目录
一、关联挖掘的定义
关联挖掘定义为根据事务中其他项的出现情况预测其他项出现的概率。
其输入一般为:
(1)事务数据库
(2)支持度、置信度
输出为:所有表示共同出现项的规则。
二、关联规则
2.1规则的定义
如下表达式X->Y,X、Y是项集(itemsets)。如下图事务数据库:

则关联规则为:{Milk,Diaper}->{Beer}。
2.2评估规则的度量
- 支持度(s):事务中包含X和Y的比率。
- 置信度(c):Y出现在包含X的事务中的比率。
对于上述的事务数据库,我们计算关联规则{Milk,Diaper}->{Beer}的支持度和置信度:
三、频繁项集
3.1项集
一个或多个项的集合。
k-itemset即代表包含k个项的项集。
3.2支持度计数(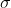 )
)
即项目集出现的频率次数,比如:
3.3支持度
即项目集出现的比例,比如:
3.4频繁项集
即支持度大于或者等于minsup的项集
对于给定事务集T,关联规则挖掘的任务转换为找出所有满足以下条件的规则:
四、频繁项集产生算法
对于一个大小为d的集合,通过下图可知一共有2^d个候选项集:

需要对每一个候选的项集进行支持度计算,然后确定频繁项集,
这种方式计算效率非常低!!!
4.1 Apriori算法
Apriori算法是根据Apriori原理进行设计的,
Apriori原理如下:
- 如果一个项集时频繁的,那么它的所有子集都是频繁的
- 并且有反单调性性质,即项集的支持度不大于其子集的支持度
- 用数学公式表达为:
- 用数学公式表达为:
比如在计算上述候选的项集支持度时,如果发现项集{AE}为非频繁集,
那么包含{AE}的项集都不用计算,一定都为非频繁集。

我们用如下事务集为例演示如何使用Apriori算法生成频繁项集:
| Tid | Items |
| 10 | A,C,D |
| 20 | B,C,E |
| 30 | A,B,C,E |
| 40 | B,E |
其中SUPmin=2,即项集的支持度计数大于等于2时才算频繁项集。
接下来我们对事务集进行第一次扫描,得到项集大小为1的项集C1,
| Itemset | sup |
| {A} | 2 |
| {B} | 3 |
| {C} | 3 |
| {D} | 1 |
| {E} | 3 |
去除支持度计数小于2的项集{D},得到频繁项集表L1,
| Itemset | sup |
| {A} | 2 |
| {B} | 3 |
| {C} | 3 |
| {E} | 3 |
由表L1生成大小为2的项集,计算它们的支持度得表C2,
| Itemset | sup |
| {A,B} | 1 |
| {A,C} | 2 |
| {A,E} | 1 |
| {B,C} | 2 |
| {B,E} | 3 |
| {C,E} | 2 |
去除支持度计数小于2的项集{A,B}和{A,E},得到频繁项集表L2,
| Itemset | sup |
| {A,C} | 2 |
| {B,C} | 2 |
| {B,E} | 3 |
| {C,E} | 2 |
由表L2生成大小为3的项集,计算它们的支持度得表C3,
| Itemset | sup |
| {B,C,E} | 2 |
由此就可以得到不同大小的频繁项集。
4.2 FP-Growth
FP-Growth则是从树的方向对该问题进行了解决,其将事务数据库压缩为一个树结构,通过FP-树得到频繁项集。
我们通过以下事务集对如何生成FP-树进行说明:
首先我们将1-itemset进行频率计数,得到频率计数顺序f-list=I2,I1,I3,I4,I5,
然后将数据库的项集Items中的元素按照这个顺序重新排列得到(ordered)FI列,
并且去除其中低于min_support=2的元素,
| Tid | Items | (ordered)FI |
| 100 | {I1,I2,I5,I6} | {I2,I1,I5} |
| 200 | {I2,I4} | {I2,I4} |
| 300 | {I2,I3} | {I2,I3} |
| 400 | {I1,I2,I4} | {I2,I1,I4} |
| 500 | {I1,I3,I7} | {I1,I3} |
| 600 | {I2,I3} | {I2,I3} |
| 700 | {I1,I3} | {I1,I3} |
| 800 | {I1,I2,I3,I5} | {I2,I1,I3,I5} |
| 900 | {I1,I2,I3} | {I2,I1,I3} |
然后根据得到的(ordered)FI信息按行依次生成FP-tree,其生成的步骤如下:

得到我们最终生成好的FP-tree后,分别对I1、I2、I3、I4、I5元素进行后缀搜索,

我们以I5为例,以I5为后缀的路径有I2->I1->I5和I2->I2->I3->I5,然后对除了I5外的元素进行计数,得到大于min_support的头元素表:
| Item | frequency |
| I2 | 2 |
| I1 | 2 |
然后根据该表生成FP-tree,得到如下结构FP-tree:

然后将I5放在对应结点后,得到频繁集序列:
- {I2,I5:2}
- {I1,I5:2}
- {I2,I1,I5:2}
以此类推,得到所有节点的后缀频繁集序列(I2为前没有结点,所以不用计算后缀频繁集序列):
| Item | Frequent Patterns Generated |
| I1 | {I2,I1:4} |
| I3 | {I1,I3:4} {I2,I1,I3:2} {I2,I3:4} |
| I4 | {I2,I4:2} |
| I5 | {I1,I5:2} {I2,I1,I5:2} {I2,I5:2} |