目录
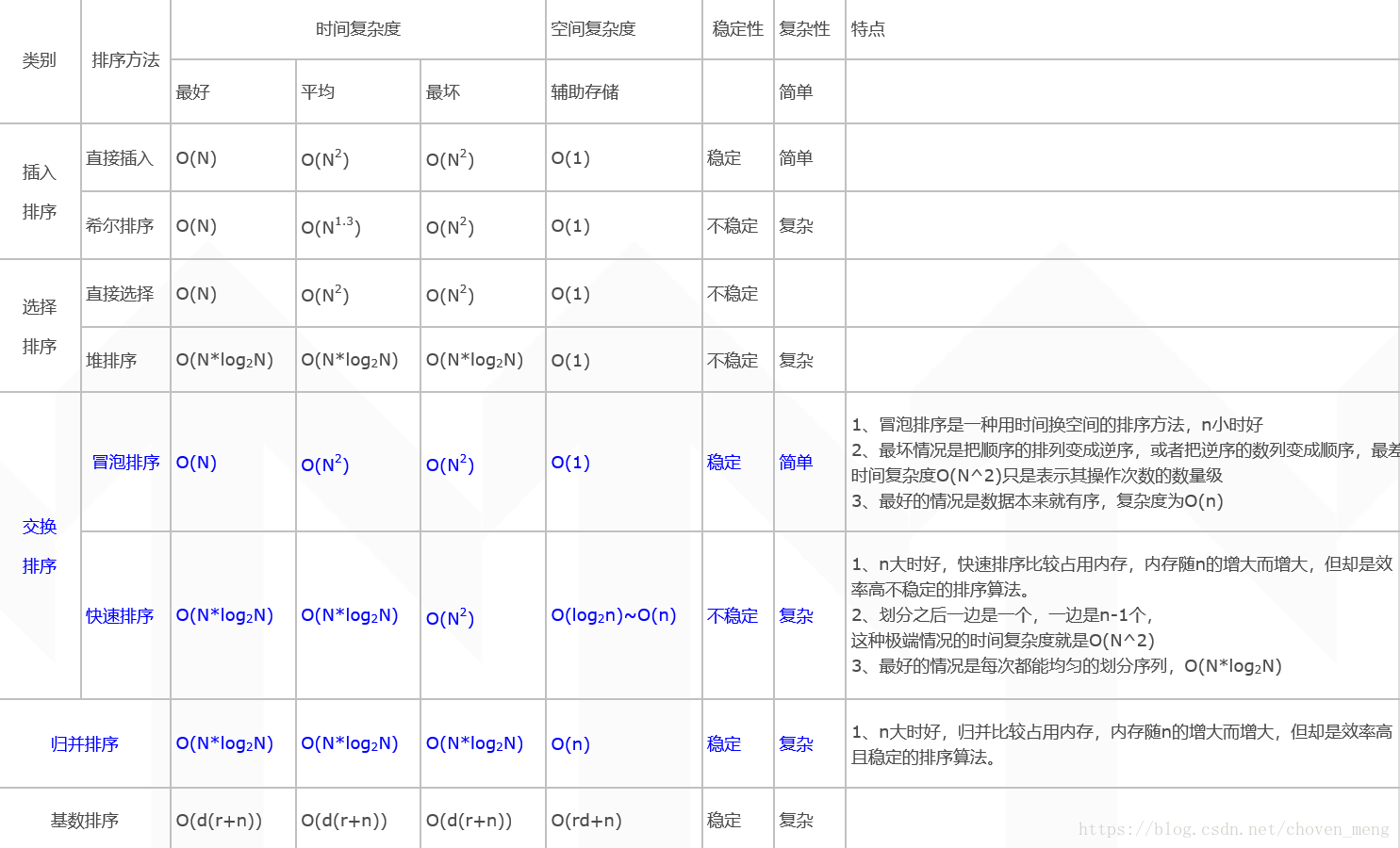
一、常用排序算法
二、正负样本不平衡处理方法总结
原始数据中经常存在正负样本不均衡,比如正负样本的数据比例为100:1.
常用的解决办法有:

1、采样
采样方法是通过对训练集进行处理使其从不平衡的数据集变成平衡的数据集,在大部分情况下会对最终的结果带来提升。
采样分为上采样(Over-sampling)和下采样(Under-sampling),上采样是把小众类复制多份,下采样是从大众类中剔除一些样本,或者说只从大众类中选取部分样本。
缺点:
上采样后的数据集中会反复出现一些样本,训练出来的模型会有一定的过拟合;而下采样的缺点显而易见,那就是最终的训练集丢失了数据,模型只学到了总体模式的一部分。
解决办法:
(1)对于上采样,每次生成新数据点时加入轻微的随机扰动,经验表明这种做法非常有效。
(2)对于下采样,第一种方法叫做EasyEnsemble,利用模型融合的方法(Ensemble):多次下采样(放回采样,这样产生的训练集才相互独立)产生多个不同的训练集,进而训练多个不同的分类器,通过组合多个分类器的结果得到最终的结果。第二种方法叫做BalanceCascade,利用增量训练的思想(Boosting):先通过一次下采样产生训练集,训练一个分类器,对于那些分类正确的大众样本不放回,然后对这个更小的大众样本下采样产生训练集,训练第二个分类器,以此类推,最终组合所有分类器的结果得到最终结果。第三种方法是利用KNN试图挑选那些最具代表性的大众样本,叫做NearMiss,这类方法计算量很大。
2、样本合成 Synthetic Sample
合成样本是为了增加样本数目较少的那一类样本,合成指的是通过组合以有的样本的各个feature从而产生新的样本。
一种简单的方法是从各个feature中随机算出一个已有值,然后拼接成一个新样本,这种方法增加了样本数目较少的那一类样本的数目,作用与上采样方法类似,不同点在于上采样是纯粹的复制样本,而合成样本是随机选取拼接得到新的样本。具有代表性的方法 是SMOTE.
3、改变样本的权重
改变样本权重指的是增大样本数较少类别的样本的权重,当类别较少的样本被误分时,其损失值要乘以相应的权重,从而让分类器更加关注这一类数据较少的样本。
4、一分类
对于正负样本极不平衡的场景,我们可以换一个完全不同的角度来看待问题:把它看做一分类(One Class Learning)或异常检测(Novelty Detection)问题。这类方法的重点不在于捕捉类间的差别,而是为其中一类进行建模,经典的工作包括One-class SVM等。
三、过拟合和欠拟合
1、过拟合
过拟合是模型在训练集上的表现很好,在测试集上的变现却很差。出现这种现象的主要原因是训练数据集中存在噪音、训练数据太少、特征选择的过多导致模型复杂度高、模型拟合了数据中噪声和训练样例中没有代表性的特征。
(1)、Early stopping
Early stopping便是一种迭代次数截断的方法来防止过拟合的方法,即在模型对训练数据集迭代收敛之前停止迭代来防止过拟合。对模型进行训练的过程即是对模型的参数进行学习更新的过程,这个参数学习的过程往往会用到一些迭代方法,如梯度下降(Gradient descent)学习算法。这样可以有效阻止过拟合的发生,因为过拟合本质上就是对自身特点过度地学习。
(2)、正则化
指的是在目标函数后面添加一个正则化项,一般有L1正则化与L2正则化。L1正则是基于L1范数,即在目标函数后面加上参数的L1范数和项,即参数绝对值和与参数的积项。
L2正则是基于L2范数,即在目标函数后面加上参数的L2范数和项,即参数的平方和与参数的积项。
L1正则与L2正则区别:
L1:计算绝对值之和,用以产生稀疏性(使参数矩阵中大部分元素变为0),因为它是L0范式的一个最优凸近似,容易优化求解;广泛的用于特征选择机制
L2:计算平方和再开根号,L2范数更多是防止过拟合,并且让优化求解变得稳定快速;L2的目标是衰减权重,使权重更加接近原点1.
所以对于防止过拟合优先使用L2 是比较好的选择。
(3)、数据集扩增
通俗得讲,数据集扩增即需要得到更多的符合要求的数据,即和已有的数据是独立同分布的,或者近似独立同分布的。一般有以下方法:从数据源头采集更多数据、复制原有数据并加上随机噪声、重采样、根据当前数据集估计数据分布参数,使用该分布产生更多数据等。
(4)、dropout
对于神经网络,在训练开始时,随机删除一些(可以设定为一半,也可以为1/3,1/4等)隐藏层神经元,即认为这些神经元不存在,同时保持输入层与输出层神经元的个数不变。这样一次迭代更新便完成了。下一次迭代中,同样随机删除一些神经元,与上次不一样,做随机选择。这样一直进行瑕疵,直至训练结束。
2、欠拟合
- (1)增加新特征,可以考虑加入进特征组合、高次特征,来增大假设空间;“组合”、“泛化”、“相关性”三类特征是特征添加的重要手段,无论在什么场景,都可以照葫芦画瓢,总会得到意想不到的效果。除上面的特征之外,“上下文特征”、“平台特征”等等,都可以作为特征添加的首选项。
- (2)添加多项式特征,这个在机器学习算法里面用的很普遍,例如将线性模型通过添加二次项或者三次项使模型泛化能力更强;
- (3)减少正则化参数,正则化的目的是用来防止过拟合的,但是模型出现了欠拟合,则需要减少正则化参数;
- (4)使用非线性模型,比如核SVM 、决策树、深度学习等模型;
- (5)调整模型的容量(capacity),通俗地,模型的容量是指其拟合各种函数的能力。
- (6)容量低的模型可能很难拟合训练集;使用集成学习方法,如Bagging ,将多个弱学习器Bagging
- 在决策树学习中扩展分支,在神经网络学习中增加训练轮数。
四、向量的相似度计算常用方法
在数据分析和数据挖掘以及搜索引擎、个性化推荐等场景中,我们经常需要知道个体间差异的大小,进而评价个体的相似性和类别。常见的比如数据分析中的相关分析,数据挖掘中的分类聚类(K-Means等)算法,搜索引擎进行物品推荐时。
相似度就是比较两个事物的相似性。一般通过计算事物的特征之间的距离,如果距离小,那么相似度大;如果距离大,那么相似度小。
常用的计算相似性的方法有:
欧氏距离是最常用的距离计算公式,衡量的是多维空间中各个点之间的绝对距离,当数据很稠密并且连续时,这是一种很好的计算方式。
因为计算是基于各维度特征的绝对数值,所以欧氏度量需要保证各维度指标在相同的刻度级别,比如对身高(cm)和体重(kg)两个单位不同的指标使用欧式距离可能使结果失效。
from math import *
def Eucledian(x,y):
return sqrt(sum(pow(a-b,2) for a, b in zip(x,y)))2、曼哈顿距离(Manhattan Distance)
曼哈顿距离的实现同欧氏距离类似,都是用于多维数据空间距离的度量。距离越小,相似度越大。
def Manhattan(x,y):
return sum(abs(a - b) for a, b in zip(x,y))3、明可夫斯基距离(Minkowski distance)
明氏距离是欧氏距离的推广,是对多个距离度量公式的概括性的表述。
从公式我们可以看出,
- 当p==1,“明可夫斯基距离”变成“曼哈顿距离”
- 当p==2,“明可夫斯基距离”变成“欧几里得距离”
- 当p==∞,“明可夫斯基距离”变成“切比雪夫距离”
def Minkowski(x,y,p):
sumValue = sum(pow(abs(a-b),p) for a, b in zip(x,y))
mi = 1/float(p)
return round(sumValue**mi, 3) # 保留3位小数4、余弦相似度(Cosine Similarity)
余弦相似度用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小。相比距离度量,余弦相似度更加注重两个向量在方向上的差异,而非距离或长度上。
import numpy as np
def cosine(x,y):
num = np.sum(x*y)
denom = np.linalg.norm(x)*np.linalg.norm(y)
return round(num/denom,3)
print(cosine(np.array([3,45,7,2]),np.array([2,53,15,75])))
# output:0.6225、杰卡德相似度Jaccard Similarity
jaccard系数主要用于计算符号度量或布尔值度量的个体间的相似度,因为个体的特征属性都是由符号度量或者布尔值标识,因此无法衡量差异具体值的大小,只能获得“是否相同”这个结果,所以Jaccard系数只关心个体间共同具有的特征是否一致这个问题。
import numpy as np
def jaccard(x,y):
intersection_cardinality = len(set.intersection(*[set(x),set(y)]))
union_cardinality = len(set.union(*[set(x),set(y)]))
return intersection_cardinality / union_cardinality
print(jaccard([1,2,3,1,2,3],[3,4,5,3,4,5]))
#output:0.26、皮尔森相关系数(Pearson Correlation Coefficient)
又称相关相似性,通过Pearson相关系数来度量两个用户的相似性。计算时,首先找到两个用户共同评分过的项目集,然后计算这两个向量的相关系数。一般用于 计算两个定距变量间联系的紧密程度。用来反应两个变量线性相关程度的统计量,取值在[-1,1]之间,绝对值越大,表明相关性越强,负相关对于推荐的意义小。
五、模型参数和超参数
1、模型参数
模型参数是模型内部的配置变量,可以用数据估计模型参数的值。
模型参数具有以下特征:进行模型预测时需要模型参数;模型参数值可以定义模型功能;模型参数用数据估计或数据学习得到;模型参数一般不由实践者手动设置。
通常使用优化算法估计模型参数,优化算法是对参数的可能值进行的一种有效搜索。
模型参数的一些例子包括:人造神经网络的权重;支持向量机中的支持向量;线性回归或逻辑回归中的系数。
2、模型超参数
模型超参数是模型外部的配置,其值不能从数据估计中得到,必须手动设置参数的值。
具体特征有:模型超参数常应用于估计模型参数的过程中;模型超参数通常由实践者直接指定;模型超参数通常可以使用启发式方法来设置;模型超参数通常根据给定的预测模型问题而调整。
怎么得到最优值:对于给定的问题,我们无法知道模型超参数的最优值,但我们可以使用经验法则来探寻其最优值,或复制用于其他问题的值,也可以通过反复试验的方法。
模型超参数的一些列子包括:训练神经网络的学习率;支持向量机的C和sigma超参数;k邻域中的k。