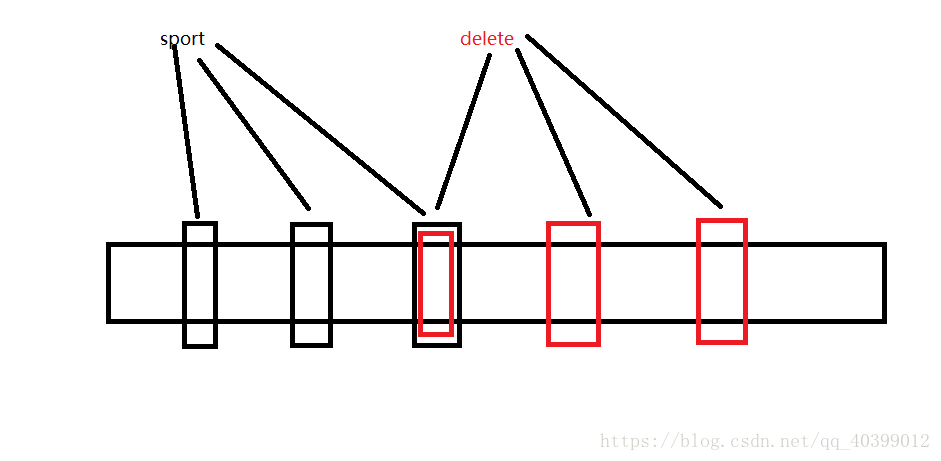
对于“sport”,其在位图中的存储如图有三个位置,但是对于“delete”也有三个,但是有一个位置与“sort”重复了。
但是这并不影响到我们判断“sport”或“delete”是否存在。
因为我们采用三个hash函数的话,判断存在的话,就要判断三个位置是否都存在,而不是只判断一个,这样就不会出现,如果字符串冲突的话,我们到导致判断错误。
如果害怕三个hash函数,判断依旧有可能出错的话,那就可以采用五个甚至十个hash函数,这样出错的可能性就会极小极小。
但是对于这种办法我们只可,向里面存放数据,而不可以删除数据,因为删除的话,就要将多个hash函数找到的位置都进行删除,这样就有可能导致如果有重复的话,就会把其他的字符串所得到的hash位置也进行删除了。所以一定要记住:不可以删除
接下来看一下代码:
//数据结构
//在里面放置一个位图,只不过每次求多个hash地址
typedef struct BloomFilter
{
bitset _bs;
}BloomFilter;
//操作
size_t HashFunc1(const char* str)
{
assert(str);
size_t hash = 0;
while (*str)
{
hash = hash * 131 + (size_t)*str;
str++;
}
return hash;
}
size_t HashFunc2(const char* str)
{
assert(str);
size_t hash = 0;
while (*str)
{
hash = hash * 31 + (size_t)*str;
str++;
}
return hash;
}
size_t HashFunc3(const char* str)
{
assert(str);
size_t hash = 0;
while (*str)
{
hash = hash * 1313 + (size_t)*str;
str++;
}
return hash;
}
void BloomFilterInit(BloomFilter* pbf, size_t n)
{
assert(pbf);
BitSetInit(&(pbf->_bs), n);
}
void BloomFilterDestory(BloomFilter* pbf)
{
assert(pbf);
BitSetDestory(&(pbf->_bs));
}
void BloomFilterSet(BloomFilter* pbf, const char* str)
{
assert(pbf);
size_t index1 = HashFunc1(str) % 20;
size_t index2 = HashFunc2(str) % 20;
size_t index3 = HashFunc3(str) % 20;
BitSetSet(&(pbf->_bs), index1);
BitSetSet(&(pbf->_bs), index2);
BitSetSet(&(pbf->_bs), index3);
}
//存在 1
//不存在 0
int BloomFilterCheck(BloomFilter* pbf, const char* str)
{
assert(pbf);
size_t index1 = HashFunc1(str) % 20;
if (BitSetCheck(&(pbf->_bs), index1))
{
size_t index2 = HashFunc2(str) % 20;
if (BitSetCheck(&(pbf->_bs), index2))
{
size_t index3 = HashFunc3(str) % 20;
if (BitSetCheck(&(pbf->_bs), index3))
{
return 1;
}
}
}
return 0;
}对于布隆过滤器,里面出现的函数可以参考上一篇博客:
https://blog.csdn.net/qq_40399012/article/details/82598205